Méthodes de sélection dynamique pour l’optimisation de portefeuille d’actifs financiers
Methodes d’Optimisation utiles en Finance
Introduction
A l’instar de beaucoup de domaines telle que la Finance, en particulier, l’Optimisation joue un rôle essentiel. Dans ce chapitre, l’objectif est de passer en revue les méthodes d’Optimisation les plus utilisées en Finance. C’est ainsi que l’Optimisation linéaire et non linéaire, l’Optimisation quadratique, l’Optimisation conique, la programmation en nombres entiers, la programmation dynamique, la programmation stochastique et enfin l’Optimisation robuste seront respectivement abordées dans ce chapitre. 2.2 Optimisation linéaire et non linéaire L’Optimisation Linéaire (OL) est l’un des types d’optimisation de base. C’est sans doute le plus connu et celui qui a le plus résolu de problèmes d’optimisation. Elle doit Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Optimisation linéaire et non linéaire 24 sa popularité et surtout son grand succès aux problèmes du monde réel (Transport, Sociologie, Economie, Finance . . . ) qu’elle a formulés et solutionnés. Définition 2.1. Dans un problème d’(OL) la fonction objectif à optimiser est linéaire et les contraintes d’égalité et/ou d’inégalité sont linéaires. Un problème d’optimisation linéaire générique a la forme standard suivante : min z c T z s.c. Az = b z ≥ 0 (2.1) où A ∈ R n×m, b ∈ R m, c ∈ R n et c T sa transposée sont donnés, et z ∈ R n est le vecteur à déterminer. Dans ce document un vecteur k est vu comme une matrice k × 1. D’où la formulation c T donnée ci-dessus est une matrice 1 × n et c T z est une matrice 1 × 1 équivalent à Pn j=1 cjzj . Ainsi l’objectif du problème (2.1) est de minimiser la fonction linéaire Pn j=1 cjzj . Définition 2.2. On parle d’Optimisation non-linéaire dans le cas où la fonction objectif et/ou l’une au moins des contraintes du problème (2.1) est non-linéaire. Remarque 2.1. – Le problème (2.1) dit être faisable si ses contraintes sont cohérentes – Lorsqu’il existe une séquence de vecteurs possibles {z k} tel que c T z → −∞ alors le problème (2.1) est appelé sans limite. – Lorsque le problème (2.1) est faisable alors il a une solution optimale c’est-à-dire un vecteur z qui satisfait les contraintes et minimise la valeur objective parmi tous les vecteurs possibles.
La méthode du simplexe
Une des méthodes les plus connues et les plus efficaces pour résoudre les problèmes d’(OL) est la méthode du simplexe. On peut aussi citer celui du point intérieur (voir section 2.3.3). Les problèmes d’Optimisation non linéaire quant à eux peuvent être résolus en utilisant les techniques de recherche de gradient ainsi que des approches basées sur la méthode de Newton comme du point intérieur et les méthodes de programmation quadratique séquentielles. Cornuejols [18] présente sous tous ses aspects cette méthode. Nous introduisons dans ce qui suit la notion essensielle de dualité. Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Optimisation linéaire et non linéaire
Problème primal, problème dual
Définition 2.3. Le dual du problème (2.1) appelé primal, s’écrit : DL : max y b T y s.c. AT y ≤ c (2.2) où y ∈ R m. Remarque 2.2. Le dual du dual est le primal. Théoréme 2.1. (Théorème de la dualité faible) Soit z une solution réalisable du problème primal PL (2.1) et y une solution réalisable du problème dual (DL) (2.2) alors c T z ≥ b T y Démonstration. On a z ≥ 0 et c−AT y ≥ 0 d’où le produit scalaire de ces deux vecteurs ne peut être négatif : (c − A T y) T z = c T z − y TAz = c T z − y T b ≥ 0 Définition 2.4. La quantité c T z − y T b est souvent appelée écart de dualité. Les trois résultats suivants sont des conséquences immédiates du théorème de la dualité faible. Corollaire 2.1. Si le primal est sans limite, alors le dual est irréalisable. Corollaire 2.2. Si le dual est sans limite, alors le primal est irréalisable. Corollaire 2.3. Si z est réalisable pour le primal, y est réalisable pour le dual, et c T z = y T b , alors z est optimale pour le primal et y aussi est optimal pour le dual.
Conditions d’optimalité
Théoréme 2.2. (Théorème de la dualité forte) Si le problème primal a une solution optimale z, alors le dual a une solution optimale y tel que c T z = b T y Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Optimisation quadratique 26 Démonstration. Voir le manuel de Chvátal [16] Le théorème de dualité forte nous donne des conditions optimales pour identifier les solutions optimales (appelé conditions d’optimalité) : z ∈ R n est une solution optimale du problème (2.1) si et seulement si 1. z est primal réalisable : Az = b, z ≥ 0 et il existe y ∈ R tel que : 2. y est dual réalisable : AT z ≤ c, et 3. Il n’y a aucun écart de dualité : c T z = b T y 2.3 Optimisation quadratique Définition 2.5. L’optimisation quadratique (QP) consiste en la minimisation d’une fonction objectif quadratique sous des contraintes linéaires. La forme standard est définie comme suit : DL : min z 1 2 z TQz + c T z s.c. Az = b z ≥ 0 (2.3) où A ∈ R m×n , b ∈ R m, c ∈ R n Q ∈ R n×n sont donnés, et z ∈ R n . 2.3.1 Dualité Comme dans l’Optimisation Linéaire, nous pouvons déterminer le dual de problèmes d’Optimisation Quadratique. Le dual du problème (2.3) s’écrit : DL : max z,y,s b T y − 1 2 z TQz s.c. AT y − Qz + s = c z, s ≥ 0 (2.4)
Conditions d’optimalité
Théoréme 2.3. Supposons que z est une solution optimale locale du problème (QP) (??) satisfaisant Az = b ; z ≥ 0 et supposons que Q soit une matrice semi-défini positive. Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Optimisation conique 27 Alors il existe des vecteurs y et s tels que les conditions suivantes sont vérifiées : A T y − Qz + s = c (2.5) z, s ≥ 0 (2.6) zisi = 0, ∀i (2.7) En plus z est une solution globale. Ces conditions sont couramment appelé conditions KKT (Voir section 6.3.1.) Remarque 2.3. Notons que la condition de semi-definitude positive liée à la Hessienne de la fonction de Lagrange dans le théorème KKT est automatiquement satisfaite pour des problèmes de programmation quadratique convexes et donc ne sont pas inclus dans le théorème 2.3 .
Methodes du point intérieur
En 1984, Narendra Karmarkar a prouvé que la méthode du point intérieur (IPM) peut résoudre les problèmes d’(OL) en temps polynomial. Dans les deux décennies suivant la publication de l’article de Karmarkar, Les chercheurs se sont penchés sur les propriétés théoriques et pratiques des (IPM). Une des premières découvertes fût que les (IPM) sont des modications de la méthode de Newton capable de gérer des contraintes d’inégalité. Nesterov et Nemirovski [54] ont montré que le mécanisme des (IPM) est appliquable à une large variété de problèmes pas seulement de types (OL). Par exemple, les (IPM) font de loin parti des meilleurs méthodes existantes pour les problèmes de programmation quadratique convexes ainsi que pour la plupart des problèmes d’optimisation conique (Voir section suivante). L’article de Karmarkar [41] et l’ouvrage de Cornuejols [18] étalent dans les détails cette méthode.
Optimisation conique
Eléments de rappel sur les cônes
Définition 2.6. Un ensemble C est un cône si λz ∈ C pour tout λ ≥ 0 et z ∈ C. Définition 2.7. Un cône est dit pointu s’il n’inclut aucune droite. Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Optimisation conique 28 Nous rencontrons généralement des cônes convexes, fermés et pointus. Voici quelques exemples : • Cl := z ∈ R n : z ≥ 0 l’orthant non négatif. En général, n’importe quel ensemble de la forme Cl := z ∈ R n : Az ≥ 0 avec A ∈ R m×n une matrice, est dit cône polyédral. L’indice l est utilisé pour indiquer que le cône est défini par des inégalités linéaires. • Cq := z = (z0, z1, z2, …, zn) ∈ R n+1 : z 2 1 ≥ ||(z1, …, zn)|| le cône du second ordre. Ce cône est aussi appelé le cône quadratique (d’où l’indice q), Lorenzt cône où cône crème glacée. • Cs := X = x11 … x1n . … . . … . xn1 … xnn ∈ R n n : X = XT , X semi − def inie positive le cône de matrices semi-définie positives symétriques. Si C est un cône dans un espace vectoriel X muni du produit scalaire noté h., .i, alors son cône dual est défini par : C ∗ := {z ∈ X : hz, yi ≥ 0, ∀y ∈ C}. (2.8) Il est facile de voir que l’orthant non négatif dans R n (avec le produit scalaire usuel) est égal à son cône dual. La même chose est valable pour le cône du second ordre et le cône de matrices semi définie positives symétriques. Le cône polaire est la négation du cône dual c’est-à-dire C P := {z ∈ X : hz, yi ≤ 0, ∀y ∈ C}. (2.9)
Problème d’Optimisation Conique (OC)
Définition 2.8. Considérons un cône C dans un espace vectoriel de dimension finie X, un problème d’optimisation conique s’écrit : min z c T z s.c. Az = b z ∈ C (2.10) Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Optimisation conique 29 où A ∈ R n×m, b ∈ R m, c ∈ R n et c T sa transposée sont donnés, et z ∈ R n est le vecteur à déterminer. Remarque 2.4. 1. Si X = R n et C = R n +, alors le problème (2.10) est de la forme des problèmes d’(OL). 2. Beaucoup de problèmes de programmation convexe formulés en terme de problèmes d’optimisation dite robuste conduisent aux problèmes (CO) [8] [9]. Remarque 2.5. Deux types importants de problèmes d’(OC) qui sont les plus rencontrés en finance sont : – l’optimisation de cône du second ordre et, – l’optimisation semi définie. Ce qui renvoie respectivement au cas où C est un cône du second ordre : Cq := z = (z1, z2, …, zn) ∈ R n : z 2 1 ≥ z 2 2 + … + z 2 n , z1 ≥ 0 (2.11) et un cône de matrices semi-définie positives symétriques : Cs := X = x11 … x1n . … . . … . xn1 … xnn ∈ R n n : X = X T , X semi − def inie positive (2.12) La récupération des probabilités risque-neutre à partir des prix d’options et l’Approximation de matrices de covariance sont entre autres des cas où interviennent l’optimisation conique. Dans ce qui suit, nous allons nous pencher en guise d’exemple sur l’approximation de matrices de covariance. 2.4.3 Approximation de matrices de covariance La matrice de covariance de vecteurs de variables aléatoires est l’un des descripteurs statistiques les plus importants et les plus utilisées du comportement conjoint de ces types de variables. Les matrices de covariance sont fréquemment rencontrées en mathématiques financières, par exemple, dans l’optimisation moyenne-variance, dans la prévision, dans la modélisation des séries temporelles, etc. Souvent, les vraies valeurs d’une matrice de covariance ne sont pas observables et on est obligé de se reposer sur des estimations de celles-ci. Litterman [44] dans son chapitre 16, traite cette question précise de l’estimation de matrices de covariance. Au contraire, ici, nous considérerons le cas où une estimation de la matrice de covariance est déjà fournie et nous nous intéresserons à la détermination d’une modification de cette estimation pour que cette dernière respecte certaines propriétés. Typiquement, on se focalisera sur la plus petite distorsion de l’estimation initiale qui réalise ces propriétés souhaitées. Ces propriétés structurales partagées par toutes les «matrices de covariance sont la symétrie et la semi-définitude positive (Voir section 5.2.2). Une matrice de corrélation quant à elle satisfait la propriété additionnelle que sa diagonale est constituée uniquement de 1. Dans certains cas, par exemple lorsque l’estimation de la matrice de covariance est effectuée entrée par entrée, l’estimation qui en résulte peut ne pas être une matrice semi-définie positive, ce qui signifie qu’elle peut avoir des valeurs propres négatives. L’utilisation d’une telle estimation suggère que certaines combinaisons linéaires des variables aléatoires sous-jacentes ont une variance négative et éventuellement cela entraîne des résultats désastreux dans l’optimisation moyenne-variance. D’où la nécessité de corriger de pareilles estimations avant qu’elles ne soient utilisés dans une prise de décisions financières. Soit S n l’espace des matrices symétriques n × n et Σb ∈ S n une estimation d’une matrice de covariance où Σb n’est pas nécessairement semi-définie positive. Dans ce dernier scénario, une question importante serait de définir la matrice semi-définie positive la plus proche de Σb . Ainsi, concrétement, on utilise la norme de Frobenius de la matrice de déformation en tant que mesure de proximité : dF (Σ, Σ) = b sX i,j (Σij − Σb ij ) 2 (2.13) Dès lors, nous pouvons poser le problème de matrice de covariance la plus proche de la manière suivante, selon Σb ∈ S n donné, min Σ dF (Σ, Σ) b s.c. Σ ∈ C n s (2.14) C n s est le cône de matrices symétriques semi-définies positives n×n. Remarquons que la variable de décision dans ce problème est représentée par une matrice et non un vecteur comme dans les toutes premières formulations de problèmes d’optimisation. D’un autre côté, avec l’introduction d’une variable muette t, le problème (2.14) peut Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 La programmation en nombres entiers 31 se réécrire comme suit : min t s.c. dF (Σ, Σ) b ≤ t Σ ∈ C n s (2.15) On peut voir que l’inégalité dF (Σ, Σ) b ≤ t peut être écrite comme une contrainte de cône de second ordre, et, par conséquent, la formulation ci-dessus peut ainsi être transformée en un problème d’optimisation conique. Des variantes de cette formulation (2.15) peuvent être obtenues par l’introduction de contraintes linéaires supplémentaires. A titre d’exemple, considérons un sous-ensemble E de paires de covariance (i, j) et supposons que nous voulons imposer à ces entrées des limites supérieure hij et inférieure bij ∀(i, j) ∈ E. Nous aurons donc à résoudre le problème suivant : min dF (Σ, Σ) b s.c. bij ≤ Σij ≤ hij , ∀(i, j) ∈ E Σ ∈ C n s (2.16) Lorsque E se compose de 1 sur toute sa diagonale (i, i) et hij = bij = 1 ; nous obtenons ainsi le problème avec la matrice de corrélation, une autre version problème original. Par exemple, des matrices de corrélation de dimension 3 ont la forme suivante : Σ = 1 x y x 1 z y z 1 , Σ ∈ C 3 s
La programmation en nombres entiers
Les programmes en nombres entiers sont des problèmes d’optimisation linéaires où les variables sont astreintes à prendre des valeurs entières. Un programme linéaire en nombres entiers (PLN) est donné par : min z c T z s.c. Az ≥ b z ∈ N (2.17) Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 La programmation en nombres entiers 32 où la matrice A ∈ R m×n , b ∈ R m, c ∈ R n sont donnés et z ∈ N n est le vecteur variable à déterminer. Un cas important se produit lorsque les variables zj représentent des variables de décision binaire, à savoir, z ∈ {0, 1} n . Le problème est alors appelé un programme linéaire en 0 − 1. Quand il y a en même temps des contraintes constituées de variables continues et des variables entières, le problème est appelé un programme linéaire mixte en nombres entiers (PLMN) : min z c T z s.c. Az ≥ b z ≥ 0 zj ∈ N, ∀j = 1, …, p (2.18) où A une matrice, b, c des vecteurs,sont donnés et l’entier p est part de l’entrée tel que 1 ≤ p < n.
Modélisation de conditions logiques avec la (PLN)
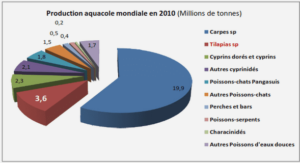
Le problème avec lequel nous allons travailler dans cette section est du type budgétisation du capital. Supposons que nous voulons investir 19 Millions de FCFA et que nous avons déjà identifié quatre opportunités d’investissement. L’opportunité 1 nécessite un investissement de 6,7 Millions de FCFA et a une valeur actuelle nette de 8 Millions de FCFA ; l’opportunité 2 exige 10 Millions de FCFA et a une valeur actuelle nette de 11 Millions de FCFA ; l’opportunité 3 exige 5,5 Millions de FCFA et a une valeur actuelle nette de 6 Millions de FCFA et enfin l’opportunité 4 qui nécessite 3,4 Millions de FCFA et a une valeur actuelle nette de 4 Millions de FCFA. Comment devrions-nous placer notre argent dans ces investissements de sorte à maximiser notre valeur actuelle nette totale ? Chaque projet se présente sous forme d’une opportunité à prendre ou à laisser : ce qui implique qu’il n’y a pas de possibilité d’investir de façon partielle dans ces projets. Nous allons ainsi utiliser une variable zj binaire pour chaque investissement. zj = 1 si on investit 0 sinon (2.19) Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 La programmation en nombres entiers 33 Cela conduit à un probleme de programmation 0-1. max 8z1 + 11z2 + 6z3 + 4z4 s.c. 6, 7z1 + 10z2 + 5, 5z3 + 3, 4z4 ≥ 19 zj = 0 ou 1 (2.20) Parmi les méthodes de résolution de ces types de programmes en nombres entiers, la plus largement utilisée est la méthode « Branch and Bound » (qui existe en tant que SOLVER). cf section suivante. La solution optimale du problème mixte (PLMN) associé à (2.20) est z1 = 1 ; z2 = 0, 89 ; z3 = 0 et z4 = 1 pour une valeur actuelle nette de 21, 79 Millions de FCFA. La solution optimale du (PLN) est z1 = 0 ; z2 = 1, 89 ; z3 = 1 et z4 = 1 pour une valeur actuelle nette de 21 Millions de FCFA.
Les méthodes Branch and Bound et Branch and Cut
L’algorithme par Séparation et Evaluation, ou Branch and Bound, est une méthode générique de résolution de problèmes d’optimisation combinatoire. Cette méthode de Branch and Bound est plutôt destiné aux problèmes de recherche opérationnelle mais elle est aussi très utilisée pour la résolution de problèmes NP-complets, c’est-à-dire des problèmes considérés comme difficiles à résoudre efficacement. Elle a été proposé en 1960 par Land et Dong et est basée en effet sur une division du problème en un certain nombre de petits problèmes (Branch) et ensuite une évaluation de leur qualité basée sur la résolution des programmes linéaires sous-jacents (Bound). La méthode Branch and Bound a été aussi la plus efficace technique pour résoudre les problèmes de (PLMN) dans les quarante années ou plus qui ont suivi. Historiquement, la première méthode mise au point pour la résolution de (PLMN) était basée sur la méthode « cutting planes » ou simplement méthode de coupure, une approche introduite par Gomory en 1958. Cependant, dans les trente dernières années, la méthode de coupure ont resurgi et sont efficacement combinées avec la méthode branch and bound dans une procédure globale appelée Branch and Cut. Ce terme a été inventé par Padberg et Rinaldi en 1987. Les solvers commerciaux les plus sophistiqués tels que CPLEX et XPRESS utilisent cette combinaison de Branch and Cut. Le livre introductif de Wolsey [68] présente encore plus d’aspects intéressants concernant la programmation linéaire en nombre entier et ces méthodes de résolution. Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Programmation dynamique
Programmation dynamique
La programmation dynamique est une méthode exacte d’optimisation combinatoire adaptée à l’optimisation des systèmes dynamiques. Ces derniers évoluent dans le temps d’un état initial ei à un état final ef en transitant par des états intermédiaires. La transition d’un état à l’autre définit une étape. Cette méthode fait intervenir des décisions par étape. La programmation dynamique consiste alors à décomposer le problème initial en une série de sous-problèmes de taille inférieure. Ces derniers seront à leur tour décomposés jusqu’à atteindre des sous-problèmes de taille élémentaire dont la résolution est triviale. Cette manière d’obtenir la solution du problème initial à partir de celle des sous problèmes est basée sur le principe d’optimalité de Bellman. Ce principe permet de résoudre ces sous-problèmes de manière récurcise en les liant par des relations de récurrence de type forward(réccurence avant) ou backward (réccurence arrière). Les équations qui en découlent sont appelées équations de Bellman. La programmation dynamique s’applique à des problèmes dynamiques déterministes ou stochastiques où respectivement on envisage que le temps discret ou continu. 2.6.1 Définition de quelques éléments de base A l’évolution du système dynamique, on associe les variables suivantes : – la variable de temps notée t prenant des valeurs discretes dans N ou continues sur un intervalle [0; T] appartenant à R où T est le nombre de phases ou de périodes appelé horizon du système ; – la variable d’état x(t) ou xt qui représente un point de la trajectoire du système à l’instant t; – la variable de décision ou de contrôle ou de commande à l’instant t notée u(t) ou ut . Définition 2.9. L’évolution du système est décrite par une équation, appelée équation d’état ou d’évolution ou de comportement du système. Cette évolution se caractérise par un changement, au cours du temps, de l’état observé ; elle désigne aussi la trajectoire ou la dynamique du système. On désigne par : St(xt) l’ensemble des états du système à l’instant t; Ut(xt) l’ensemble des décisions admissibles à l’état xt ; ft les fonctions de transition ou de transfert à l’instant t d’un état xt à un état xt+1. Définition 2.10. Le triplet (St , Ut , ft) est appelé processus de décision séquentiel. C’est un modèle mathématique par lequel on schématise les problèmes d’optimisation qui évoluent en fonction du temps. Définition 2.11. Une politique (u0, u1, u2, . . . , uT −1) est une séquence de décisions prise aux différentes phases du processus. Elle est dite optimale si pour chaque état du systéme une décision est prise dans le but d’optimiser un critère donné. Définition 2.12. On appelle sous-politique toute politique d’un sous-problème.
Énoncé du principe
Ce principe a été énoncé par Richard Bellman de la manière suivante : Une politique optimale a la propriété que, quels que soient l’état initial et la décision initiale, les décisions restantes doivent constituer une politique optimale vis-à-vis de l’état résultant de la première décision » [7] c’est à dire « Toute politique optimale ne peut être formée que de sous politiques optimales ». En d’autres termes, si une suite de décisions π = {µ0, µ1, . . . , µN−1} est politique optimale alors il en est de même de la suite de décisions πp = {µp, µp+1, . . . , µN−1} pour l’état initial xp et le critère f(xp, up) + f(xp+1, up+1) + · · · + f(xN−1, uN−1). Démonstration. On va le faire par deux méthodes différentes. • Première méthode Supposons que la suite de décisions πp = {µp, µp+1, . . . , µN−1} n’est pas optimale. On peut alors remplacer cette suite πp par une autre suite π 0 p = {µ 0 p , µ0 p+1, . . . , µ0 N−1} qui serait elle-même optimale. Comme la fonction objectif est additive, la suite πp = {µ0, µ1, . . . , µ0 p , µ0 p+1, . . . , µ0 N−1} conduira à un objectif meilleur que celui atteint grâce à la suite π. Ce qui est en contradiction avec l’hypothèse. D’où la suite πp est optimale. • Deuxième méthode Posons Jp = min up,…,uN−1 {f(xp, up) + f(xp+1, up+1) + · · · + f(xN−1, uN−1)}. Jp ne dépend que de xp et p, on écrit donc Jp(xp). On a : Jp(xp) = min up {f(xp, up) + min up+1,…,uN−1 {f(xp+1, up+1) + · · · + f(xN−1, uN−1)}} (2.21) C’est à dire Jp(xp) = min up {f(xp, up) + Jp+1(xp+1)} (2.22) Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Programmation dynamique 36 et comme xp+1 = f(xp, up, p), Jp(xp) = min up {f(xp, up) + Jp+1(f(xp, up, p)} (2.23) Pour p = N − 1, on a : JN−1(xN−1) = min uN−1 {f(xN−1, uN−1 + JN (xN )}. Par convention JN (xN ) = 0 Alors J0(x0) est l’optimum cherché. Les équations (2.21), (2.22), (2.23) sont appelées équations de Bellman ou équations de la programmation dynamique. Elles sont des relations de récurrence qui permettent de calculer de proche en proche Jp(xp) pour aboutir à J0(x0) qui l’optimum cherché. Il existe des relations de récurrence de type forward ou pétrgrade et de type backward ou rétrograde.
Avantages et limites du principe
Les avantages ?
Très simple pour rèsoudre les sous problèmes d’un problème donné. ? Fournit directement la solution optimale pour les problèmes de nature sèquentielle. ? Permet de traiter des problèmes dèterministes, stochastiques. ? S’adapte à des situations où le temps, les états et les décisions varient continûment. ? Intervient dans les systèmes dynamiques et autres systèmes de décisions sèquentielles. ? Fournit de nombreuses applications en recherche opérationnelle : investissements, stocks, transports, renouvellement du matériel, réapprovisionnement. 2.6.3.2 Les limites ? Très complexe pour la résolution des problèmes de grande taille (où le nombre d’états croit de manière exponentielle en fonction du nombre d’étapes). ? Recours à d’autres méthodes de résolution : – utilisation de la méthode de Branch and Bound pour réduire la dimension de l’espace ; – application des méthodes heuristiques pouvant approcher la solution dans des temps de résolution très raisonnables. Méthodes de sélection dynamique pour l’optimisation de portefeuille c Seydina Issa DIONE 2016 Optimisation avec l’incertitude des données 37 Remarque 2.6. Les modèles de programmation dynamiques sont omniprésents dans la littérature financière. Les exemples les plus connus et les plus courantes sont les modèles d’arbres ou de treillis (binomiale, trinôme, etc.) utilisé pour décrire l’évolution des prix d’actions, les taux d’intérêt, les volatilités, etc., et les prix et plans de couverture.
Dédicaces |