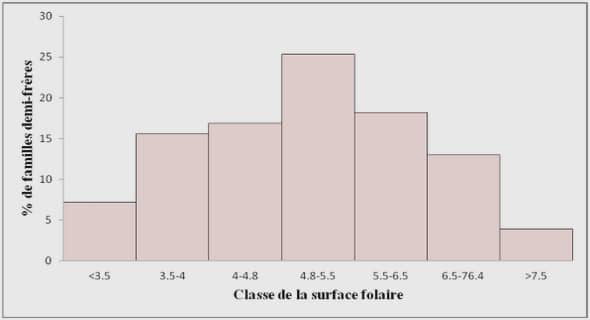
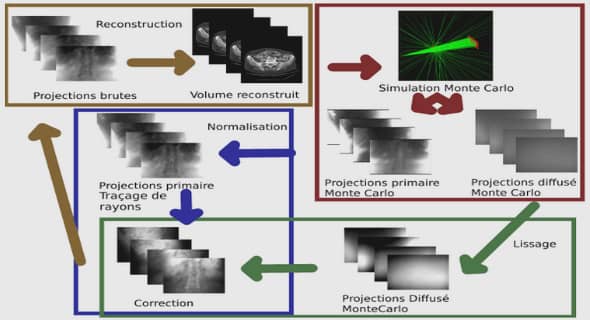
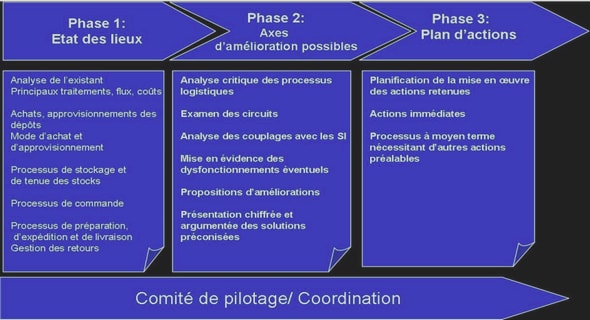
Notions sur la théorie des probabilités
Notion sur les probabilités
On rappelle ici quelques notions de base ainsi que des notations de la théorie des probabilités qui seront utilisées dans le reste de ce mémoire. Dans l’observation d’un phénomène aléatoire, on introduit Θ l’ensemble des résultats possibles dont θ est un événement élémentaire. On munit Θ d’une tribu F (voir annexe 1 pour plus de détails) dont les éléments sont appelés événements. L’espace (Θ, F) est muni d’une mesure probabiliste PΘ de F dans [0 ; 1]. On appelle (Θ, F, PΘ) l’espace probabilisé. Une variable aléatoire ξ réelle qui est une fonction de Θ dans R est associée à une loi de probabilité Pξ : 1 ξ ( ) ( ( )) U U ξ − P = PΘ (1.1) avec U appartient à une tribu B de R. On note F x x ( ) ( ) ξ ξ = ≤ P ξ la fonction de répartition de ξ de R dans [0 ; 1]. Dans le cas où la loi de probabilité de ξ admet la relation suivante : Notions sur la théorie des probabilités 16 ( ) ( ) x x f t dt ξ ξ ξ −∞ ≤ = ⋅ P ∫ (1.2) avec fξ de R dans [0 , +∞[ alors fξ est appelée fonction de densité de probabilités de ξ. Dans le cadre de cette thèse, on ne considère que des variables aléatoires qui admettent (1.2). On peut définir aussi les quantités souvent utilisées dans ce mémoire : • L’espérance de ξ : [ ] f x dx ( ) ξ ξ ξ = ⋅ ⋅ E ∫ ℝ (1.3) qui permet d’obtenir la valeur moyenne de ξ. • La variance de ξ : 2 Var( ) ( ( ) ξ ξ ξ = − E E représente « l’amplitude » de l’oscillation de ξ autour de sa valeur moyenne. La racine carrée σξ de la variance est appelée écart-type de ξ. • Le moment d’ordre k de ξ est l’espérance de ξ k . • Le moment centré d’ordre k de ξ : ( ( ))k k δ ξ ξ = − E E . ◊ L’asymétrie de ξ : 3 3 ξ δ γ σ = avec δ3 le moment centré d’ordre 3 et σξ l’écart-type de ξ. ◊ Le coefficient d’aplatissement de ξ : 4 4 ξ δ β σ = avec δ4 le moment centré d’ordre 4 et σξ l’écart-type de ξ. • La covariance entre deux variables aléatoires ξ et κ : cov( , ) ( ) ( ) ξ κ ξ ξ κ κ = − ⋅ − [ ] [ ] E E E . Cette quantité permet d’évaluer le degré de dépendance entre ξ et κ. Dans le cas où ξ et κ sont indépendantes, la covariance est nulle. Le coefficient de corrélation est défini par : cov( , ) ξκ ξ κ ξ κ ρ σ σ = . A partir de la notion de variable aléatoire, on peut introduire la notion de vecteur aléatoire: 1 2 ( , ,.. ) d ξ = ξ ξ ξ de dimension d avec ξi , i=1 : d des variables aléatoires réelles. On note Od l’ensemble des valeurs du vecteur ξ qui est un sous-ensemble de R d (dans le cas de vecteur gaussien ξ, on a d d O ≡ R ). On note fξ la fonction de densité de probabilité de ce vecteur aléatoire. On peut définir une espace de Hilbert réel H d = L 2 (O d , fξ dξ) des fonctions g de O d dans R de carré intégrable par rapport à la mesure de probabilité fξ dξ muni du produit scalaire : , ( ) ( ) ( ) d d g h g h f d = ⋅ ⋅ H ∫ O ξ ξ ξ ξ ξ (1.4) et de la norme associée: 17 2 d ( ) ( ) d g g f x d = ⋅ H ∫ O ξ ξ ξ (1.5) 1.1.2 Chaos polynomial Cette partie est consacrée à une présentation générale de la notion de chaos polynomial [1]. Celui – ci est un outil utilisé dans les méthodes développées récemment pour propager des incertitudes au travers d’un modèle numérique. On considère une variable aléatoire Y dont la variance existe qui est une fonction d’un vecteur aléatoireξ = (ξ ξ 1 ,…, d ) : Y g = ( ) ξ (1.6) où i ξ , i=1 : d sont des variables aléatoires indépendantes et chacune suit une loi normale centrée réduite. Le vecteur aléatoire ξ = (ξ ξ 1 ,…, d ) peut être formé de données d’entrée incertaines d’un modèle dont Y est une grandeur de sortie d’intérêt. On note fξ la fonction de densité de probabilité de ξ. Lorsque la variance de Y existe, la fonction g appartient alors à l’espace hilbertien H d = L 2 (O d , fξ dξ). Dans la suite, on va rappeler comment on peut construire une base polynomiale de H d = L 2 (O d , fξ dξ) qui nous permettra d’approcher Y g = ( ) ξ .
Base hilbertienne de H d
On peut constater qu’une variable aléatoire est complètement déterminée lorsque celle-ci est écrite sous la forme d’une fonction de variables aléatoires connues. Lors de la résolution d’un modèle stochastique, il n’est pas évident de représenter exactement une variable aléatoire de sortie par une fonction des variables aléatoires d’entrée. Une technique utilisée régulièrement dans le calcul numérique consiste à chercher son approximation dans un espace vectoriel (cet espace est un sous espace vectoriel appartenant à l’espace contenant la fonction à approcher) de dimension finie. Cette technique nécessite d’abord la construction des fonctions de base de l’espace vectoriel. Revenons à notre problème, une base hilbertienne { , } hα α ∈N de H d introduite dans la partie 1.1.2 est définie de la façon suivante [37] : – hi est une fonction définie de O d dans R. – { , } i h i ∈N est un système orthonormal, ce qui signifie que : , i j ij d h h = δ H (1.7) avec 0 si 0 1 sinon ij i j δ − ≠ = – le sous espace engendré par l’ensemble ( i h ξ ) est dense dans L 2 (O d , fξ dξ), c’est-àdire : si , d 0 i g h = H pour tous i ∈N alors g = 0. 18 On a le théorème [37] suivant : Théorème 1: Soit { , } i h i ∈N une base hilbertienne de l’espace de Hilbert H d . Alors pour tout g dans H d on a : 0 i i i g g h +∞ = = ∑ (1.8) Les coefficients gi sont tels que : , d i i g g h = H (1.9) La détermination de g peut se ramener à la détermination des coefficients gi . Lors de la résolution numérique, on limite le calcul à un nombre fini de termes gi , i = 0 : P. On discutera du choix de P par la suite. Une estimation numérique de (1.9) peut être utilisée pour déterminer les coefficients gi . Dans la suite, on présentera une construction des polynômes orthogonaux multidimensionnels qui forment une base { , } i H i ∈N de H d à partir des polynômes monodimensionnels.
Polynômes de Hermite
Rappelons que dans cette partie fξ est la densité de probabilités du vecteur variable aléatoire ξ = (ξ ξ 1 ,…, d ) où j ξ , j=1 : d sont des variables aléatoires indépendantes dont chacune suit la loi normale centrée réduite. Dans ce cas d d O ≡ R . Une base { , } i H i ∈N de H d peut être construite en utilisant dans ce cas des polynômes de Hermite monodimensionnels comme on va le voir dans la suite. Polynômes de Hermite monodimensionnels : On note dans ce cas fξ la fonction de densité de probabilités de la variable aléatoire gaussienne ξ centrée réduite. La définition des polynômes de Hermite hi de R dans R d’indice i ∈N est la suivante : exp La construction de hi(ξ) peut être réalisée d’une façon récurrente à l’aide de l’équation (1.11). On donne à titre d’exemple les premiers polynômes de Hermite monodimensionels: On peut introduire les polynômes normalisés Hi (ξ) : On peut démontrer que la famille Hi (ξ), i ∈N est orthonormée, ce qui signifie que : Une fois les polynômes de Hermite unidimensionnels construits, on peut les associer pour former les polynômes de Hermite multidimensionnels. Polynômes de Hermite multidimensionnels : Revenons au cas où fξ est la densité du vecteur variable aléatoire ξ = (ξ ξ 1 ,…, d ) où j ξ , j =1 : d sont des variables aléatoires indépendantes dont chacune suit une loi normale centrée réduite. Un polynôme de Hermite multidimensionnel (ξ ) Hi avec 1 ( ,…, ) d d i = ∈ i i N est défini par : 1 2 1 2 ( ) ( ) ( ) ( ) d H H H i i i d ξ = ⋅ ⋅ ⋅ ⋅ ξ ξ ξ Hi (1.14) Le degré d’un polynôme 1 ( ,… ) ( ) d H i i ξ est défini par : p = i1+..+id. On a alors le nombre P de polynômes de degré inférieur ou égal à p qui vérifie: ( )! ! ! p d p d p P C d p + + = = (1.15) Pour simplifier la notation, on va noter ( α H ξ ) avec α ∈N au lieu de 1 2 ( , ,.. )( d i i i H ξ ) avec 1 2 ( , ,.. ) d d i i i ∈N ( voir [7] pour plus de détail concernant la relation entre α et i). On donne à titre d’exemple les 6 premiers polynômes de Hermite (p = 2) dans le cas d A partir de (1.13), on peut constater que la famille ( α H ξ )définie par (1.14) est orthonormée dans H d = L 2 (R d , fξ dξ). En utilisant le théorème de Martin-Cameron [13], on peut démontrer que le sous espace engendré par l’ensemble ( α H ξ ) est dense dans H d = L 2 (R d , fξ dξ). Par conséquent, ( α H ξ )forme une base Hilbertienne de H d . Dans la suite, on va utiliser cette base des polynômes de Hermite pour approcher une variable aléatoire Y de la forme (1.6). 1.1.2.3. Chaos polynômial On vient de rappeler dans la partie précédente que l’ensemble des polynômes de Hermite ( α H ξ ) forme une base hilbertienne de H d = L 2 (R d , fξ dξ) avec fξ, la densité conjointe du vecteur de variables aléatoires ξ = (ξ ξ 1 ,…, d ) où i ξ , i=1 : d sont des variables aléatoires indépendantes dont chacune suit la loi normale centrée réduite. En utilisant le théorème 1, une variable aléatoire Y= g(ξ) dont la variance existe peut être approchée par : (1.16) Les coefficients gα, à déterminer, peuvent s’écrire sous la forme : , ( ) fois que Y est approchée par (1.16) les informations sur Y (différents moments, fonction de densité de probabilité, etc.) peuvent être obtenues aisément. Cela peut nécessiter l’évaluation des termes α α α 1 2 n ⋅⋅ E H H H . Dans l’annexe 2, une méthode semi analytique est présentée pour réaliser cette évaluation. Puisque on a lim ( ) ( ) P P →∞ g g ξ ξ = , alors si P est suffisamment grand, on peut obtenir une approximation ( ) P g ξ de g(ξ) avec une erreur suffisamment faible. On ne connait pas g(ξ) mais 21 une méthode pour évaluer la qualité de l’approximation consiste à comparer ( ) P g ξ et ( ) P k g ξ + , k=1 : N0 (N0 peut être choisi egal à 1 ou plus si la fonction à approximer possède des symétries). Si la distance entre ( ) P g ξ et ( ) P k g ξ + est faible, l’approximation pourra être considérée comme correcte. Pour des cas particuliers, on peut disposer d’un estimateur d’erreur qui nous permet d’avoir la distance avec la solution exacte [18]. Dans certains cas où g( ) ξ prend une forme « peu régulière » [30], la convergence lim ( ) ( ) P P →∞ g g ξ ξ = peut être très lente. Ces cas nécessitent des traitements adaptés pour accélérer la vitesse de convergence. Ce phénomène est discuté dans le chapitre 2. Dans [14], il est montré qu’une généralisation est possible avec des lois non gaussiennes. On a dans ce cas ξ = (ξ ξ 1 ,…, d ) où i ξ , i=1 : d sont des variables aléatoires indépendantes. Les fonctions de densité de probabilités i f ξ de i ξ , i=1 : d sont identiques. La fonction i f ξ peut être la fonction de densité d’une loi Beta, uniforme, etc… Dans ce cas, une autre famille de polynômes monodimensionnels ( ) k ψ ξ i k va être mise en œuvre (voir le Tableau 1 extrait de [14]). Les polynômes multidimensionnels sont établis à partir de ces polynômes monodimensionnels par : Dans le reste de cette thèse on note ( ) Ψα ξ avec α ∈N le chaos polynomial généralisé.