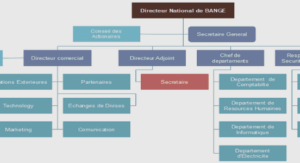
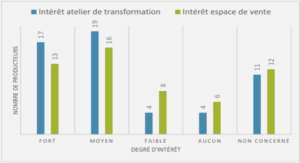
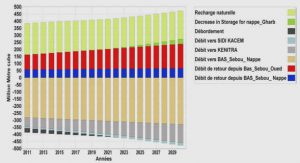
Cours conception d’applications hypermédia, tutoriel & guide de travaux pratiques en pdf.
Cas des données non-linéairement séparables :
En pratique, il est assez rare d‟avoir des données linéairement séparables. Afin de traiter également des données bruitées ou non linéairement séparable, les SVM ont été généralisées grâce à deux outils : la marge souple (soft margin) et les fonctions noyau (kernel functions).
Le principe de la marge souple est d‟autoriser des erreurs de classification. Le nouveau problème de séparation optimale est reformulé comme suit :
Un terme de pénalité est introduit dans la formule (20), Le paramètre C est défini par l‟utilisateur. Il peut être interprété comme une tolérance au bruit de classificateur.
Remarque :
L‟idée de base pour les données non linéairement séparable, est de projeter l‟espace d‟entrée (espace des données) dans un espace de plus grande dimension appelé espace de caractéristiques (feature space) afin d‟obtenir une configuration linéairement séparable (à l‟approximation de la marge souple près) de nos données, et d‟appliquer alors l‟algorithme SVM.
Architecture d’un classificateur SVM
La fonction noyau :
Afin de résoudre le problème de données non linéaires, la fonction noyau joue le rôle central de liaison des vecteurs d‟entrées à l‟espace de caractéristiques de grande dimension. (Voir figure 10).
Figure 10 : Architecture d’une machine à vecteurs de support (d’un nombre N)
Les choix typiques pour la fonction noyau sont :
Noyau gaussien à base radiale (ou RBF : Radial Basis Function)
Remarque :
Si p=1 : la formule (22) devient la fonction d‟un noyau linéaire.
Dans cette étude nous avons utilisé le noyau Gaussien, linéaire, et polynômial de degré 4.
Sélection de modèle SVM :
Une machine à vecteur de support binaire sépare les exemples positifs des exemples négatifs dans la phase d‟apprentissage.
Les multiplicateurs de Lagrange αi pour chaque machine binaire sont déterminés par Si la valeur du paramètre de régularisation « C » qui contrôle la tolérance aux erreurs de classification dans la phase d‟apprentissage est élevée, donc plus de pénalité sera donnée à l’erreur.
Le vecteur d‟apprentissage xi qui a une valeur de αi non nul est appelé « vecteur de support ».
Estimation de l’erreur de généralisation :
La technique la plus populaire pour l‟estimation de l‟erreur de généralisation est la validation croisée (en anglais cross validation ou Leave One Out (LOO)) qui est utilisée indépendamment de la nature de la machine d‟apprentissage utilisée. Le principe de cette méthode consiste à séparer en N sous-ensembles les échantillons de la base d‟apprentissage, à apprendre sur N – 1 sous-ensembles, à valider sur le sous- ensemble restant, puis à faire tourner les sous-ensembles de façon à ce que chacun ait pu être testé. Au final, on note le nombre d‟erreurs de classification de la procédure LOO par ( 1, 1, … . . , , ).
Il a été démontré que dans [7] que cette procédure donne une estimation presque non biaisée de l‟espérance de l‟erreur de généralisation.
Cependant la procédure est coûteuse en calcul, car nécessitant « n » apprentissages.
Une procédure simple d‟estimation d‟erreur de généralisation est la validation croisée dite K-fold. Elle consiste à diviser l‟ensemble des données en k sous-ensembles mutuellement exclusifs de taille approximativement égale.
L‟apprentissage de la machine est effectué en utilisant k-1 sous ensemble et le test est effectué sur le sous-ensemble restant. Cette procédure est utilisée une fois pour le test. La moyenne des k taux d‟erreur obtenus estime l‟erreur de généralisation.
Nous avons montré dans notre travail que la procédure de la validation croisée donne de bonnes estimations de l‟erreur de généralisation. Le nombre d‟ensembles utilisé dans notre travail est égal à 5 (5fold).
Détection par SVM
Notre approche de détection est basée sur l‟extraction automatique des fenêtres rectangulaires. Le contenu de ces fenêtres est transformé en vecteurs de caractéristiques en appliquant les méthodes d‟extraction citées précédemment. Ces vecteurs sont ensuite injectés dans notre classificateur SVM afin de déterminer si une fenêtre correspond ou pas à une région de vertèbres.
Les fenêtres extraites sont de taille fixe, avec un chevauchement pour parcourir la totalité de l‟image, respectant l‟algorithme suivant (voir figure 11):
1. Mettre une fenêtre de taille fixe Wsub*Hsub dans le coin supérieur gauche de l‟image.
2. Extraire une région de l‟image dans cette fenêtre.
3. Décaler la fenêtre à droite avec un pas de Sx (Sx<Wsub).
4. Extraire une nouvelle région de l‟image dans la fenêtre.Refaire l‟étape3 et 4 jusqu‟à ce que la fenêtre soit au bord droit de l‟image.
5. Décaler la fenêtre au bord gauche de l‟image.
6. Décaler la fenêtre en bas avec un pas de Sy (Sy<Hsub).
7. Extraire une nouvelle région de l‟image dans la fenêtre.
8. Refaire l‟étape3 à 8 jusqu‟ace que la fenêtre soit au bord droit de l‟image.