Cours statistical methods for characterizing similarities, tutoriel & guide de travaux pratiques en pdf.
We begin with the premise that people in all cultures hold concepts in their minds from a variety of semantic do-mains, such as animals, colors, kin terms, and emotions. Further, within any given semantic domain, the concepts vary in the extent to which they are similar to each other in meaning; that is, they constitute what we define as a semantic structure. The primary aim of this paper is to present a variety of methods for characterizing how similar the « picture » of a semantic structure in the mind of one person (or group of persons) corresponds to the picture held in the mind of another person (or group of persons). Even though the example we use throughout this paper is the comparison of the semantic structure of emotion terms between native English and Japanese speaking subjects, the methods are generalizable to other semantic domains in other languages and to the comparison of profile data in general. The first section of the paper provides a brief summary of methods for characterizing the structure of semantic domains (1±4), that is, obtaining a picture of the interrelationship among the emotion terms. The items of the semantic domain are represented in Euclidean space in which items that are judged more similar are closer to each other than items that are judged less similar. The second section focusses on individuals and examines ways of characterizing the extent to which individuals in a single culture, such as English or Japanese, share knowledge of the semantic structure. The focus is on similarities among subjects rather than on similarities among items. The third section examines methods for the comparison of cultural differ-ences, for example, between native English and Japanese speak-ers. The final sections present graphical methods for visual representation of the data and consider statistical significance tests for the methods. Implications are discussed at the end of the paper.
The paper illustrates how a variety of statistical methods such as comparing mean correlations within and between subgroups, principal components analysis (PCA), analysis of variance (ANOVA), and simple visualization techniques can be appro-priately applied to partitioning shared cultural knowledge into the following segments: (i) a universal portion shared by all subjects regardless of language; (ii) an additional culture-specific portion shared only by subjects speaking the same language; and (iii) a residual portion for each subject due to sampling variabil-ity, measurement error, and true differences among subjects. All of the methods produce results consistent with each other, although each contributes some unique insight and perspective of the data. A comparison of the various methods illustrates the general principle that statistical procedures, insofar as they are warranted and appropriately carried out, point to the same conclusions, whatever the process of statistical reduction.
Describing Semantic Domains
One important part of culture consists of the structure of semantic domains such as animals, kin terms, emotions, or colors. Each individual has an internal cognitive representation of the semantic structure in which the meaning of a term is defined by its location relative to all the other terms. In a series of previous articles, the theory (5) and the methods (1±4) have been developed in which the picture inside the mind of a single individual may be thought of as a cognitive representation of the structure of the corresponding semantic domain. A « composite picture » of the culturally shared semantic domain may be obtained by aggregating the individual cognitive representations into a single picture.
A semantic domain may be defined as an organized set of words, all on the same level of contrast, that refer to a single conceptual category, such as kinship terms, animal names, color terms, or emotion terms. The items in any particular domain for a culture may be obtained by asking a sample of members to free list as many words as possible that belong to the domain (6). The structure of the semantic domain is defined as the arrangement of the terms relative to each other as represented in some metric system such as Euclidean space and described in terms of a set of interpoint distances obtained by scaling judged similarity data. The meaning of each term is defined by its location relative to all the other terms.
To illustrate the various methods, we use a subset of data from a previous study (2) comparing native English and Japanese speakers’ semantic structure of 15 emotion terms using single word professional level translations. The sample of subjects used for illustration consists of 33 monolingual English speakers interviewed in the United States and 32 monolingual Japanese speakers interviewed in Japan. The task that all subjects com-pleted was a paired-comparison rating of all 105 possible pairs of emotion words. The task was to rate each word pair in terms of how similar the words are in meaning on a scale of 1 (most dissimilar) to 5 (most similar). Further details may be found in the earlier study (2).
The initial step is to characterize the semantic structure of the emotion terms for both English and Japanese subjects. The first step in the quantification is to use correspondence analysis to obtain individual representations, one for each of the 65 subjects in the total sample. The correspondence analysis is applied to a 975 3 15 matrix obtained by stacking the 15 3 15 matrices of judged similarity data of all 65 subjects into a single matrix. The analysis results in 65 individual representations that have the same orientation and size in a common Euclidean space. This makes it possible to aggregate representations from any com-bination of individuals by taking the mean location of each term. Details of the methods are described in earlier publications (1±4).
Fig. 1 summarizes the representations of the semantic struc-tures separately aggregated over the 33 English subjects and the 32 Japanese subjects. The location of each term is denoted by a symbol (a star for English and a circle for Japanese) and represents an aggregate position computed by taking the mean of the placements of that term for the English and Japanese subjects, respectively. In this spatial representation, emotion terms that are judged as more similar are closer to each other than terms that are judged less similar. For example, in both groups, anger and hate are very similar (close) to each other and quite dissimilar (distant) from happy.
Vectors connect equivalent words in the two languages and are included to facilitate comparison between the configurations and will be discussed later. For the emotion terms, Dimension 1 appears to correspond to what Osgood (ref. 7 and ref. 8, p. 173) called the Evaluative Factor, « represented by scales such as good-bad, pleasant-unpleasant, and positive-negative, » whereas Dimension 2 appears related to his Activity Factor, « represented by scales such as fast-slow, active-passive, and excitable-calm. » The first dimension goes from unpleasant on the left to pleasant on the right, whereas the second dimension goes from passive at the bottom to active at the top.
We emphasize that the meaning of each term is defined by its location relative to all the other terms. Clearly, this model does not capture all of the aspects of semantics in linguistic theory. However, it does provide an important aspect of semantic meaning captured by judged similarity data. About 50% of the variance in the raw data can be accounted for by the two dimensions displayed in Fig. 1. Four dimensions account for over two-thirds of the variance. Most importantly, the model provides a fully quantified structure for measurement of every term relative to every other term for every subject. This quantification Fig. 1. A comparison of the semantic structure of English speaking subjects (blue) and Japanese speaking subjects (red) for 15 emotion terms.
judged similarity data of all 65 subjects into a single matrix. The analysis results in 65 individual representations that have the same orientation and size in a common Euclidean space. This makes it possible to aggregate representations from any com-bination of individuals by taking the mean location of each term. Details of the methods are described in earlier publications (1±4).
Fig. 1 summarizes the representations of the semantic struc-tures separately aggregated over the 33 English subjects and the 32 Japanese subjects. The location of each term is denoted by a symbol (a star for English and a circle for Japanese) and represents an aggregate position computed by taking the mean of the placements of that term for the English and Japanese subjects, respectively. In this spatial representation, emotion terms that are judged as more similar are closer to each other than terms that are judged less similar. For example, in both groups, anger and hate are very similar (close) to each other and quite dissimilar (distant) from happy.
Vectors connect equivalent words in the two languages and are included to facilitate comparison between the configurations and will be discussed later. For the emotion terms, Dimension 1 appears to correspond to what Osgood (ref. 7 and ref. 8, p. 173) called the Evaluative Factor, « represented by scales such as good-bad, pleasant-unpleasant, and positive-negative, » whereas Dimension 2 appears related to his Activity Factor, « represented by scales such as fast-slow, active-passive, and excitable-calm. » The first dimension goes from unpleasant on the left to pleasant on the right, whereas the second dimension goes from passive at the bottom to active at the top.
We emphasize that the meaning of each term is defined by its location relative to all the other terms. Clearly, this model does not capture all of the aspects of semantics in linguistic theory. However, it does provide an important aspect of semantic meaning captured by judged similarity data. About 50% of the variance in the raw data can be accounted for by the two dimensions displayed in Fig. 1. Four dimensions account for over two-thirds of the variance. Most importantly, the model provides a fully quantified structure for measurement of every term relative to every other term for every subject. This quantification is essential for the investigation into the extent to which the two representations are similar and different.
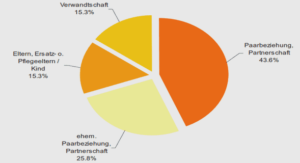
Describing Subject: Subject Similarities Within Cultures
This section focuses on the similarities within groups of native speakers. Subjects of each group are compared in terms of the overall configuration of their individual Euclidean representations of the semantic structures that are summarized in Fig. 1. The following notation is used. Let dnm denote the interpoint dis-tance between the mth term pair for the nth subject, where n 5 1, 2, . . . , N and m 5 1, 2, . . . , M. In our example, the combined sample of subjects yields N 5 65, and the 15 terms yield M 5 105 pairs. Then, the resulting matrix of subject vectors is given by Dn 5 (dnm)N3M.
There are a variety of ways in which similarities among pairs of subjects might be measured. The use of interpoint distances is motivated by Rao and Suryawanshi’s (9) suggestion that information on the shape of a configuration is encoded in terms of the k (k 2 1)/2 Euclidean distances between all possible pairs of critical points, where the k points are selected to reflect important aspects of the shape. In our study, the points are defined by the locations of the 15 emotion terms in the spatial configuration obtained above. The Euclidean distances for each subject are computed from their row score coordinates from the correspondence analysis by using four dimensions (see refs. 1±4) where the remaining dimensions are treated as noise.
Next, the subject vectors for each group are placed separately into two rectangular matrices with 33 rows for the English subjects and 32 rows for the Japanese subjects. In both matrices, the rows represent subjects, and the 105 columns represent the pairs of the 15 emotion terms. The rows of these matrices are each standardized to have a mean of zero and a variance of one by subtracting the row mean and dividing by the row standard deviation. We refer to these row standardized rectangular matrices as standardized shape matrices and denote them by Z1 and Z2, for native English and Japanese speakers, respectively.
In this section, the analyses are based on the shape matrices as well as subject-by-subject correlation matrices obtained from them: namely, Ri 5 ZiZTi /M, for i 5 1, 2. The methods that we illustrate on these matrices will be considered in the following order: comparing mean correlations, principal components anal-ysis of the correlation matrices, and analysis of variance of the rectangular shape matrices. For now, we are using these statistics in a descriptive manner: that is, to characterize the similarity and differences within and between groups; however, we will men-tion some inferential approaches later.