Sémantisation et sérialisation de flux RDF
Le traitement des données reçues constitue la problématique majeure de l’IdO. Dans le cas d’infrastructures développées et/ou étendues, il est très fréquent que les capteurs produisant les mesures ne partagent pas le même format de données, ni même un modèle de données identique. Cela peut être lié à des différences de versions, mais aussi plus simplement au fait que les me sures effectuées sont différentes, et donc représentées dans un format/modèle adapté en conséquence.
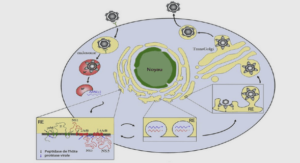
Comme indiqué dans la figure 1, le projet Waves effec tue une conversion des données reçues dans le modèle de données RDF, i.e., un modèle de graphe labellisé et orienté. Nous avons choisi ce type de modèle afin de faciliter les opérations à réaliser sur les données par la suite (intégra tion de données, sémantisation, requêtage et raisonnement). En effet, nous utilisons du raisonnement pour l’identification d’anomalies, ainsi que pour la recherche de leurs origines.
Par ailleurs, les relèves des capteurs seules ne per mettent pas toujours de raisonner de manière efficace, car elle contiennent peu d’éléments pour pouvoir être traitées efficacement (des données com pactes sont transmises plus efficacement, comme présenté en figure 19 (a)). Par ailleurs, dans notre cas d’usage, nous avons souvent besoin d’accéder à la configuration du réseau pour la recherche d’anomalie (représentation RDF statique, figure 19 (b)),
et de traiter des flux de données extérieurs pour la détection d’origine (sources événementielles). Il y a donc parfois un besoin d’inférence et de gestion de sources multiples pour compléter les flux, ce qui 67 (a) Extrait de flux : ?x1 id « QDT01 » ?x1 timestamp « 2014-01-01T07:15:00 » ?x1 pressureMeasure _:x2 ?x2 value 7.03 (b) Extrait de la base statique : a ssn:Platform ; rdfs:label « Hubies Haut » . ssn:onPlatform . waves:flow1 a cuahsi:inputFlow . ssn:observes waves:flow1 . waves:flow1 cuahsi:relatedTo . a ssn:Sensor ; rdfs:label « QDT01 » ; wgs84_pos:lat 4.8834914E1 ; wgs84_pos:long 2.144792E0 .
Figure 19– Exemple de données RDF de Waves justifie encore plus l’usage du RDF. Toutefois, le raisonnement sur des flux RDF est une problématique de re cherche majeure de nos jours, principalement liée au besoin de performance, que ce soit en terme de volume de données ou de vitesse de traitement. Il s’agit d’une opération coûteuse, et son application sur un débit de données impor tant impacte énormément les performances. Aucune des techniques existantes n’est parfaitement adaptée à tous les cas :
il n’y a pas de solution globale, chaque approche que nous avons étudiée est adaptée pour certains cas précis (fenêtre de données temporelle, par exemple), mais perdra en performance ou ne sera fonctionnelle dans d’autres cas d’utilisation. Puisque Waves a pour vocation d’être une plateforme portable et adaptative, nous avons étudié les alternatives existantes pour trouver une solution adaptée.
Par ailleurs, se baser sur les formats RDF existants (turtle, n3, trig, RDF/XML, ntriples..) n’est pas satisfaisant dans un contexte de gestion de flux : en effet, aucun d’eux ne tient compte du schéma commun des flux entrants, qui reste rela tivement statique pour chaque capteur. De même, il serait préférable de se 68 baser sur une approche plus compacte, car aucun des formats mentionnés n’est très efficace pour la représentation de larges volumes de données, e.g., l’omniprésence d’URIs.
Plusieurs solutions ont déjà été expérimentées afin de tenter de mani puler des flux RDF efficacement. Nous avons mentionné dans notre état de l’art l’existence de méthodes de compression qui peuvent être adaptées aux flux, offrent divers avantages. En effet, des éléments plus compacts per mettent d’améliorer la fréquence de transmission et de réception. Plusieurs algorithmes ont donc été développés (section 3.1),
avec pour chacun une ap proche différente. Malgré tout, aucune n’est parfaite, elles présentent toutes des défauts, et ne sont généralement pas adaptées au traitement de flux. L’ap proche de RDSZ attribue des identifiants aux sujets et aux objets différents, ce qui se révèle un mauvais choix pour des flux, dont les littéraux changent très régulièrement. Zstreamy est plus adapté, mais son en-tête peut dans certains cas dupliquer l’horodatage des données, ce qui n’est pas nécessaire, et peut prêter à confusion.
Il y a également un processus de compression et de décompression potentiellement plus long. ERI se base sur RDSZ, en apportant des améliorations : dans cette approche, les propriétés sont égale ment encodées, mais le problème des littéraux évoqué précédemment persiste. C’est pour ces raisons que nous avons choisi de développer une nouvelle sé rialisation, en reprenant certains principes des travaux étudiés, tout en les adaptant à un contexte de traitement de flux.