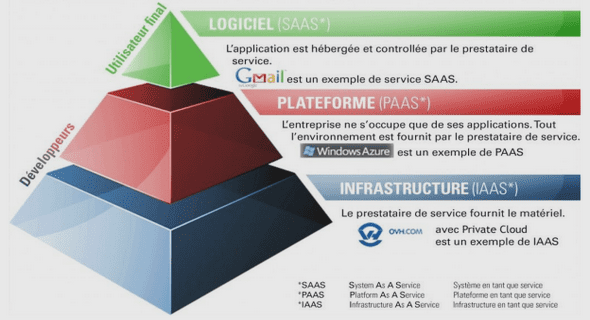
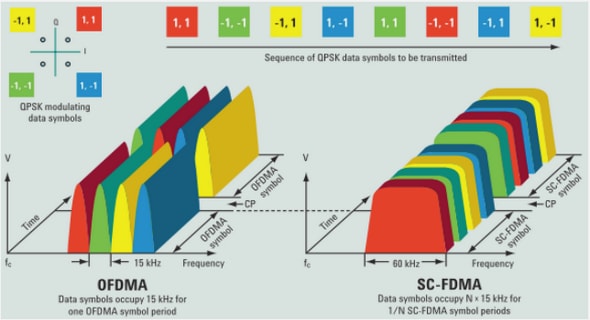
Typologie des activités en ligne et topologie du web
Le chapitre 6 permet d’observer à un niveau méso le partage de liens médias par les 831 enquêtés recrutés par l’institut CSA. A partir de là, trois déplacements vont être opérées : (1) étudier les pratiques de tous les enquêtés de l’échantillon, soit 12 700 comptes ; (2) prendre en considérations toutes les activités et non pas seulement celles avec une URL ; (3) envisager les catégories du web non pas a priori comme le propose l’annuaire CatServ mais a posteriori à partir des pratiques empiriques. Pour le premier point, les enquêtés ont donc été recrutés par la communication autour de l’application, le bouche à oreille, et les réseaux de recherche et enseignement. Le panel est nécessairement déformé par rapport à l’échantillon CSA, lui-même biaisé par rapport à la population des internautes. De plus, certaines informations sur ces enquêtés ne sont pas disponibles. Si les participants se sont arrêtés dans l’application au moment de la collecte des données et n’ont pas renseigné la page « ego », le sexe, l’âge, et la profession des enquêtés ne sont pas indiqués par l’enquêté. Le sexe peut être retrouvé à partir des informations du compte Facebook, mais la profession et l’âge ne semblent pas assez fiables, donc ces éléments sont non renseignés pour un quart de l’échantillon. La population envisagée dans ce chapitre compte 12 700 profils Facebook et est composée de la manière suivante : L’échantillon qui va être considéré maintenant est donc très nettement masculin (69 % d’homme), jeune (34 % de moins de 25 ans), il compte des personnes exerçant une activité de cadres ou CSP+ (23 %) et avec un nombre d’amis important (24 % ont entre 250 et 399 amis, 31 % plus de 400 amis). Il est bien sûr impossible d’envisager avec un tel échantillon de décrire des pratiques représentatives. Un redressement à partir de la référence créée par CSA n’est pas non plus raisonnable scientifiquement. Il faut donc se résoudre à avoir un panel biaisé, mais décrire la déformation permet de bien cerner de quoi les analyses vont traiter.
L’introduction de cette partie soulignait déjà que la matérialité des traces numériques induit un tropisme sur l’activité en ligne et oublie les activités silencieuses et privées comme la navigation et les messages. L’API Facebook indique qu’un internaute a cliqué sur un like, mais pas qu’il a souri en voyant la publication d’un ami. Non seulement les données ne permettent de voir que l’activité, mais en plus les internautes participants à ce type d’enquête sont probablement ceux qui pratiquent le web avec habileté. L’échantillon des participants est suractif, et dans le même temps l’analyse des données montre aussi des profils avec très peu de publications. La présence de ces deux extrêmes dans l’échantillon incite à penser que ce n’est donc pas le fait de poster beaucoup sur Facebook qui caractérise les enquêtés Algopol, mais plus probablement le fait d’être confiant dans son usage d’Internet. Ça ne veut pas dire que ces enquêtés font confiance à Facebook ou aux entreprises du web, mais qu’ils estiment être conscients des risques et avoir adapté leurs usages à ce contexte. Les observations faites sur les freins à la participation allaient dans ce sens, puisque les refus venaient de personnes semblant avoir un usage craintif de Facebook, et qui reportaient leurs doutes sur Algopol. Le point commun des enquêtés recrutés hors CSA est probablement qu’ils estiment contrôler leurs usages par rapport à ce qu’ils connaissent des technologies ; le contrôle amène autant à publier de manière intensive avec un filtre professionnel par exemple, qu’à limiter son nombre d’amis et ses publications. Les jeunes et les seniors recrutés, comme les cadres et les ouvriers, et comme les suractifs ou les sousactifs, semblent être ceux qui considèrent qu’ils maîtrisent leurs usages d’Internet. L’analyse qui va suivre décrit ainsi les activités sur Internet des adhérents au web, mais pas les pratiques des internautes en général,