Toxicité des anilines : Approche QSAR
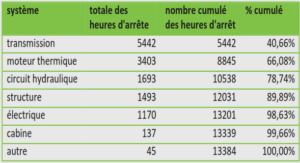
Collecte de données et méthodologie : Il est généralement admis que la toxicité de nombreuses substances, particulièrement les produits chimiques organiques industriels, est la conséquence de leur solubilité dans les lipides, alors que leurs caractéristiques moléculaires spécifiques ont peu ou pas d’influence. Leur mode d’action consisterait en la destruction des processus physiologiques associés aux membranes cellulaires. Les protozoaires sont souvent utilisés pour l’évaluation de la toxicité. Les méthodes mises en œuvre sont basées sur des critères morphologiques, ultra-structuraux, éthologiques et métaboliques [97, 98]. L’inhibition de la croissance d’une population est un indicateur très en vogue, parce qu’il peut être déterminé directement ou indirectement à l’aide d’un équipement électronique. Ce qui permet l’acquisition rapide des observations nécessaires pour les analyses de régression. Nous considérerons la concentration d’inhibition à 50% de la croissance (IGC50), dont le logarithme de l’inverse soit pIGC50 = log(IGC50) -1 , servira d’indicateur de toxicité. Les tests de toxicité ont été réalisés par Schultz et al [99] en examinant la croissance d’une population de Tetrahymona pyriformis. Les essais ont été menés dans des erlenmeyers de 250 ml, contenant 50 ml d’un milieu dont la composition est précisée ci-après : Tableau 5. Milieu de croissance de Tetrahymona pyriformis Eau distillée 1000 ml Proteose peptone 20 g D-glucose 5 g extrait de levure 1 g FeEDTA 1 mL d’une solution à3 % (masse/v) pH 7,35 La température a été fixée à 27 ± 1°C. Ce milieu est inoculé avec 0,25 ml d’une culture contenant approximativement 36 000 cellules par ml. La croissance des ciliés est suivie par spectrophotométrie, en mesurant la densité optique (absorbance) à 540 mm après 48 heures d’incubation. (On pourra trouver dans [100, 101] des indications plus complètes). I. Toxicité des anilines : Approche QSAR 52 Plusieurs critères ont guidé au choix des composés toxiques examinés. Tous sont disponibles dans le commerce avec une pureté suffisante (95 % et plus), ce qui ne nécessite pas une repurification préalablement au test. Des précautions ont été observées afin d’assurer une diversité concernant, à la fois, les propriétés physico-chimiques et la position des substituants. Les solutions stocks des divers composés toxiques, ont été préparées dans le diméthylsulfoxide (DMSO) à des concentrations de 5, 10, 25 et 50 grammes par litre. Dans chaque cas, le volume de solution stock ajouté à chaque fiole est limité par la concentration finale de DMSO qui ne doit pas excéder 0,75 % (350 ml par fiole), quantité qui n’altère pas la reproduction de Tétrahymena [100, 101]. L’ensemble de données relatives aux anilines (tiré de Schultz et al [99]) a été divisé au hasard en un ensemble d’apprentissage (31 objets), utilisé pour développer le modèle QSAR, et un ensemble de validation (17 objets), utilisé uniquement pour les statistiques de validation externe. Les structures de toutes les molécules ont été pré-optimisées à l’aide du champ de force MM+ de la mécanique moléculaire (algorithme Polak-Ribiere) en utilisant le programme HyperChem 6.03 [102]. Les géométries finales d’énergie conformationelle minimale ont été obtenues par la méthode semi-empirique AM1, dans le cadre du formalisme RHF sans interaction de configuration. En appliquant pour norme limite, une racine du carré moyen du gradient égale à 0,001 kcal/mol. Les géométries ainsi optimisées ont été transférées dans le logiciel DRAGON [103] pour calculer 1664 descripteurs dont 271 du type Géométrique et GETAWAY (GEometry, Topology and Atoms Weighted AssemblY). Les descripteurs avec des valeurs constantes ou quasi constantes dans chaque groupe ont été rejetés. Pour chaque paire de descripteurs corrélés (avec un coefficient de corrélation r ≥ 0,95), celui présentant la plus forte corrélation des paires avec les autres descripteurs a été exclu. L’algorithme génétique (AG) [104] a été considéré comme supérieur aux autres méthodes de sélection de variables. Ainsi, la sélection des variables a été effectuée sur l’ensemble d’apprentissage, en utilisant l’AG dans la version de MobyDigs de Todeschini [105] en maximisant la variance expliquée par validation croisée par omission d’une observation 2 QLOO .en utilisant la régression par les moindres carrés ordinaires et la sélection de sous-ensembles de variables explicatives par algorithme génétique (Genetic AlgorithmVariable Subset Sélection ou GA-VSS) [106].
Présentation et discussion du modèle QSAR
Qualités internes du modèle QSAR
L’application de la méthode GA-VSS a conduit à meilleurs modèles pour la prédiction de 50 pIGC basés sur différents ensembles de descripteurs moléculaires. Le meilleur modèle bidimensionnel a été construit en utilisant le rayon de giration ( RGyr ) [Le symbole ( RGyr ) correspond au rayon de giration (masse pesée).C’est parmi les descripteurs], et l’autocorrélation maximale du décalage 3 pondérée par le volume atomique de van der Waals ( R v3 ) ,[ Le symbole ( R v3 ) correspond à R autocorrélation maximale du décalage 3 /pondérée par les volumes atomiques de van der Waals. Il fait partie des descripteurs GETAWAY].La matrice de corrélation (tableau 6) montre que les descripteurs choisis sont corrélés avec la variable à expliquer ( 50 pIGC ) et ne sont pas corrélés entre eux. Toutes les données concernant les valeurs de RGyr , R v3 et de l’activité biologique sont résumées dans le tableau 7. Tableau 6. Matrice de corrélation des descripteurs du modèle 50 pIGC RGyr RGyr 0,844 R v3 0,437 -0,060 L’équation du modèle optimal peut s’écrire: pIGC RGyr R v 50 3,602 0,174 1,439 0,069 16,342 1,416 3 (62) Tous les paramètres statistiques pertinents sont rapportés dans le tableau 8. Les valeurs 2 R et 2 Radj attestent des bonnes performances d’ajustement du modèle qui, de plus, est très fortement significatif (grande valeur du paramètre de Fisher, F). Le modèle est robuste, la différence entre 2 R et 2 Q est faible (1%). La figure 10 montre un tracé des valeurs de 50 pIGC expérimentale et prédites par validation croisée LOO. La dispersion des points est faible bien qu’il y ait deux points un peu éloignés. I. Toxicité des anilines : Approche QSAR 54 Le modèle montre une très bonne stabilité dans la validation interne (la différence entre 2 QLOO et 2 QLMO/50 est d’environ 1%), tandis que le bootstrap confirme la prédictivité interne et la stabilité du modèle. Pour calculer les valeurs des descripteurs R v3 , RGyr avec 50 pIGC , voir le tableau 7, ainsi que les valeurs statistiques pour l’ensemble de calibrage, voir le tableau 8.