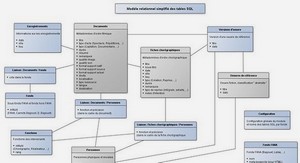
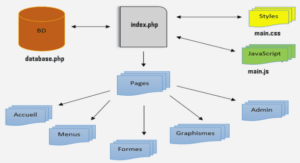
Le modèle relationnel
En 1970, E. Codd publie l’article de référence posant les bases du modèle relationnel [COD 70]. D’un seul coup, toutes les limitations des précédents modèles sont résolues. Le but initial de ce modèle était d’améliorer l’indépendance entre les données et les traitements. Cet aspect des choses est réussi et avec ça d’autres fonctionnalités apparaissent : ●● Normalisation (dépendances fonctionnelles) et théorie des ensembles (algèbre relationnelle). ●● Cohérence des données (non-redondance et intégrité référentielle). ●● Langage SQL (déclaratif et normalisé). ●● Accès aux données optimisé (choix du chemin par le SGBD). ●● Indexation, etc. Les liens entre les enregistrements de la base de données sont réalisés non pas à l’aide de pointeurs physiques, mais à l’aide des valeurs des clés étrangères et des clés primaires. Pour cette raison, le modèle relationnel est dit « modèle à valeurs ».Comment déduire de telles relations entre les tables ? C’est précisément à quoi sert le processus de modélisation que nous allons vous présenter tout au long de cet ouvrage.
La force de ce modèle de données réside dans le fait qu’il repose sur des principes simples et permet de modéliser des données complexes. Le modèle relationnel est à l’origine du succès que connaissent aujourd’hui les grands éditeurs de SGBD, à savoir Oracle, IBM, Microsoft et Sybase dans différents domaines : ●● OLTP (OnLine Transaction Processing) où les mises à jour des données sont fréquentes, les accès concurrents et les transactions nécessaires. ●● OLAP (Online Analytical Processing) où les données sont multidimensionnelles (cubes), les analyses complexes et l’informatique décisionnelle. ●● Systèmes d’information géographiques (SIG) où la majorité des données sont exprimées en 2D ou 3D et suivent des variations temporelles.
Les modèles NoSQL
Depuis quelques années, le volume de données à traiter sur le Web a mis à rude épreuve les SGBD relationnels, qui ont été jugés non adaptés à de nombreuses montées en charge. Les grands acteurs du Big Data, comme Google, Amazon, LinkedIn ou Facebook, ont été amenés à créer leurs propres systèmes de stockage et de traitement de l’information (BigTable, Dynamo, Cassandra). Des implémentations d’architectures open source comme Hadoop et des SGBD comme HBase, Redis, Riak, MongoDB ou encore CouchDB ont permis de démocratiser ce nouveau domaine de l’informatique répartie. On distingue plusieurs modèles de données parmi les SGBD NoSQL du moment : clé-valeurs, orienté colonnes, documents et graphes. Plus le modèle est complexe, moins le système est apte à évoluer rapidement en raison de la montée en charge.
Modèle de données clé-valeurs
Le mode de stockage du modèle clé-valeurs (key-value) s’apparente à une table de hachage persistante qui associe une clé à une valeur (de toute nature et de type divers, la clé 1 pouvant référencer un nom, la clé 2 une date, etc.). C’est à l’application cliente de comprendre la structure de ce blob. L’intérêt de ces systèmes est de pouvoir mutualiser cette table sur un ou plusieurs serveurs. Les SGBD les plus connus sont Memcached, CouchBase, Redis et Voldemort (LinkedIn).
Modèle de données orienté colonnes
Le modèle orienté colonnes ressemble à une table dénormalisée (sans la présence de NULL, toutefois) dont la structure est dynamique. Les SGBD les plus connus sont HBase (implémentation du BigTable de Google) et Cassandra (projet Apache qui reprend à la fois l’architecture de Dynamo d’Amazon et BigTable).
Modèle de données orienté documents
Le modèle orienté documents est toujours basé sur une association clé-valeur dans laquelle la valeur est un document (JSON généralement, ou XML). Les implémentations les plus populaires sont CouchDB (Apache), RavenDB, Riak et MongoDB
Modèle de données orienté graphes
Le modèle de données orienté graphes se base sur les nœuds et les arcs orientés et éventuellement valués. Ce modèle est très bien adapté au traitement des données des réseaux sociaux où on recherche les relations entre individus de proche en proche. Les principales solutions du marché sont Neo4j (Java) et FlockDB (Twitter).