Cours pratique de la régression linéaire, tutoriel & guide de travaux pratiques en pdf.
Détection des points aberrants
L’objectif de la détection des points aberrants et in uents est de repérer des points qui jouent un rÙle anormal dans la rÈgression, jusqu’‡ en fausser les rÈsultats. Il faut s’entendre sur le terme anormal, nous pourrons en rÈsumer les di Èrentes tournures de la maniËre suivante :
L’observation prend une valeur inhabituelle sur une des variables. Nous parlons alors de dÈtection univariÈe car nous Ètudions les variables individuellement. Par exemple, un des vÈhicules a une puissance 700 cv, nous avons intÈgrÈ une Formule 1 dans notre chier de vÈhicules.
Une combinaison de valeurs chez les exogËnes est inhabituelle. Par exemple, une voiture trËs lÈgËre et trËs puissante : le poids pris individuellement ne se dÈmarque pas, la puissance non plus, mais leur concomitance est surprenante (Figure 2.1).
L’observation est trËs mal reconstituÈe par la rÈgression, n’obÈissant pas de maniËre ostensible ‡ la relation modÈlisÈe entre les exogËnes et l’endogËne. Dans ce cas, le rÈsidu observÈ est trop ÈlevÈ.
L’observation pËse de maniËre exagÈrÈe dans la rÈgression, au point que les rÈsultats obtenus (prÈ-diction, coe cient, …) sont trËs di Èrents selon que nous l’intÈgrons ou non dans la rÈgression.
Outre les ouvrages enumÈrÈs en bibliographie, deux rÈfÈrences en ligne complËtent ‡ merveille ce chapitre : le document de J. Confais et M. Le Guen [12], section 4.3, pages 307 ‡ 311 ; et la prÈsentation.
Points aberrants : dÈtection univariée
BoÓte ‡ moustache et dÈtection des points atypiques
L’outil le plus simple pour se faire une idÈe de la distribution d’une variable continue est la boÓte ‡ moustaches (Figure 2.2), dite box-plot 1. Elle o re une vue synthÈtique sur plusieurs indicateurs impor-tants : le premier quartile ( Q1), la mÈdiane (M e) et le troisiËme quartile ( Q3). On peut aussi jauger visuellement l’intervalle inter-quartile qui mesure la dispersion ( IQ = Q3 − Q1).
On pense ‡ tort que les extrÈmitÈs de la boÓte correspond aux valeurs minimales et maximales. En rÈalitÈ il s’agit des valeurs minimales et maximales non atypiques. Les seuils dÈsignant les valeurs atypiques sont dÈ nies par les rËgles suivantes 2 :
LIF =Q1−1.5×IQ
UIF =Q3+1.5×IQ
o˘ LIF signi e « lower inner fence » et UIF « upper inner fence ».
Les points situÈs au del‡ de ces limites sont souvent jugÈes atypiques. Il convient de se pencher attentivement sur les observations correspondantes.
Remarque 11 (RËgle des 3-sigma). Une autre rËgle empirique est largement rÈpandue dans la communautÈ statistique, il s’agit de la rËgle des 3-sigma. Elle xe les bornes basses et hautes ‡ 3 fois l’Ècart-type autour de la moyenne. Si l’on considËre que la distribution est normale, 99.7% des observations sont situÈes dans cet intervalle. La principale faiblesse de cette approche est l’hypothËse de normalitÈ sous-jacente qui en rÈduit la portÈe.
Les « outer fence »
Il est possible de durcir les conditions ci-dessus en Èlargissant les bornes des valeurs. On parle alors de outer fence. Elles sont dÈ nies de la maniËre suivante :
LOF =Q1−3×IQ
UOF =Q3+3×IQ
Pour distinguer les points dÈtectÈs selon la rËgle inner ou outer, on parle de « points moyennement atypiques » (mild outlier) et « points extrÍmement atypiques » (extreme outlier).
Application sur les donnÈes CONSO
Il est possible de produire une boÓte ‡ moustache pour chaque variable du chier de donnÈes. Nous disposons ainsi trËs rapidement d’informations sur l’Ètalement de la distribution, de la prÈsence de points qui s’Ècartent fortement des autres. Pour la variable endogËne (Figure 2.2), nous dÈtectons immÈdiatement 2 observations suspectes qui consomment largement plus que les autres vÈhicules : la Ferrari 456 GT et la Mercedes S 600.
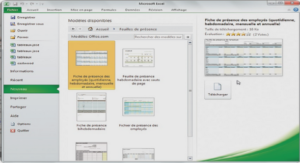
Une autre maniËre de procÈder est d’utiliser simplement le tableur EXCEL (Figure 2.3) :
- de produire le 1er et le 3Ëme quartile ;
- d’en dÈduire l’intervalle inter-quartile ;
- de calculer les bornes LIF et UIF ;
- et de s’appuyer sur la mise en forme conditionnelle pour distinguer les points « suspects » pour chaque variable.
Il semble que 3 vÈhicules soient assez di Èrents du reste de l’Èchantillon, sur la quasi-totalitÈ des variables. Nous produisons dans un tableau rÈcapitulatif les associations « observation-variable » suspects (Tableau 2.1).
DÈtection multivariÈe sur les exogËnes : le levier
Le levier
La dÈtection univariÈe donne dÈj‡ des informations intÈressantes. Mais elle prÈsente le dÈfaut de ne pas tenir compte des interactions entre les variables. Dans cette section, nous Ètudions un outil capital pour l’Ètude des points atypiques et in uents : le levier.
Son interprÈtation est relativement simple. Il indique, pour l’observation i, la distance avec le centre de gravitÈ du nuage de points dans l’espace dÈ ni par les exogËnes. La mesure a de particulier qu’elle tient compte de la forme du nuage de points, il s’agit de la distance de Mahalanobis (Tenenhaus, page 94). La prise en compte de la con guration des points dans l’espace de reprÈsentation permet de mieux juger de l’Èloignement d’une observation par rapport aux autres (Figure 2.4).
2 Points aberrants et points in uents
Pour cela, penchons-nous sur quelques propriÈtÈs du levier. Par dÈ nition 0 ≤ hi ≤ 1, et surtout ∑n i=1 hi = p + 1, o˘ p + 1 est le nombre de coe cients ‡ estimer dans une rÈgression avec constante. On considËre que le levier d’une observation est anormalement ÈlevÈ dËs lors que :
Remarque 12 (Seuil de coupure et Ètude des points). La rËgle dÈ nie ci-dessus, aussi rÈpandue soit-elle, est avant tout empirique. Dans la pratique, il est tout aussi pertinent de trier les observations selon la valeur de hi de maniËre ‡ mettre en Èvidence les cas extrÍmes. Une Ètude approfondie de ces observations permet de statuer sur leur positionnement par rapport aux autres.
Nous appliquons les calculs ci-dessus sur les donnÈes CONSO. Nous avons utilisÈ le logiciel TANAGRA (Figure 2.5) 4. La valeur de coupure est 2 × 4+131 = 0.3226, 3 points se dÈmarquent immÈdiatement, les mÍmes que pour la dÈtection univariÈe : la Ferrari ( h8 = 0.8686), la Mercedes (h9 = 0.4843) et la Maserati (h10 = 0.6418). Les raisons semblent Èvidentes : il s’agit de grosses cylindrÈes luxueuses, des limousines (Mercedes) ou des vÈhicules sportifs (Ferrari, Maserati).
Essayons d’approfondir notre analyse en triant cette fois-ci les observations de maniËre dÈcroissante selon hi. Les 3 observations ci-dessus arrivent bien Èvidemment en premiËre place, mais nous constatons que d’autres observations prÈsentaient un levier proche de la valeur seuil. Il s’agit de la Toyota Previa Salon, et dans une moindre mesure de la Hyundai Sonata 3000 (Figure 2.6). La premiËre est un monospace (nous remarquons ‡ proximitÈ 2 autres monospaces, la Seat Alhambra et la Peugeot 806) qui se distingue par la conjonction d’un prix et d’un poids ÈlevÈs ; la seconde est une voiture de luxe corÈenne, les raisons de son Èloignement par rapport aux autres vÈhicules tiennent, semble-t-il, en la conjonction peu courante d’un prix relativement moyen et d’une cylindrÈe ÈlevÈe.
Partie I La régression dans la pratique
1 Étude des résidus
1.1 Diagnostic graphique
1.2 Tester le caractère aléatoire des erreurs
1.3 Test de normalité
1.4 Conclusion
2 Points aberrants et points inuents
2.1 Points aberrants : détection univariée
2.2 Détection multivariée sur les exogènes : le levier
2.3 Résidu standardisé
2.4 Résidu studentisé
2.5 Autres indicateurs usuels
2.6 Bilan et traitement des données atypiques
3 Colinéarité et sélection de variables
3.1 Détection de la colinéarité
3.2 Traitement de la colinéarité – Sélection de variables
3.3 Régression stagewise
3.4 Coecient de corrélation partielle et sélection de variables
3.5 Les régressions partielles
3.6 Régressions croisées
3.7 Conclusion
4 Régression sur des exogènes qualitatives
4.1 Analyse de variance à 1 facteur et transposition à la régression
4.2 Inadéquation du codage disjonctif complet
4.3 Codage « Cornered eect » de l’exogène qualitative
4.4 Comparaisons entres groupes
4.5 Régression avec plusieurs explicatives qualitatives
4.6 Régression avec un mix d’explicatives qualitatives et quantitatives
4.7 Sélection de variables en présence d’exogènes qualitatives
4.8 Codage d’une exogène qualitative ordinale
4.9 Le codage « centered eect » d’une exogène qualitative nominale
4.10 Le codage « contrast eect » d’une exogène qualitative
4.11 Les erreurs à ne pas commettre
4.12 Conclusion
5 Rupture de structure
5.1 Régression contrainte et régression non-contrainte – Test de Chow
5.2 Détecter la nature de la rupture
5.3 Conclusion
6 Détection et traitement de la non linéarité
6.1 Non linéarité dans la régression simple
6.2 Non linéarité dans la régression multiple