Apprentissage profond et réseaux neuronaux
Le problème de l’approche classique de la reconnaissance des formes est qu’un bon extracteur de caractéristiques est très difficile à construire, et qu’il doit être repensé pour chaque nouvelle application. C’est là qu’intervient l’apprentissage profond ou DEEP LEARNING en anglais. C’est une classe de méthodes dont les principes sont connus depuis la fin des années 80, mais dont l’utilisation ne s’est vraiment généralisée que depuis 2012, environ.
L’idée est très simple : le système entraînable est constitué d’une série de modules, chacun représentant une étape de traitement. Chaque module est entraînable, comportant des paramètres ajustables similaires aux poids des classifieurs linéaires. Le système est entraîné de bout en bout : à chaque exemple, tous les paramètres de tous les modules sont ajustés de manière à rapprocher la sortie produite par le système de la sortie désirée. Le qualificatif profond vient de l’arrangement de ces modules en couches successives.
Pour pouvoir entraîner le système de cette manière, il faut savoir dans quelle direction et de combien ajuster chaque paramètre de chaque module. Pour cela il faut calculer un gradient, c’est-à-dire pour chaque paramètre ajustable, la quantité par laquelle l’erreur en sortie augmentera ou diminuera lorsqu’on modifiera le paramètre d’une quantité donnée. Le calcul de ce gradient se fait par la méthode de rétro-propagation, pratiquée depuis le milieu des années 80. Dans sa réalisation la plus commune, une architecture profonde peut être vue comme un réseau multicouche d’éléments simples, similaires aux classifieurs linéaires, interconnectés par des poids entraînables. C’est ce qu’on appelle un réseau neuronal multicouche.
Pourquoi neuronal ? Un modèle extrêmement simplifié des neurones du cerveau les voit comme calculant une somme pondérée et activant leur sortie lorsque celle-ci dépasse un seuil. L’apprentissage modifie les efficacités des synapses, les poids des connexions entre neurones. Un réseau neuronal n’est pas un modèle précis des circuits du cerveau, mais est plutôt vu comme un modèle conceptuel ou fonctionnel. Ce qui fait l’avantage des architectures profondes, c’est leur capacité d’apprendre à représenter le monde de manière hiérarchique. Comme toutes les couches sont entraînables, nul besoin de construire un extracteur de caractéristiques à la main, l’entraînement s’en chargera. De plus, les premières couches extrairont des caractéristiques simples (présence de contours) que les couches suivantes combineront pour former des concepts de plus en plus complexes et abstraits : assemblages de contours en motifs, de motifs en parties d’objets, de parties d’objets en objets etc.
Réseaux convolutifs, réseaux récurrents
Une architecture profonde particulièrement répandue est le réseau convolutif. Les premières versions ont été développée en 1988-1989 d’abord à l’Université de Toronto, puis aux Bell Laboratoires, qui était à l’époque le prestigieux labo de recherche de la compagnie de télécommunication AT&T. Les réseaux convolutifs sont une forme particulière de réseau neuronal multicouche dont l’architecture des connexions est inspirée de celle du cortex visuel des mammifères. Par exemple, chaque élément n’est connecté qu’à un petit nombre d’éléments voisins dans la couche précédente.
Un système automatique de lecture de chèques a été déployé largement dans le monde dès 1996, y compris en France dans les distributeurs de billets du Crédit Mutuel de Bretagne. À la fin des années 90, ce système lisait entre 10 et 20% de tous les chèques émis aux États-Unis. Mais ces méthodes étaient plutôt difficiles à mettre en œuvre avec les ordinateurs de l’époque, et malgré ce succès, les réseaux convolutifs et les réseaux neuronaux plus généralement ont été délaissés par la communauté de la recherche entre 1997 et 2012.
En 2003, Geoffrey Hinton de l’Université de Toronto, Yoshua Bengio de l’Université de Montréal et de l’Université de New York, ont décidé de démarrer un programme de recherche pour remettre au goût du jour les réseaux neuronaux, et pour améliorer leurs performances afin de raviver l’intérêt de la communauté. Ce programme a été financé en partie par la fondation CIFAR (l’Institut Canadien de Recherches Avancées).
Entre 2011 et 2012, trois événements ont soudainement changé la donne. Tout d’abord, les GPUs (Graphical Processing Units) capables de plus de mille milliards d’opérations par seconde sont devenus disponibles pour moins de 1000 euros la carte. Ces puissants processeurs spécialisés, initialement conçus pour le rendu graphique des jeux vidéo, se sont avérés être très performants pour les calculs des réseaux neuronaux. Deuxièmement, des expériences menées simultanément à Microsoft, Google et IBM avec l’aide du laboratoire de Geoff Hinton ont montré que les réseaux profonds pouvaient diminuer de moitié les taux d’erreurs des systèmes de reconnaissance vocale. Troisièmement plusieurs records en reconnaissance d’image ont été battus par des réseaux convolutifs.
L’événement le plus marquant a été la victoire éclatante de l’équipe de Toronto dans la compétition de reconnaissance d’objets appelée ImageNet. La diminution des taux d’erreurs était telle qu’une véritable révolution d’une rapidité inouïe s’est déroulée. Du jour au lendemain, la majorité des équipes de recherche en parole et en vision ont abandonné leurs méthodes préférées et sont passées aux réseaux convolutifs et autres réseaux neuronaux. L’industrie d’Internet a immédiatement saisi l’opportunité et a commencé à investir massivement dans des équipes de recherche et développements en apprentissage profond. L’apprentissage profond ouvre une porte vers des progrès significatifs en intelligence artificielle.
C’est la cause première du récent renouveau d’intérêt pour l’IA. Une autre classe d’architecture, les réseaux récurrents sont aussi revenus au goût du jour. Ces architectures sont particulièrement adaptées au traitement de signaux séquentiels, tels que le texte. Les progrès sont rapides, mais il y a encore du chemin à parcourir pour produire des systèmes de compréhension de texte et de traduction.
L’intelligence artificielle aujourd’hui. Ses enjeux
Les opportunités sont telles que l’IA, particulièrement l’apprentissage profond, est vue comme des technologies d’importance stratégique pour l’avenir. Les progrès en vision par ordinateur ouvrent la voie aux voitures sans chauffeur, et à des systèmes automatisés d’analyse d’imagerie médicale. D’ores et déjà, certaines voitures haut de gamme utilisent le système de vision basé sur un réseau convolutif pour l’assistance à la conduite. Des systèmes d’analyse d’images médicales détectent des mélanomes et autres tumeurs de manière plus fiable que des radiologues expérimentés.
Chez Facebook, Google et Microsoft, des systèmes de reconnaissance d’image permettent la recherche et l’organisation des photos et le filtrage d’images violentes etc. Depuis plusieurs années déjà, tous les moteurs de reconnaissance vocale sur smartphone utilisent l’apprentissage profond. Des efforts considérables de R&D sont consacrés au traitement du langage naturel : la compréhension de texte, les systèmes de question-réponse, les systèmes de dialogue pour les agents virtuels, et la traduction automatique. Dans ce domaine, la révolution de l’apprentissage profond a été annoncée, mais n’est pas encore achevée. Néanmoins, on assiste à des progrès rapides. (LeCun)
Dans le cadre de cette recherche nous tenterons d’utiliser les techniques d’apprentissage profond pour apporter une solution à la problématique d’évaluation des locaux à usage d’habitation par les méthodes dit indiciaire.
Méthodes d’évaluation cadastre
Les méthodes d’évaluation classiques sont de plus en plus abandonnées au profit des méthodes indiciaires, ce choix est en partie lié à un besoin permanent de dématérialisation de cette procédure cadastrale.
La méthode indiciaire se rapproche :
• De la méthode CAMA (Computer Assisted Mass Appraisal) utilisée par exemple à Cape Town en Afrique du Sud, et aussi dans certaines villes américaines
• De la méthode par points REMOP développée au Malawi par l’Initiative pour la Taxe Foncière en Afrique
• Des méthodes par points améliorées en train d’être testées à Kampala (Ouganda) et à Freetown (Sierra Leone)
Méthode CAMA
Connu en français sous le nom d’évaluation de masse assistée par ordinateur, CAMA est le processus d’évaluation qui permet de recenser un grand nombre de propriétés en même temps à l’aide de procédures standardisées. C’est une méthode efficace pour avoir évaluation exhaustive et est antérieure à la pratique de la «production de masse» de plusieurs siècles.
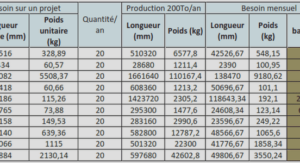
Pour comprendre le fonctionnement de la méthode CAMA nous allons prendre l’exemple d’un évaluateur qui a la responsabilité d’évaluer 100 000 propriétés pour l’impôt foncier sur une période de deux ans, il est évident qu’il ne peut le faire que par organisation et délégation. En effet il lui sera quasi impossible d’évaluer plus de 1000 propriétés au cours de cette période. Ainsi le travail doit être effectué en association avec des évaluateurs et des techniciens en évaluation conformément aux lignes directrices qui seront établies.
La difficulté réside dans le fait que l’évaluation se fera en tenant compte de la situation des propriétés et leur catégorie, par exemple, les terres agricoles de la catégorie x dans un emplacement spécifié sont évaluées à y FCFA par hectare. Cependant les maisons individuelles d’une autre catégorie dans la banlieue sont évaluées à z FCFA par mètre carré. Dès lors, on se rend compte qu’il est assez complexe de définir les règles d’évaluation compte tenu du fait que toute la complexité et les données doivent être intégrées (FAO, 2002).
Ainsi l’évaluation de la valeur des propriétés sera être difficile à réaliser sans le système informatique et les logiciels appropriés pour organiser les données importantes. CAMA intervient en ce sens, comme progiciel utilisé par les agences gouvernementales pour aider à établir des évaluations immobilières pour les calculs de l’impôt foncier.
CAMA est un projet composé de plusieurs applications mutuelles qui soutiennent systématiquement et techniquement l’exécution de l’évaluation et de la fiscalité des biens immobiliers. Les applications assurent une évaluation automatisée efficace des entités immobilières et de leurs parties complémentaires. Ils ont un impact immense sur le gain de temps et d’argent en remplaçant les procédures d’évaluation traditionnelles coûteuses et lentes par un système stable et pratique qui fournit des informations instantanées sur l’immobilier.
Le projet CAMA est composé des applications suivantes:
Applications Java : pour l’évaluation de masse et simultanée de biens immobiliers à partir du registre immobilier
Modèles d’évaluation immobilière : Application qui affiche des données sur les modèles, les caractéristiques géométriques des zones d’évaluation et un aperçu de la procédure d’évaluation pour chaque modèle.
Évaluation immobilière : Le but de cette application est le calcul informatif pour chaque bien immobilier stocké dans le registre immobilier. Le propriétaire d’un bien immobilier peut modifier différents paramètres de son bien immobilier pour voir la valeur modifiée.
Calculateur de biens immobiliers – L’utilisateur peut combiner ses biens immobiliers fictifs de différents types de bâtiments et parcelles. Pour chaque modèle, il peut ensuite attribuer l’année de construction, la taille, la destination du terrain, etc. En faisant cela, il a une connaissance plus détaillée du prix de l’immobilier sur une certaine zone.
Interface d’administration : Avec l’interface d’administration, les administrateurs peuvent modifier, ajouter ou supprimer les données du modèle, qui sont utilisées pour l’évaluation immobilière. Cela permet une mise à jour rapide et efficace des données immobilières. (sinergise, s.d.)
Méthode REMOP
La méthode REMOP a été mise en place pour augmenter les recettes en taxe foncière. Elle est née dans le but d’apporter une solution à la problématique de recensement des locaux. REMOP a été testé dans la capitale de la région nord de Malawi sous forme de projet pilote. Elle comporte plusieurs phases : état des lieux, évaluation, taxation, sensibilisation, recouvrement et mise en conformité.
L’état des lieux a permis l’enregistrement de nouvelles propriétés quadruplant le nombre de propriétés au cadastre en le faisant passer de 10 000 à 40 000. Le nouveau système d’adressage physique était aussi plus robuste et améliorait la délivrance des facturations et des mises en demeure.
La phase d’évaluation comportait la mise en place d’une localisation avec l’ajout de points en cas d’éléments positifs tels que l’accès à une voie pavée et le retrait de points en cas d’éléments négatifs tels que l’absence d’électricité. Ce système est moins régressif qu’un système exclusivement basé sur la localisation. De plus, il est beaucoup plus simple à gérer que le système basé sur le marché immobilier précédemment utilisé à Mzuzu. La municipalité a pu ainsi évaluer beaucoup de propriétés, notamment celles des zones d’habitats informels où les données immobilières ne sont pas disponibles. L’estimation est aussi devenue plus efficace grâce à l’introduction d’évaluations de masse assistées par ordinateur, considérées par les agents municipaux comme étant à la fois économiquement viable et simple d’utilisation.
La taxation est devenue plus rentable avec l’introduction de nouveaux programmes informatiques permettant une mise à jour automatique des impayés et l’impression de plusieurs factures grâce à une simple touche. De plus, les nouveaux avis d’imposition présentaient tous les détails influençant la valeur de la propriété, rendant ainsi l’évaluation transparente. En outre, la procédure a été simplifiée par la taxation devenue annuelle et non plus trimestrielle.
La phase de sensibilisation avait pour but d’informer les résidents sur le nouveau système notamment les bases de l’imposition, leurs droits et devoirs et aussi les liens entre l’impôt et les améliorations qu’ils pourront constater au niveau des services publics. Chacune de ces démarches avait pour but de persuader les citoyens de l’intérêt de payer car la majorité croyant jusqu’alors que l’essentiel des infrastructures et services locaux provenaient de fonds versés par le gouvernement central à la municipalité.
Enfin, la procédure de recouvrement fiscal a été restructurée afin de mettre fin à la collecte en porte
à porte et mettre en place les paiements bancaires, réduisant ainsi les cas de vols et augmentant la confiance des contribuables dans le système. Parallèlement, Mzuzu a encouragé une banque à ouvrir une agence au sein du centre civique, simplifiant ainsi les paiements à la municipalité et permettant aux transactions d’être directement enregistrées auprès de l’administration municipale.
Pour ce qui est de la mise en conformité, l’établissement de mises en demeure a été faite via des courriers rédigés par un avocat et délivrés par la municipalité. Cette méthode a eu des résultats positifs, les contrevenants préférant payer que de subir l’embarras d’une audience au tribunal. (McCluskey, 2019)
Méthode par point
La méthode par point permet de faire une évaluation sur la base de paramètre pondéré. Il attribue un nombre standard de point en fonction de la surface bâtie et d’autres points supplémentaires en plus ou en moins sont attribués suivant des caractéristiques. Ainsi différents paramètres comme l’emplacement, le type de construction, accès aux services de qualité etc. sont évalués. La méthode par point est simple à mettre en œuvre et garanti un niveau de transparence, du respect de l’intimité du contribuable et permet d’augmenter efficacement le potentiel d’assiette de recouvrement. (Kevin Grieco)