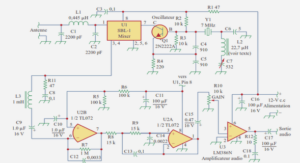
Perception du relief
Contrairement à une idée répandue, il existe de nombreuses façons de percevoir le relief, notamment avec la vision monoculaire. Nous allons néanmoins particulièrement détailler la vision stéréoscopique qui est le moyen de percevoir le relief le plus puissant.
Vision monoculaire
Il existe de nombreux indices permettant de percevoir le relief en vision monoculaire pour une scène statique. Les plus évidents sont les indices de perspective que l’on peut extraire de lignes de fuite. Les lumières et les ombres sur chaque élément d’une scène fournissent également de nombreux indices de profondeur, notamment en révélant les lignes de fuite.
Les gradients de textures peuvent aussi donner ce genre de renseignements.
Il existe aussi des indices permettant d’ordonner la profondeur de plusieurs objets. En effet, si un objet en occulte un autre, c’est qu’il est devant lui. Cette notion s’étend même aux milieux participants comme la brume ou le brouillard. Si ce dernier est relativement homogène, il dissimulera d’avantage un objet situé loin de l’observateur. Il est aussi possible de placer l’un par rapport à l’autre deux objets usuels dont la taille est connue par l’observateur.
L’accommodation de l’œil sur un objet est aussi un indice précieux concernant sa position dans l’espace. En effet, même si la mise au point sur cet objet s’effectue inconsciemment, nous sommes capables d’en extraire de l’information. L’accommodation permet en outre de distinguer la profondeur de deux objets situés sur deux plans différents. Si l’un des objets est net, l’autre sera flou.
Enfin, la parallaxe de mouvement induite par le mouvement de l’observateur lui fournit plusieurs points de vue de la même scène. Cette perception du relief est donc fortement reliée à la perception stéréoscopique. Pour plus d’informations, le lecteur peut se référer au Traité de la Réalité Virtuelle de Fuchs et al. [FMP01].
Vision stéréoscopique
La vision stéréoscopique est basée sur un principe simple, les deux yeux reçoivent chacun des images semblables, mais pas identiques. Le cerveau se charge de fusionner ces deux images et la « reconstruction » opérée aboutit à des renseignements sur la géométrie et la disposition des objets observés.
Dans le cas d’une image stéréoscopique, le procédé est le même. L’image stéréoscopique nécessite un support comme un écran de cinéma, d’ordinateur ou une simple feuille de papier. Sur ce support vont figurer deux images, une pour l’œil droit et une pour l’œil gauche. Il existe alors de nombreux dispositifs pour associer la bonne image à chacun des deux yeux (cf. annexe 2).
Etant donné un point M de la scène, ce point va figurer sur les deux images et comme le montre la figure 100, sa position sur ces deux images est en général différente. La distance entre le projeté de M sur l’image de droite et le projeté de M sur l’image de gauche est appelée parallaxe.
Parallaxe horizontale
En position normale, les yeux des êtres humains se situent (sauf cas particuliers) sur un plan horizontal. La restitution stéréoscopique d’une scène en images de synthèse doit donc tenir compte de cette information en générant les deux images avec des caméras placées judicieusement. La position d’une caméra est définie par la position de son centre de projection, l’orientation de son axe optique et l’orientation du vecteur définissant la direction de la hauteur. Dans le cas d’images stéréoscopiques, il faut donc que les vecteurs définissant la hauteur soit perpendiculaires à la droite passant par les centres des caméras. Notons que l’orientation de l’axe optique est directement définie par la normale du plan image de la caméra.
La distance séparant les deux caméras (ou séparant nos deux yeux) s’appelle « distance interoculaire », nous la noterons dio par la suite. Elle est estimée à 65 mm en moyenne.
Notons aussi que la parallaxe horizontale correspond à la composante horizontale de la parallaxe (cette notation suppose que l’observateur se tient en position verticale). On parle de parallaxe positive (non croisée) quand l’objet virtuel se situe derrière l’écran. Comme nous le montre la figure 102, le projeté d’un tel objet en direction de l’œil droit se trouve donc à droite de son projeté en direction de l’œil gauche.
Parallaxe verticale
Les paragraphes précédents montrent bien qu’il est naturel d’avoir affaire à de la parallaxe horizontale et que la parallaxe verticale est préjudiciable. Lors de la création d’images de synthèses stéréoscopiques, il faut savoir qu’un mauvais paramétrage des caméras peut engendrer de la parallaxe verticale. En effet, il parait plutôt intuitif de faire converger les axes optiques des deux caméras vers le centre de la scène (figure 105), cela semble apporter un supplément d’informations, notamment pour les scènes proches de l’observateur. En réalité, il est préférable de paramétrer les caméras de telle sorte que leur axe optique soient parallèles (figure 106). Si ce n’est pas le cas, il y a alors apparition de parallaxe verticale.
Rendu stéréoscopique en synthèse dimages
Comme nous venons de le voir dans les paragraphes précédents, les axes optiques des caméras doivent être parallèles. Une première méthode de rendu consiste donc à générer une vue de la scène puis à décaler la caméra afin de générer une seconde vue. Les deux vues sont alors fusionnées en les décalant de la même distance que celle qui sépare les deux caméras.
Dans ce cas là, les bords de l’image finale où ne figure qu’une des deux images sont perdus.
Une autre approche consiste à utiliser une pyramide de projection non symétrique. La figure 108 illustre les variables nécessaires pour paramétrer un système de deux caméras.
Un des paramètres déterminant de ce système est la position du plan image. Ce plan image défini l’ensemble des points de la scène qui, lors de la restitution, seront perçus comme étant situés sur le support de l’image stéréoscopique. En effet, les points situés sur ce plan auront la même position (en pixel) sur l’image finale, qu’ils soient destinés à l’œil droit ou à l’œil gauche. Ces points auront donc une parallaxe nulle.
La variable W correspond à la largeur de l’écran (ou du support des images stéréoscopiques en général) dans la scène. La variable α représente le champ de vision du système. Les paramètres near et far servent à définir une caméra dans certaines bibliothèques graphiques comme OpenGL ou DirectX. Il en est de même pour les paramètres min et max.
Plane Sweep et rendu stéréoscopique
Dans le cas de rendu stéréoscopique, la plupart des méthodes doivent effectuer deux rendus, un pour chaque œil. Ce double rendu n’est pas trop contraignant pour les méthodes ne gérant que les scènes statiques dont le rendu est déjà temps réel. Par contre elle l’est davantage pour les méthodes traitant de la vidéo et en particulier pour les méthodes en direct, qui utilisent déjà la totalité des ressources disponibles.
Il est intéressant de noter qu’une grande partie des informations concernant la scène peuvent être partagées pour les deux vues, comme par exemple un maillage ou l’illumination diffuse et ambiante. Les méthodes de reconstruction ainsi que certaines méthodes de la famille des Visual Hulls peuvent facilement partager ces informations une fois la reconstruction effectuée. Ce n’est pas le cas pour toutes les méthodes de rendu à base d’images ou pour les méthodes utilisant des cartes de profondeur dépendant souvent du point de vue. Ces méthodes doivent alors calculer les deux images stéréoscopiques de façon indépendante.
Il se trouve que la méthode des Plane Sweep est spécialement bien adaptée au rendu stéréoscopique puisque les calculs des scores et des couleurs sont faits localement. Ils peuvent ainsi être partagés par plusieurs caméras virtuelles.
Modification de lalgorithme classique
Comme illustré sur la figure 112, les informations des scores et des couleurs calculées sur un plan D donné sont des informations locales à la scène et donc communes aux deux caméras. C’est la projection de D sur les deux caméras qui fait que le rendu sera différent pour chacune d’entre elles. Sachant que le calcul du score et des couleurs est la tâche principale de la méthode des Plane Sweep, le gain de temps en partageant les données devient alors évident.
Implémentation
Cette méthode a été implémentée en C++ sous Linux en utilisant les bibliothèques OpenGL et GLSL. La première passe de rendu, durant laquelle les scores et les couleurs sont calculés, doit être effectuée off-screen, c’est-à-dire que le résultat ne doit pas apparaître à l’écran. En effet, il n’est pas possible d’effectuer le rendu directement sur l’une des deux images puisque cette projection engendrerait une mise à jour des scores et des couleurs. On ne pourrait plus alors reprojeter ces données sur la seconde caméra.
Une première méthode consiste à effectuer ce rendu off-screen à l’aide de p-buffers ce qui nécessite un transfert de données du frame-buffer vers les textures texScore et texColor.
L’emploi de Frame Buffer Object (FBO) et de Multiple Render Target (MRT) est beaucoup plus approprié puisqu’il évite ce genre de transfert coûteux en temps. En pratique la seconde méthode est nettement plus rapide sauf si la carte graphique utilisée ne gère pas en hardware les FBO et les MRT. Cette implémentation permet donc d’éviter des transferts entre le frame-buffer et les textures ainsi que tout transfert entre la carte graphique et la mémoire principale de l’ordinateur.
Résultats
Cette adaptation des Plane Sweep pour la création d’images stéréoscopiques est particulièrement efficace. Voici quelques images pour illustrer nos résultats suivis des performances obtenues.
Résultats en images
L’acquisition des images a été effectuée à l’aide de quatre caméras Tri-CCD Sony DCR-PC 1000E. La figure 113 illustre une paire d’images stéréoscopiques obtenue avec notre méthode. Ces images ont été calculées en subdivisant la scène en 30 plans. Il est possible de voir une image en relief par vision croisée (en louchant).
Performances
Les tests suivants ont été réalisés sur un Athlon 1 GHz et une carte graphique Nvidia GeForce 6800 GT. Les images traitées et les images générées sont en 320×240 ce qui correspond à une image 640×240 lorsque les images stéréoscopiques sont mises côte à côte. Le tableau suivant illustre les framerate de notre méthode utilisée d’une part en mode standard en ne générant qu’une seule image et d’autre part en mode stéréoscopique et donc en générant une paire d’image stéréoscopique. Plusieurs degrés de discrétisation sont utilisés pour illustrer cette comparaison.