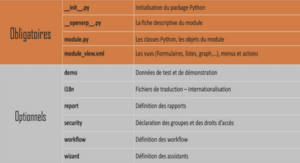
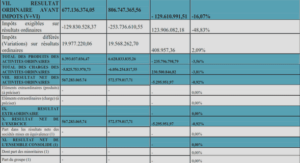
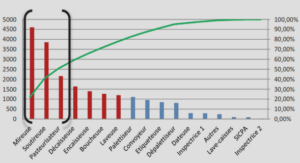
Système générique d’explication
Le contexte et les exigences présentés dans la partie précédente permettent aux destinataires d’exprimer leurs besoins sans avoir à considérer les moyens à mettre en œuvre pour obtenir l’explication appropriée. Nous décrivons maintenant le processus de production des explications répondant à ces besoins. Avant de définir les options techniques qui permettent d’adapter les explications aux différentes combinaisons de contextes et d’exigences, nous présentons l’architecture du système générique (Partie 3.3.1). L’implémentation des composantes d’échantillonnage et de génération, ainsi que leurs paramètres sont décrits respectivement dans les parties 3.3.2 et 3.3.3. Ces éléments permettent de définir les options techniques, dernier élément du protocole à trois niveaux d’IBEX, dans la partie 3.3.4. La correspondance entre le contexte, les exigences et les options techniques est décrite dans la partie 3.4.
Système générique d’explication
Les deux composantes du système générique d’explication Une grande variété de besoins peut être exprimée grâce au contexte et aux exigences décrits dans la partie précédente. Pour produire une gamme d’explications répondant à tous ces besoins, il faut concevoir un système d’explication finement paramétrable grâce à un ensemble suffisamment riche d’options techniques. Idéalement, ces options devraient pouvoir se combiner de manière à répondre indépendamment aux différents besoins des destinataires d’explications. L’architecture que nous proposons est dite générique au sens où de nombreuses BEM (y compris des méthodes existantes [60]) correspondent à des instances spécifiques de ce système. Cette architecture repose sur une extension du cadre générique proposé dans la partie 2.2.2 et nous utilisons à nouveau l’exemple du classificateur de spams (SDA acceptant en entrée le texte d’un email et produisant en sortie la probabilité que cet email soit un spam) pour le présenter. Les deux composantes principales du système sont : (i) la sélection des données d’entrée à soumettre à l’algorithme, appelée l’échantillonnage; et (ii) l’analyse des liens entre les échantillons et leurs classifications pour générer le contenu de l’explication, appelée la génération. Nous proposons une caractérisation formelle de la composante d’échantillonnage (Partie 3.3.2) et de la composante de génération (Partie 3.3.3) qui servent de base à la production d’explications répondant aux besoins de l’utilisateur exprimés sous forme de contextes ou d’exigences (Partie 3.3.4). Les principales notations utilisées dans cette partie et dans les suivantes sont regroupées dans le Tableau 3.1. Nom Description Exemple F Modèle boîte noire Classificateur de spams X Espace d’entrée de F Ensemble des emails Y Espace de sortie de F [0, 1] E Périmètre de l’explication Email xe S Ensemble des échantillons Versions modifiées de xe Θ Paramètres de l’échantillonnage Partie de l’email modifiée D Jeu de données décrivant Jeu de données la population d’entraînement de F TABLE 3.1 – Principales notations
Échantillonnage
Le rôle de l’échantillonnage est de sélectionner les entrées appropriées (ou “échantillons”) pour répondre à une question sur le modèle F. Cette phase doit prendre en compte un certain nombre de facteurs. Le premier aspect est le périmètre de l’explication appelé E 3 . Si la question porte sur une seule entrée xe , alors E = {xe} ; si la question porte sur l’ensemble du modèle F, alors E = D avec D un multiensemble 4 représentant la population des entrées possibles de F. Celui-ci est supposé être mis à disposition du système générique d’explication. Dans le cas général, E et D peuvent être n’importe quel (multi)sous-ensemble des entrées possibles. X, l’ensemble des valeurs d’entrée, peut être considéré comme le support du multiensemble D. Dans l’exemple du classificateur de spams, X est l’ensemble de tous les emails possibles (c’est-à-dire l’ensemble de tous les textes d’un certain format) et D est une base de données réelles d’emails dont dispose le système générique d’explication et qui peut être utilisée pour estimer la distribution des données d’entrée de F. Un exemple typique de D est le jeu de données d’entraînement ou le jeu de données de test utilisés pendant le processus d’apprentissage. D peut aussi être un ensemble de données historiques accumulées pendant l’utilisation du modèle. Lorsque le système générique d’explication ne dispose d’aucune information sur cette distribution, D est l’ensemble vide (D = ∅). Le résultat de l’échantillonnage est un ensemble d’échantillons S = {x1, …, xn} ∈ X n . Par exemple, pour répondre à une question concernant l’impact de la signature sur la classification d’un email particulier xe , une possibilité est de créer un échantillon en supprimant la signature de xe . Cette stratégie ne nécessite aucune information sur la distribution réelle de la population et peut donc être appliquée même si D = ∅. Cependant, la réponse obtenue grâce à cet échantillon peut ne pas être suffisamment réaliste ou précise. Une stratégie plus élaborée consiste à remplacer la signature originale de xe par les signatures d’emails réels. Cette stratégie nécessite des informations sur la distribution réelle de la population (D 6= ∅) afin de garantir que l’ensemble d’échantillons reflète la distribution réelle des emails. De 3. Le périmètre E est lié à l’élément focus du contexte. Des précisions sur cette correspondance sont apportées dans la partie 3.4. 4. D est un multiensemble, car il peut contenir plusieurs occurrences de la même entrée pour refléter la distribution des valeurs dans la population réelle. Cette thèse est accessible à l’adresse : http://theses.insa-lyon.fr/publication/2021LYSEI058/these.pdf © [C. Henin], [2021], INSA Lyon, tous droits réservés 3.3. Système générique d’explication 59 manière générale, la procédure d’échantillonnage peut être définie de la manière suivante : S = {hθ (xe , xp) | (θ, xe , xp) ∈ Θ × E × D, Z(θ, xe , xp)} (3.1) avec : hθ : E × D → X. (3.2) Θ est l’ensemble des paramètres de l’échantillonnage, Z est une fonction de filtrage et hθ définit la manière dont les échantillons sont générés 5 . En bref, le paramètre θ permet de générer plusieurs échantillons pour chaque paire (xe , xp) tandis que Z permet de filtrer une sélection de paires (xe , xp). Dans l’exemple du filtre anti-spams, E contient un seul email (E = {xe}). Les emails sont représentés par le contenu de leurs différentes parties (en-tête, corps, signature, …) et hθ (xe , xp) est une version modifiée de xe obtenue en remplaçant une partie de xe par la partie correspondante dans un élément xp ∈ D. La partie à remplacer est spécifiée par θ. Par exemple, en prenant Θ = {(SIG)} et en supposant que D contient 1000 emails, la procédure d’échantillonnage génère 1000 versions perturbées de xe avec des signatures extraites d’emails de D. Le rôle du paramètre θ est donc de personnaliser la fonction d’échantillonnage. Par exemple, pour comparer l’impact de l’en-tête et de la signature de l’email dans la classification, θ pourrait être utilisé pour spécifier la partie de l’email qui doit être remplacée (en-tête, signature ou les deux). Avec Θ = {(HDR),(SIG),(HDR, SIG)}, la procédure d’échantillonnage générerait 3000 versions de xe avec l’en-tête, la signature ou les deux remplacées par les parties correspondantes d’autres emails dans D. Une autre possibilité offerte par la définition (3.1) consiste à utiliser une fonction de filtrage Z pour ne sélectionner, par exemple, que les emails ayant beaucoup de mots en commun avec xe . Pour rendre la présentation plus concrète, nous présentons trois stratégies d’échantillonnage locales qui sont des instances de la définition (3.1). Ces stratégies ont été implémentées dans IBEX (Partie 3.5). Dans le premier exemple, appelé “Select Closest” (SC), la fonction de filtrage Z est utilisée pour sélectionner le sous-ensemble des élément de D les plus proches de xe en comparant la distance d(xe , xp) à un seuil prédéfini r. Dans ce cas, h close sélectionne 5. Si Θ, D ou E sont vides, ils sont fixés à {0} dans (3.1), sinon S serait également l’ensemble vide. Cette thèse est accessible à l’adresse : http://theses.insa-lyon.fr/publication/2021LYSEI058/these.pdf © [C. Henin], [2021], INSA Lyon, tous droits réservés 60 Chapitre 3. Explications interactives la valeur d’entrée sans la modifier (cf. Figure 3.2b). S = {h close θ (xe , xp) = xp | (θ, xe , xp) ∈ {r} × E × D, d(xe , xp) < θ} (3.3) Dans la stratégie “Select Closest”, les échantillons appartiennent à l’ensemble D ce qui est adapté pour l’obtention d’explications réalistes (realisme ´ = 3). Le nombre d’échantillons et leur proximité avec xe peuvent être ajustés grâce au paramètre r. La deuxième stratégie, appelée “Permutation” (Pm) combine deux entrées pour en obtenir une nouvelle. La fonction d’échantillonnage suivante : ∀i, h perm θ (xe , xp)[i] = xe [i] si i ∈ θ sinon xp[i], avec xe ∈ E, xp ∈ D (3.4) combine les variables de xe avec les variables de xp (x[i] désigne la i ieme ` variable de x) pour obtenir une nouvelle entrée. Le paramètre θ définit l’origine de chaque variable (cf. Figure 3.2c). Le paramètre θ est généré aléatoirement de telle sorte que chaque variable provienne de xp avec une probabilité p, paramètre de l’échantillonnage. Le calcul des valeurs de Shapley dans [118] ou la génération des explications locales sous forme de règles dans Anchors [97] sont basés sur des stratégies d’échantillonnage de ce type. Dans les échantillons, chaque variable prise indépendamment est tirée de la distribution empirique de X et les variables incluses dans le même θ doivent également satisfaire les corrélations existant dans D. L’échantillonnage par permutation représente un niveau intermédiaire de réalisme (realisme ´ = 2). Enfin, “Add random Noise” (AN), génère des échantillons en ajoutant une certaine quantité de bruit aléatoire à xe . Les échantillons sont alors des versions bruitées de xe , le bruit étant tiré d’une distribution normale de moyenne nulle (cf. Figure 3.2d). h noise θ (xe , xp) = xe + θ, avec θ ∼ N (0, σ 2 ) (3.5) L’échantillonnage AN n’utilise pas l’information contenue dans la population D et les variables ne sont pas corrélées. Le paramètre σ représente l’écart-type du bruit ajouté : une valeur faible de σ conduit à des échantillons proches de xe tandis que des valeurs plus élevées Cette thèse est accessible à l’adresse : http://theses.insa-lyon.fr/publication/2021LYSEI058/these.pdf © [C. Henin], [2021], INSA Lyon, tous droits réservés 3.3. Système générique d’explication 61 Classes 0 1 xe Population et point d’intérêt (A) Select closest xe r Échantillons SC r (B) Permutation Échantillons Pm p xe (C) Échantillons AN Add random noise AN xe (D) FIGURE 3.2 – Représentation schématique des processus d’échantillonnage locaux avec des variables continues en deux dimensions. Le point d’intérêt de l’explication (ou périmètre) est le point rouge xe. (a) Population et point d’intérêt pour un problème de classification binaire. Les couleurs représentent les classes. (b) Échantillonnage “Select closest” avec un seuil r. Les échantillons sont les éléments de la population se situant à l’intérieur de la sphère de rayon r centrée sur le point d’intérêt. (c) Échantillonnage par “permutation” avec une probabilité p. Les échantillons sont des versions modifiées du point d’intérêt avec une ou deux variables issues de la distribution empirique. (d) Échantillonnage “add random noise” avec σ1 et σ2 > σ1 . Les échantillons sont des versions bruitées du point d’intérêt. génèrent des échantillons dans un espace plus large (cf. les deux cercles de la Figure 3.2d). L’échantillonnage “add random noise” conduit à des explications qui ne sont pas soumises à des exigences de réalisme (realisme ´ = 1).