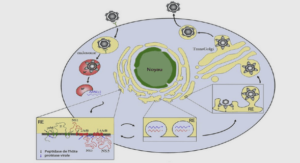
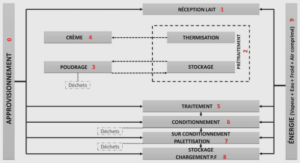
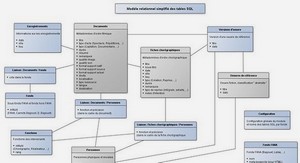
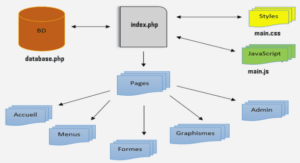
Extrait du cours base de données relationnelles
……..
2.5 La gestion des doublons dans une requête SELECT
Il arrive fréquemment que la lecture d’une table sur un sous ensemble de ses colonnes engendre des doublons (plusieurs lignes identiques pour certains sous ensemble de colonnes).
Pour ne pas remonter plusieurs fois les mêmes lignes il existe l’option suivante
– DISTINCT : chaque ligne doit être différente de toutes les autres
– Instruction SQL :
SELECT DISTINCT [col1], … , [colN] FROM [nom table1]
Ainsi chaque ligne retournée par cette requête sera unique (tout les doublons de la table sur les colonnes sélectionnées ne sont présentés qu’une fois dans le résultat).
2.6 Les requêtes Imbriquées
Il est possible d’utiliser des requêtes imbriquées en SQL. Cela permet entre autre d’utiliser le contenu du résultat d’une première requête dans une autre requête.
a. Utilisation d’une sous requête comme une table de données :
Cette instruction permet d’utiliser une table « virtuelle » créée à partir d’une première requête et d’utiliser son contenu pour effectuer une autre requête.
– Instruction SQL :
SELECT [nom Alias de requête1].[col1], …, [nom Alias de requête1].[colN]
FROM
(SELECT [col1],[col2], …, [colN]
FROM [nom table1], …., [nom tableN]
WHERE [Conditions requête1]) AS [nom Alias de requête1]
WHERE [Conditions requête2]
…
La requête est alors exécutée en 2 temps :
– (SELECT [col1],[col2], …, [colN]
FROM [nom table1], …., [nom tableN]
WHERE [Conditions requête1]) AS [nom Alias de requête1]
Exécution de la première requête et génération du résultat.
– SELECT [nom Alias de requête1].[col1], …, [nom Alias de requête1].[colN]
FROM
[Résultat Requête1]
WHERE [Conditions requête2]
Exécution de la seconde requête sur le résultat de la première requête.
b. Utilisation d’une sous requête dans une conditions de filtre :
Cette type de requête permet d’effectuer une sélection de lignes dans une table dont le résultat sera utilisé comme condition d’une autre requête.
– Instruction SQL :
SELECT * FROM [nomtable2]
WHERE [nomtable2].[colX] IN (SELECT [nomtable1].[colY] FROM [nomtable1]
WHERE …. GROUP BY…)
Ainsi nous obtenons toutes les lignes de la table [nomtable2] dont la valeur de la colonne X est dans liste créée par les valeurs de la colonne Y de la table [nomtable1].
c. Concaténer le résultat de deux requêtes en une seule :
Cet instruction permet de retourner dans un seul résultat le résultat de plusieurs requêtes SQL.
– Instruction SQL :
(SELECT * FROM [nomtable1])
UNION
(SELECT * FROM [nomtable2])
UNION
(SELECT …..)
Tout les résultats de chaque requête sont alors introduit les uns à la suite des autres dans un seul résultat. Pour pouvoir exécuter ce type d’instruction, chaque requête doit contenir le même nombre de colonnes (de même type).
d. Utilisation de sous requête dans les requêtes LDD
– Création d’une table à partir d’une requête SQL :
CREATE TABLE [nom nouvelle table]
SELECT [col1], …[colN]
FROM [nomtable1]
WHERE [conditions]
GROUP BY [agrégats]
HAVING [conditions sur agrégats]
ORDER BY [tri]
Une nouvelle table est alors physiquement créée à partir des résultats de la requête SELECT.
Cette nouvelle table reproduit la structure des données de la requête SELECT. Elle ne comportera par contre aucun index ni clé primaire.
……..
Initiation aux base de données relationnelles langage sql (520 KO) (Cours PDF)