Arbre de décision
Terminologie et origine
L’arbre de décision [9] est une méthode qui a pris essentiellement son essor dans le cadre des approches d’apprentissage automatique ou « machine learning » en intelligence artificielle.
C’est une technique du groupe d’« Apprentissage supervisé ou classification supervisée ». Il s’agit de trouver avec le plus de précision possible les valeurs prises par la variable à prédire (objectif, variable cible, variable d’intérêt, attribut classe ou variable de sortie) à partir d’un ensemble de descripteurs (variables prédictives, variables discriminantes ou variables d’entrées) [10][11].
C’est en même temps un outil d’aide à la décision et à l’exploration de données et une structure souvent utilisée pour représenter les connaissances [12]. Il permet de modéliser simplement, graphiquement et rapidement un phénomène mesuré plus ou moins complexe. Sa lisibilité, sa rapidité d’exécution et le peu d’hypothèses nécessaires à priori expliquent sa popularité actuelle. Ses premiers objectifs sont laClassification et la prédiction.
Fonctionnement
Leur fonctionnement est basé sur un enchaînement hiérarchique de règles exprimées en langage courant.
Le schéma ci-après (figure 1) représente la constitution générale d’un Arbre de décision. Celui-ci est constitué :
• D’un nœud racine qui est le point de départ de l’arbre ;
• Des nœuds feuilles ou nœuds terminaux représentant les classes qui sont constituées par un ensemble de pixels ;
• Des nœuds non-terminaux qui sont associés à une question ;
• Des réponses associées aux branches menant aux enfants d’un nœud non-terminal.
Le jeu de questions et réponses est itératif jusqu’à ce que l’enregistrement arrive à un nœud feuille.
Règle de classification
Il faut partir de la racine à une feuille en effectuant des tests lorsqu’on arrive à trouver un nœud [11].
Classe d’une feuille
On affecte à la feuille la classe qui est majoritaire parmi les parcelles d’apprentissage appartenant à cette feuille [11].
Critère de division d’un nœud: choix d’attribut (bande) et test (seuil de séparabilité)
Pour le choix de l’attribut et le test pour la division d’un nœud, il faut mesurer l’indice d’hétérogénéité du nœud candidat [11]. Dans notre cas, cette mesure se fait par le calcul de la valeur de « ratio » pour le classificateur C4.5, de « entropy» pour le classificateur ID.3 et de « Gini »pour le classificateur CART.
A chaque nœud, cette mesure essaie de trouver une division qui maximise le gain d’homogénéité ou information obtenue. Plus les valeurs obtenues par ces indices d’hétérogénéité sont grandes pour une bande ou une classe, plus cette bande ou cette classe est hétérogène.
Construction de l’arbre à partir des parcelles d’apprentissage
principe de construction d’un arbre de décision
Les classificateurs cherchent en premier lieu la bande la plus hétérogène, c’est-à-dire la bande qui met en évidence les classes existantes, en calculant les indices d’hétérogénéité des bandes comme « entropy » du classificateur ID.3, « ratio » du classificateur C4.5 et « Gini» du classificateur CART. Ils la mettent dans la racine. Ensuite, ils cherchent la classe la plus homogène parmi les classes existantes dans cette bande et ils prennent comme seuil de séparabilité les valeurs maximales ou minimales de cette classe selon les cas. Pour la suite, il fait les mêmes opérations en tenant compte les autres classes restantes et ainsi de suite.
Estimation du coût d’un arbre
Il existe beaucoup de critères d’élagage tel que le« coût de l’arbre » qui consiste à calculer le taux d’erreur d’un nœud [14]. Mais la méthode la plus facile consiste à calculer le pourcentage des pixels bien classifiés dans une feuille. C’est à partir de ce pourcentage en spécifiant des seuils qu’on supprime certaines branches après la construction de l’arbre maximal. On élimine à partir de cette phase les nœuds qui ont un pourcentage inférieur ou égal au seuil donné au préalable. Le pourcentage des pixels contenus dans une feuille est donné par la formule suivante :
Classificateur CART
CART est un des classificateurs à arbre de décisionqui signifie « Classification And Regression Trees »ou bien « Arbre de Classification et Régression». Il a été créé par Leo Breiman en 1984 [17]. Pour le classificateur CART, si la variable de classification est numérique, on fait la régression ; sinon on fait la classification. Dans le cas de la classification d’image numérique, la variable de classification utilisée est toujours catégorique et la mesure de division correspondant à cette variable est la mesure de « Gini-index» ou « indice de Gini» ou « Gini ».
Troisième étape : Application de la décision
Après toutes ces opérations, on a obtenu la décision et on applique à toutes les images disponibles pour effectuer la classification. Il faut alors élaborer à partir de cette décision un programme en C ou en Matlab pour pourvoir tester chaque pixel de chaque bande. Tous les pixels sont testés dans cette décision et sont affectés chacun à une classe. Au cas où il existe encore des pixels non classés, l’algorithme les met dans une classe à part, par exemple « classe 10 ». A la sortie de cette décision, on obtient l’image classifiée.
Géographie
Le territoire du canton de Genève est petit: 282 km2 . Il forme une enclave entourée de territoires français, à savoir le département de la Haute-Savoie au sud, celui de l’Ain au Nord. La continuité territoriale avec la Suisse est assurée par une bande de territoires reliant Genève au canton de Vaud par le bord du lac Léman. La partie du lac Léman qui relève du canton de Genève occupe 38 km2.On l’appelle le «Petit lac».Genève est située entre Alpes et Jura, à l’extrémité sud-ouest de la Suisse et du lac
Léman. Le Rhône et l’Arve sont les deux principaux cours d’eau qui la traversent. L’altitude de la Ville de Genève est de 373 m.
Actuellement, la Ville compte plus de 188.000 habitants. Le canton quant à lui dépasse les 453.000 habitants. Le territoire genevois dénombre neuf autres villes: Vernier (32.000), Lancy (28.000), Meyrin (21.000), Carouge (19.000), Onex (17.000), Thônex (13.000), Versoix (13.000), Grand-Saconnex (11.000)et Chêne-Bougeries (10.000).
En Suisse, c’est Genève qui compte le plus grand nombre d’étrangers dans sa population: environ 45% représentant près de 180 nationalités [18].
Climat
À Genève, à l’instar d’une grande partie de l’Europe, l’hiver est froid et généralement peu ensoleillé. Au cours de la saison, on peut observer à quelques reprises plusieurs jours sans dégel ainsi qu’un jour ou deux avec des fortes gelées où le thermomètre affiche -10 °C.
Lorsque la bise se met à souffler, la sensation de froid est accentuée et peut rendre parfois les conditions assez rudes. Le soleil reste relativement rare car masqué par des stratus ou par le brouillard. On en observe plusieurs jours par mois et, en cas de conditions anticycloniques stables, ils peuvent persister durant plusieurs jours. Dès le mois de mars, les températures augmentent et deviennent presque estivales fin mai. Cependant, les précipitations s’intensifient et prennent souvent un caractère orageux au cours du mois de mai. Ces orages Algorithmes à arbre de décision appliqués à la classification d’une image satellite peuvent être brefs mais forts et déverser en quelques minutes plusieurs dizaines de millimètres de pluie. Les étés sont souvent chauds et plutôt humides même si certains peuvent être plus frais. Les matinées restent, quant à elles, relativement fraîches. Durant la saison, les pluies se font moins fréquentes mais plus intenses. C’est en effet la saison des orages exceptionnellement accompagnés de grêle. Si le climat de début septembre est encore estival, le temps se refroidit ensuite rapidement pour devenir quasiment hivernal en novembre. Les gelées matinales font alors leur réapparition. L’automne est également la saison des brouillards, le mois d’octobre étant souvent le mois où il y a le plus de brouillards dans l’année [18].
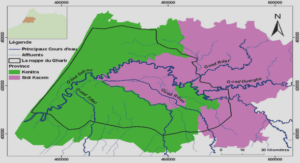
Climat et réseau hydrographique
Le climat est du type tropical subhumide dans la partie occidentale de l’aire protégée et de type tropical chaud et humide sur le versant oriental. Les précipitations sont très abondantes et varient de 1800-2000mm par an. Le versant oriental étant exposé aux cyclones tropicaux, les pluies peuvent atteindre facilement 4000mm en saison cyclonique. La température, influencée par l’altitude, peut atteindre un maximum de 35°C sur le versant Est, et atteindre 6°C en période fraîche sur la partie occidentale.
L’Aire Protégée de Zahamena joue un rôle important dans le cycle hydrographique régional, et constitue le château d’eau de la région de l’Alaotra-Mangoro. Le Parc fait partie du site Ramsar qui couvre le bassin versant du Lac Alaotra. Zahamena est drainée par des petits torrents développés, coulant dans des lits encombrés de granite et de gneiss qui alimentent les deux grands fleuves Onibe et Maningory [19].
Relief et géomorphologie
Le complexe Aire Protégée de Zahamena est constitué par un relief fortement accidenté. Son altitude varie de 244m à 1550m (Conservation International, 1999). Du point de vue géomorphologie, cette région est caractérisée par des nombreux bassins versants avec très peu de bas fond en bordure des rivières. Les pentes peuvent dépasser 70% [19].
Faune
Le versant oriental est reconnu comme étant riche en diversité faunistique. Les animaux sont en particulier abondants au niveau des aires protégées et la forêt en général. Pour Zahamena, il abrite une proportion significative d’espèces endémiques représentatives de l’écorégion de l’est : 13 espèces de Lémuriens, 35 espèces de Micromammifères, 112 espèces d’Oiseux, 46 espèces de Reptiles, 29 espèces de Poissons, 62 espèces d’Amphibiens, 425 espèces d’Insectes. Zahamena est constitué par des forêts les plus riches en Reptiles et Amphibiens (Conservation International, 1999 et Glaw f. et Vences M., 2007). Nous pouvons citer entre autres, les géants Lémuriens (Indri indri, Propithecus diadema diadema ) et les Lémuridae diurnes (Varecia variegata variegata, Eulemur fulvus, Eulemu r rubriventer ). Le petit Lémuriens Allocebus trichotis ne se rencontre que dans la vallée de Namafarana (secteur I, RNI Zahamena), les autres Mammifères (Viverricula indica, Cryptoprocta ferox, Potamochoerus ). Parmi les autres classes, les Oiseaux sont représentés par Coua reynaudii, Coua caerula, Falco newtoni, Cuculu s rochii, Dicrurus forficatus, Corvus albus ; les Reptiles par Chamaeleo nasutus, Amphiglosus melanopleura, Sanzinia madagascariensis, Phelsuma bimaculata et les Amphibiens par Mantidactylus guttalatus, Boophis viridis, Mantella cowani, Ptychadena mascar eniensis.
Images utilisées
Nous avons utilisé pour l’illustration les deux images suivantes : image SPOT de Genève et image LANDSAT de l’Alaotra, dont les images et leurs caractéristiques sont les suivantes:
Sélection des bandes
Les bandes utilisées pour cette sélection sont : les bandes spectrales (3 pour l’image SPOT de Genève et 6 pour l’image LANDSAT de l’Alaotra), les bandes NDVI, les deux premières composantes de l’ACP (Analyse en Composantes Principales) et les bandes textures obtenues par les bandes infrarouges pour les deux images LANDSAT de l’Alaotra et SPOT de Genève.
Image SPOT de Genève
Les résultats de la sélection pour l’image SPOT de Genève sont consignés dans les tableaux XIV, XV, XVI et XVII suivants :
DISCUSSIONS
Comparaison des différents classificateurs à arbre de décision
Dans la comparaison des classificateurs, nous avons utilisé le seuil d’élagage par défaut, c’est-à-dire le seuil d’élagage de 1%, un même seuil d’élagage pris arbitrairement et les seuils d’élagage optimaux pour les trois classificateurs à arbre de décision. Ces derniers ne sont pas toujours les mêmes pour les classificateurs donnés.
Pour l’image SPOT de Genève
La comparaison des tableaux IX et X, relatifs aux classificateurs à arbre de décision, montre que le choix des valeurs des seuils d’élagage influe sur les résultats. En général, les seuils d’élagage par défaut (1%) ne conduisent pas à de bons résultats de classification : kappa allant de 0,8658 à 0,8698, précisions globales de 92,01% à 92,25% (tableau IX). Pour cette même valeur du seuil d’élagage, les résultatssont différents pour C4.5, ID.3 et CART.
Les informations y sont moindres par rapport à celles du classificateur ID.3. Pour d’autres valeurs de seuil, par exemple 1,5%, les résultats avec ces 3 classificateurs s’améliorent : kappa allant de 0,8697 à 0,8749 et précisions globales allant de 92,25 à 92,55%. ID.3 est toujours le plus performant pour cette valeur du seuil d’élagage avec des différences de précision globale inférieures ou égales à 0.25%, ceux qui sont faibles (tableau X). On remarque que ce seuil d’élagage (1,5%) est une valeur à la quelle les résultats obtenus, valeurs de kappa et précisions globales (tableau X), pour chaque classificateur à arbre de décision atteignent leurs valeurs maximales. Au delà de ce seuil les résultats ne sont pas donc satisfaisants.
Toutefois, lorsqu’ on analyse les images obtenues et les valeurs des erreurs d’omission (tableau X et figure 7), certaines classes sont mal classifiées par le classificateur ID.3 telles que les classes 1, 6 et 8, respectivement « Eau de lac » , « Bâtiment » et « Eau de l’Arve » qui ont des valeurs respectives de 0,0007, 0,3803 et 0,2358 comparées respectivement à 0,0000, 0,3732 et 0,1792 obtenues par le classificateur C4.5, la classe 9, « Voiries », avec une valeur de 0,1925 comparée à 0,1818 du classificateur CART et la classe 3, « Espaces verts » qui a une valeur de 0,4457 comparées à celles desclassificateurs C4.5 et CART. Pour la classe 3, « Espaces verts » , ces valeurs sont respectivement égales à 0,4171 et 0,3429 avec C4.5 et CART.
Image LANDSAT de la région de l’Alaotra
La comparaison des tableaux XI, XII et XIII, relatifs aux classificateurs à arbre de décision, montre que le choix des valeurs du seuil d’élagage influe aussi sur les résultats. En général, les seuils d’élagage par défaut (1%) ne conduisent pas à de bons résultats de classifications : kappa allant de 0,8965 à 0,9141, précisions globales de 91,31% à 92,79%(tableau XI).
Pour les mêmes valeurs du seuil d’élagage, 1% (tableau XI) et 3,5 % (tableau XII), les résultats sont différents pour C4.5, ID.3 et CART. Les informations y sont moindres par rapport à celles du classificateur ID.3. Mais pour le cas du seuil de 3,5% (tableau XII), les résultats de ces 3 classificateurs sont supérieurs par rapport à celles obtenus en utilisant le seuil de 1%: kappa allant de 0,9064 à 0,9277 et précisions globales de 92,13 à 93,93%.
Pour d’autres valeurs de seuils, surtout en utilisant les 3,5%, 10% et 15% (tableau XIII) respectivement pour les classificateurs CART, C4.5 et ID.3, les résultats de ces 3 classificateurs sont supérieurs par rapport aux 2 seuils (1% et 3,5%) : kappa allant de 0,9064 à 0,9414 et précisions globales de 92,13 à 95,08%. C4.5 et ID.3 conduisent aux mêmes résultats pour des valeurs de seuils d’élagage de 10 et 15% respectivement. D’après ces valeurs, les Algorithmes à arbre de décision appliqués à la clas sification d’une image satellite classificateurs C4.5 et ID.3 apportent les meilleurs résultats, ils ont une différence de précision globale de 2,95% par rapport au classificateur CART.
En regardant les images classifiées et en analysantles erreurs d’omission pour ces trois classificateurs (tableaux XIII et figure 8), on constate que les valeurs obtenues par les classificateurs C4.5 et ID.3 sont plus petites par rapport à celles obtenues par le classificateur CART. Mais si on fait une comparaison entre les classificateurs C4.5 et ID.3, on trouve, d’une part, que la classe 2, « Sols nus », est bien classifiée par le classificateur C4.5 et d’autre part, la classe 8, « Sable », est bien classifiée par ID.3. Pour la classe 2,« Sols nus », ces valeurs sont égales à 0,3846 et 0,4103 avec les classificateurs C4.5 et ID.3 respectivement. Pour laclasse 8,« Sable »,elles sont respectivement de 0,0370 et de 0,0247.
La valeur d’élagage 3,5% (tableau XII) est une valeur prise arbitrairement pour les trois classificateurs, mais si on cherche les seuils qui apportent chacun des meilleurs résultats comme dans le tableau XIII, pour les classificateurs C4.5 et ID.3, ils ont les mêmes valeurs dekappa et de la précision globale qui sont respectivement égales à 0,9414 et 95,08%. Les seuils d’élagage sont toutefois différents avec ces deux classificateurs. Pour le classificateur C4.5, ce seuil est de 10% et pour le classificateur ID.3, ilest de 15%. Pour le classificateur CART, les valeurs de kappa et de précision globale sont respectivement égales à 0,9064 et 92,13% en supprimant les feuilles qui ont des proportions inférieures ou égales à 3,5%. D’après ces valeurs, les classificateurs C4.5 et ID.3 apportentles meilleurs résultats, ils ont une différence de précision globale de 2,95% par rapport au classificateur CART (tableau XIII).
Le classificateur ID.3 est plus performant dans unezone plus ou moins homogène.
En général, les classificateurs à arbre de décisionrencontrent certains problèmes dans le cas où une classe est hétérogène, c’est-à-dire quand l’écart type de cette classe est grand, comme le montre l’exemple de la classe 2, « Sols nus », qui est mal classifiée. Son écart type va de 5,618 à 56,224 pour les 6 bandes utilisées (tableauXXVI). Le choix de ce seuil occupe un peude temps, par exemple, le choix du seuil allant de 0 à 10% par rapport à un seuil allant de 0 à 3,5%. Le classificateur C4.5 est donc plus performant par rapport à ID.3 dans ce cas, car il aun seuil d’élagage plus petit par rapport à ID.3.
Image LANDSAT de la région de l’Alaotra
Les images et les valeurs des erreurs d’omission obtenues (tableaux VIII, XI et XII et figure 8) avec les classificateurs à arbre de décision, avec des seuils d’élagage donnés, comparées avec l’image obtenue avec MDV montre que certains pixels sont mal classifiés sur l’image de MDV : classe 2, « Sols nus » et classe 8, « Sable». Certains pixels de la classe 2, « Sols nus », sont confondus avec ceux de la classe 6 et 8, « Pseudo steppes » et « Sable », et même pour la classe 8, « Sables », confondus avec la classe 2, « sols nus »(tableaux VII).
Les erreurs d’omission pour MDV et les trois classificateurs avec seuil d’élagage égal à 1% (tableaux VIII et XI) sont toutes égales à 0 pour les classes 3 et 4 : « Savanes herbeuses » et « Forêts denses » . Le classificateur MDV est performant pour la classe 6, « Pseudo-steppes », qui a une erreur d’omission de 0.1882 par rapport aux trois autres classificateurs C4.5, ID.3 et CART (erreurs d’omission respectivement de 0.2000, 0.2235 et 0.2000).
Les résultats d’erreurs d’omission égales à 0 pour les classes 4 et 5, « Forêts denses » et « formations Marécageuses » , (tableau XIII) montrent la qualité des classificateurs à arbrede décision pour ces types d’occupation des sols.
La comparaison des valeurs de kappa et des précisions globales (tableaux VIII, XI, XII et XIII), montre que celles obtenues avec MDV sont toutes inférieures à celles obtenuesavec les classificateurs à arbre de décision.
Image LANDSAT d’Alaotra
Le classificateur C4.5 (tableaux XVIII et XXI) sélectionne les 8 bandes parmi les 43 disponibles, avec un seuil d’élagage de 8% et des valeurs de kappa et précision globale respectives de 0,9394 et 94,92%. Les erreurs d’omission pour ce classificateur sont toutes inférieures à celles obtenues avec les deux autres classificateurs à arbre de décision sauf pour la classe 2, « Sols nus » , qui a une valeur de 0,4103, supérieure à celle obtenue avec ID.3, avec une erreur d’omission de 0,3846.
Le nombre de bandes sélectionnées avec le classificateur ID.3 (tableaux XIX et XXI) est le même que celle obtenu par le classificateur C4.5 mais avec un seuil d’élagage de 9 à10%. Les valeurs de kappa et précision globale sontrespectivement de 0,9317 et 94,26%. Par contre, le classificateur CART sélectionne les 9 bandes, avec un seuil de 4%, des valeurs de kappa et de précision respectives de 0,9063 et 92,13% (tableaux XX et XXI). Les erreurs d’omission obtenues avec le classificateur CART sont toutes élevées.
En général, le classificateur C4.5 apporte les meilleurs résultats de sélection, un nombre de bande inférieur et de valeurs de kappa et précision globale élevées par rapport aux deux autres classificateurs à arbre de décision.
En faisant seulement les raisonnements avec 10 bandes pour l’image LANDSAT de l’Alaotra (tableaux XXII, XXIII et XXIV) et en regardant les figures 11, 12 et 13 ci-après, onconstate qu’il y a une relation entre les bandes sélectionnées et les signatures spectrales. Car les 5 et 6 bandes sélectionnées respectivement par ID.3 et C4.5 montrent que les signatures spectrales des classes pour les bandes sélectionnées sont bien différenciées.
Table des matières
SOMMAIRE
LISTE DES TABLEAUX
LISTE DES FIGURES
LISTE DES SIGLES ET DES ABREVIATIONS
INTRODUCTION
I. MATERIELS ET METHODES
I.1. Intelligence artificielle
I.2. Arbre de décision
I.3. Principe général des classificateurs à arbre de décision
I.4. Classificateurs utilisés
I.5. Logiciels utilisés
I.6. Mise en œuvre de l’arbre de décision avec Matlab
I.7. Exploitation des classificateurs à arbre de décision pour la sélection des bandes pour effectuer une classificatio
I.8. Données utilisées
II. RESULTATS
II.1. Résultats obtenus par MDV
II.2. Classification à l’aide des trois classificateurs à arbre de décision (ID.3, C4.5 et CART)
II.3. Sélection des bandes
III. DISCUSSIONS
III.1. Comparaison des différents classificateurs àarbre de décision
III.2. Comparaison entre le classificateur MDV et les classificateurs à arbre de décision
III.3. Sélection des bandes
III.4. Avantages et inconvénients de l’arbre de décision
CONCLUSION
BIBLIOGRAPHIE
TABLE DES MATIERES
![]()