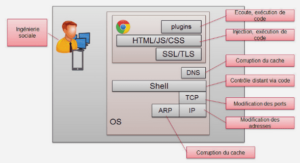
Qu’est-ce qu’un objet ?
L’indépendance
Sous le terme très inapproprié d’objet se cache la notion d’indépendance. Un objet est indépendant de tout l’environnement dans lequel il évolue, sauf des autres objets dont il s’est lui-même déclaré dépendant. En théorie, ceci implique que l’utilisateur d’un objet peut faire tout ce qu’il veut à cet objet: ce dernier réagira toujours de façon appropriée, parceque justement, il n’a pas de liens avec le code qui utilise cet objet. L’objet s’est lui-même défini de telle façon que même une utilisation inappropriée ne peut pas conduire à une faute grossière au niveau de l’objet lui-même. (Par contre, il est évident que l’objet, si bien implémenté soit-il, ne saurait protéger son utilisateur contre lui-même). Si on demande une action inappropriée à un objet, cet objet refusera de faire cette action, parcequ’il ne « comprendra pas » ce que l’on attend de lui. Par contraste, dans un style de programmation classique, il est toujours possible d’appliquer un algorithme quelconque à des données inadéquates, parceque l’algorithme (le code) n’est en aucune façon lié aux quantités qu’il doit traiter. Le fait de contrôler le type de données lors de la compilation ne représente qu’une mesure élémentaire de protection : rien ne permet d’affirmer (sinon de multiples tests impliquant une connaissance profonde de l’implémentation de ce type de données) que la variable du type indiqué est correctement initialisée pour pouvoir être traitée par la procédure en question.
La programmation conventionnelle tend à séparer le code et les données. On a d’une part, un algorithme, et d’autre part des données auxquelles on applique cet algorithme. Cette vision ne s’applique pas uniquement à la génération de code proprement dite, mais également
à la phase de conception de projet. Par opposition, notre nouvelle méthode tente de découper le problème global en entités indépendantes, qui englobent les données et les opérations applicables au dites données. Ce conglomérat de code et de données est ce qu’on appelle communément un objet, en jargon informatique. Notons que selon le langage de programmation que l’on utilise, cet objet peut faire preuve de caractéristiques très différentes.
Messages, méthodes et classes
Au lieu de passer des données à une procédure, comme on le conçoit dans un environnement de programmation conventionnel, on va émettre des messages à destination d’une instance d’une certaine classe, qui va réagir à ce message en agissant de la manière appropriée sur sa propre implémentation. L’envoi d’un message à un objet implique que l’objet applique une certaine méthode à lui-même. Voici beaucoup de termes nouveaux qu’il con-vient d’expliciter.
Une classe n’est en fait pas grand’chose d’autre qu’un type de données. La construction PASCAL RECORD…END (en C struct { }) implémente en principe quelque chose d’assez proche du concept de classe. D’ailleurs, certains jargons de PASCAL, introduits par Borland entre autres, ont défini un dialecte PASCAL « orienté objets » qui utilise la construc-tion RECORD pour implémenter la notion de classe telle qu’elle est définie dans le monde « OO – orienté objets ». Si une classe est un type, une instance n’est qu’une incarnation de ce type, comme dans la déclaration:
int anInt;
int est le type, donc la classe. anInt est la variable de ce type, donc l’instance de cette classe. Ce que OO ajoute à ces notions, c’est qu’une classe est capable de certaines réactions, comme si tout objet de la classe int était capable de réagir à un stimulus quelconque lui demandant de s’afficher lui-même. Le stimulus en question est appelé, en terminologie OO, un message. La manière que la classe considerée utilisera pour réagir à ce message sera une méthode.
Dans la figure ci-dessous, on a représenté une hiérarchie d’animaux. Ces animaux ont tous quelques propriétés communes: par exemple, tous les animaux s’alimentent. Il est donc en principe possible de passer le message MANGER à un animal sans tenir compte du type particulier d’animal dont il s’agit. L’animal comprendra ce message, et réagira en consé-quence. Cette réaction peut en revanche être très différente selon l’animal : un chat et une mésange ne mangent pas la même chose, faire manger le chat comme le fait la mésange con-duira à plus ou moins brève échéance à la mort du chat par inanition, à moins que la réaction du chat ne soit suffisamment vigoureuse (par exemple, en mangeant la mésange…).
La séparation des données et des traitements : le piège !
Examinons le problème de l’évolution de code fonctionnel (ou procédural) plus en détail, au travers d’un autre exemple. Il va s’agir ici de faire évoluer une application de ges-tion de bibliothèque pour gérer une médiathèque, afin de prendre en compte de nouveaux types d’ouvrages (cassettes vidéo, CD-ROM, etc…), nécessite :
• de faire évoluer les structures de données qui sont manipulées par les fonctions,
• d’adapter les traitements, qui ne manipulaient à l’origine qu’un seul type de document (des livres).
Il faudra donc modifier toutes les portions de code qui utilisent la base documentaire, pour gérer les données et les actions propres aux différents types de documents. Il faudra par exemple modifier la fonction qui réalise l’édition des « lettres de rappel » (une lettre de rappel est une mise en demeure, qu’on envoie automatiquement aux personnes qui tardent à rendre un ouvrage emprunté). Si l’on désire que le délai avant rappel varie selon le type de document emprunté, il faut prévoir une règle de calcul pour chaque type de document. En fait, c’est la quasi-totalité de l’application qui devra être adaptée, pour gérer les nouvelles données et réaliser les traitements correspondants. Et cela, à chaque fois qu’on décidera de gérer un nouveau type de document !