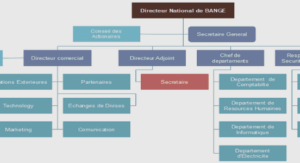
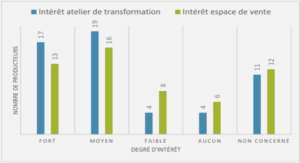
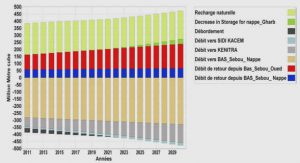
Cours les arbres de décision classiques et flous, tutoriel & guide de travaux pratiques en pdf.
Arbre de décision classique
Un arbre de décision est un outil d’aide à la décision et à l’exploration de données. Il permet de modéliser simplement, graphiquement et rapidement un phénomène mesuré plus ou moins complexe. Sa lisibilité, sa rapidité d’exécution et le peu d’hypothèses nécessaires à priori expliquent sa vaste utilisation dans différents applications et reconnaissance de forme. Il est composé de :
Une racine, qui est point de départ.
des nœuds, ou sont réalisés des tests
des feuilles, qui contiennent l‟information cherchée.
Le parcours d‟un arbre se fait, par tests successifs, de la racine à une feuille et constitue une règle de décision.
Construction d’un arbre de décision
Bases de règles
Un arbre est un système de règles de type particulier : Il y a autant de règles que de feuilles et autant de tests que de nœuds avec des différences :
Les règles sont mutuellement exclusives.
Une règle et une seule est entièrement évaluée.
Les tests sur les attributs sont réalisés dans un ordre donné.
Prétraitements
Nous attachons un test à chaque nœud et une réponse à chaque feuille ce qui définit la spécification des arbres de décision. Avec des avantages comme :
Suite de tests mono variés.
Pas de problème de combinaison de variables, de différentes natures.
Hiérarchisation de variables intégrée.
Rapidité d‟exécution.
Génération de règles logiques simples de classification.
Algorithme de l’arbre de décision
Lire le vecteur d‟observation,‟V‟
Se mettre à la racine
Tant que (non feuille) faire
N= testNoeud(V)
Se positionner sur le fils N fait
Ecrire la réponse
Phase d’apprentissage
Entropie :
Le concept d‟entropie est utilisé pour ordonner la liste des descripteurs avec le respect des ensembles de données, et des classes. L‟entropie fournie une définition des descripteurs les plus significatifs [10].
Le calcul de l‟entropie est donné par la formule mathématique suivante :
Où P(ci ) est la probabilité que la classe ci soit correcte. La quantité log2 quantité d‟information que l‟on donne quand la classe est la valeur attendue de ce l‟information. Cette valeur attendue est la mesure d‟entropie de l‟ensemble.
On note X cardinal de l‟ensemble X. Si un ensemble T d‟enregistrements
partitionnés par la valeur de l‟attribut catégorique en classes disjointes {C1, C2,…,Ck}, alors l‟information nécessaire pour reconnaître la classe d‟un élément de T est associée à l‟entropie I(p) ,où P est la distribution de la probabilité de la partition (C1,C2, …,Ck) :
Si l‟on partitionne notre ensemble T en valeurs disjointes, alors l‟information nécessaire pour identifier la classe d‟un élément de T devient :
Info( X ,T ) im0 Ti Info(Ti ) (2-3)
Où Ti est un sous ensemble de A pour la valeur i.
De là nous pouvons définir ce qu‟est le gain, qui représente le gain obtenu dû au partitionnement par l‟attribut X :
Gain(X, T)= Info(X)-Info (X,T) (2-4)
Test d’arrêt :
Les tests d‟arrêt permettent de contrôler la croissance de l‟arbre, En arrêtant éventuellement la création de nouveaux nœuds, même si tous les attributs n‟ont pas été évalués.
Deux cas ne posent pas de problème :
Toutes les observations associées à un nœud sont de la même classe,
Tous les attributs ont été évalués.
Alors le nœud considéré est un nœud terminal.
Dans les autres cas, on définit des critères paramétrables :
Une classe contient une proportion d‟observations de la même classe supérieure à un seuil donné,
Les sous-ensembles d‟observations sortant d‟un nœud sont trop petits, ce qui évite d‟explorer des branches comportant trop peu d‟éléments.
Elagage d’un arbre de décision
L‟objectif est de construire un arbre de taille réduite ayant à peu prés les mêmes performances que l‟arbre initial.
– L‟arbre initial est construit avec un ensemble d‟apprentissage et se fait sur un ensemble de test.
– L‟élagage consiste à remplacer un sous-arbre par une feuille, tant que les capacités de généralisation ne se dégradent pas [9].
Le pré-élagage
La première stratégie utilisable pour éviter un sur ajustement massif des arbres de décision consiste à proposer des critères d‟arrêt lors de la phase d‟expansion. C‟est le principe du pré-élagage.
Nous considérons par exemple qu‟une segmentation n‟est plus nécessaire lorsque le groupe est d‟effectif trop faible ; ou encore, lorsque la pureté d‟un sommet a atteint un niveau suffisant, nous considérons qu‟il n‟est plus nécessaire de le segmenter ; autre critère souvent rencontré dans ce cadre, l‟utilisation d‟un test statistique pour évaluer si la segmentation introduit un apport d‟information significatif quant à la prédiction des valeurs de la variable à prédire [9].
Le post-élagage
La seconde stratégie consiste à construire l‟arbre en deux temps : produire l‟arbre le plus pur possible dans une phase d‟expansion en utilisant une première fraction de l‟échantillon de données (échantillon d‟apprentissage) une marche arrière pour réduire l‟arbre, c‟est la phase de post-élagage, en s‟appuyant sur une autre fraction des données de manière à optimiser les performances de l‟arbre.
Selon les logiciels, cette seconde portion des données est désignée par le terme d‟échantillon de validation ou échantillon de test.
Algorithme de création de l’arbre
Algorithme ID3 (Induction of Decision Tree)
Présentation :
J.Ross Quilan de l‟université de Syndney, est le créateur de l‟algorithme ID3 Ce fut en 1975. Construire un arbre de décision d‟un ensemble fixe d‟exemples. L‟arbre résultant est employé pour classifier de futurs exemples. L‟exemple a plusieurs attributs et appartient à une classe (comme oui ou non). Les nœuds de feuille de l‟arbre de décision contiennent le nom de classe contrairement aux nœuds de décision. Le nœud de décision est un essai d‟attribut avec chaque branchement (à un autre arbre de décision) étant une valeur possible de l‟attribut. Gain de l‟information des utilisations ID3 pour l‟aider à décider quel attribut entre dans un nœud de décision.
Contraintes de l’ID3:
Les exemples utilisés par ID3 doivent respecter certaines contraintes, tel que :
Etre fixes.
Les mêmes attributs doivent décrire chaque variable, et avoir un nombre fixe de valeurs.
Un exemple d‟attributs doit être déjà définit.
Des classes bien délimitées.
ID3 met en jeux deux concepts majeurs :
L‟entropie : concept permettant de trouver les paramètres les plus significatifs.
Les arbres de décision : efficaces et intuitifs permettent d‟organiser les descripteurs qui peuvent être utilisés comme fonction prédictive.
Autres algorithmes
Algorithme C4.5
L‟algorithme C4.5 a été élaboré par Quinlan en 1993, cet algorithme n‟est en fait qu‟une amélioration de ID3.
Cette méthode utilise un critère plus élaboré : « le gain ratio » dont le but est de limiter la prolifération de l‟arbre en pénalisant les variables qui ont beaucoup de modalités. Contrairement à ID3, C4.5 est parfaitement réalisable dans des applications industrielles.
Algorithme CART (Classification and Regression Tree)
Cette méthode permet d’inférer des arbres de décision binaires, i.e. tous les tests étiquetant les nœuds de décision sont binaires. Le langage de représentation est constitué d’un certain nombre d’attributs. Ces attributs peuvent être binaires, qualitatifs (à valeurs dans un ensemble fini de modalités) ou continus (à valeurs réelles). Le nombre de tests à explorer va dépendre de la nature des attributs. A un attribut binaire correspond un test binaire. A un attribut qualitatif ayant n modalités, on peut associer autant de tests qu’il y a de partitions en deux classes, soit 2n-1 tests binaires possibles. Enfin, dans le cas d’attributs continus, il y a une infinité de tests envisageables. Dans ce cas, on découpe l’ensemble des valeurs possibles en segments, ce découpage peut être fait par un expert ou fait de façon automatique.
Arbre de décision flou
Concepts de la logique floue
Dans la logique classique, les variables gérées sont Booléennes. C’est à dire qu’elles ne prennent que deux valeurs 0 ou 1.
La logique floue a pour but de raisonner à partir de connaissances imparfaites qui opposent une résistance à la logique classique. Pour cela la logique floue se propose de remplacer les variables booléennes par des variables flous.
Historique
Depuis longtemps l’homme cherche à maîtriser les incertitudes et les imperfections inhérentes à sa nature. La première réelle manifestation de la volonté de formaliser la prise en compte des connaissances incertaines fut le développement de la théorie des probabilités à partir du XVII siècle. Mais les probabilités ne peuvent maîtriser les incertitudes psychologiques et linguistiques. On a donc assisté aux développements des théories de probabilité subjective (dans les années 50) puis de l’évidence (dans les années 60).
Puis la Logique Floue est apparue en 1965 à Berkeley dans le laboratoire de Lotfi Zadeh avec la théorie des sous-ensembles flous puis en 1978 avec la théorie des possibilités. Ces deux théories constituent aujourd’hui ce que l’on appelle Logique Floue.
La Logique Floue permet la formalisation des imprécisions dues à une connaissance globale d’un système très complexe et l’expression du comportement d’un système par des mots.
Elle permet donc la standardisation de la description d’un système et du traitement de données aussi bien numériques qu’exprimées symboliquement par des qualifications linguistiques.