Protection et restauration
Les dispositifs de gestion des pannes de GMPLS ou de MPLS peuvent être classés en deux catégories : la protection (notée P 1 ) et la restauration (notée R 2 ). Avec la protection, un en-semble de liens et de nœuds de redondance sont présélectionnés et leurs ressources associées sont réservées. En conséquence, lors d’une panne sur le chemin principal, le trafic peut être immé-diatement orienté sur le chemin de protection. Le cas de la restauration est différent puisque le chemin de protection n’est établi qu’après l’occurrence de la panne. Les deux mécanismes sont différents en termes d’échelle de temps et d’utilisation de ressources. Les mécanismes de protections et de restaurations sont essentiels afin de délivrer une QoS adéquate aux utilisateurs finaux et pour assurer les besoins de disponibilités obligatoires pour les réseaux d’opérateurs. Le protocole GMPLS a défini l’ensemble de ces dispositifs de résilience dans la RFC4427 [MP06].
La protection (P) nécessite l’allocation de ressources redondantes, généralement une redon-dance de 100% afin de pouvoir réagir de manière extrêmement rapide. Par exemple, le protocole SDH est conçu pour réorienter un flux de trafic d’un chemin primaire à un chemin secondaire en moins de 50 millisecondes avec une configuration de protection 1+1. Cette approche consomme deux fois plus de ressources qu’une configuration non protégée.
L’alternative de la restauration (R) s’appuie sur une mise en œuvre dynamique des ressources secondaires ce qui implique un délai de restauration d’une connexion d’un ordre de grandeur plus élevé. La restauration peut aussi demander un calcul de route dynamique, coûteux en temps de calcul, si les chemins de redondance ne sont pas calculés à l’avance ou si les chemins pré-calculés ne sont plus disponibles.
La protection et la restauration sont traditionnellement subdivisées en deux techniques : soit appliquées au chemin de la connexion, soit appliquées à un sous-chemin ou à un lien. Dans la résilience appliquée au chemin, une panne est gérée au niveau de la source et de la destination du LSP, alors que la résilience appliquée aux sous-chemins est gérée par les routeurs intermédiaires qui détectent la panne. La Fig. 4.1 montre les différentes configurations de résilience de GMPLS où ces deux techniques sont utilisées aussi bien par la protection que la restauration.
Dans tous ces mécanismes de résilience réactifs, plusieurs étapes sont impliquées après la détection d’une panne : le calcul de route, la signalisation, et la cross-connection. La différence entre les niveaux de résilience disponibles vient de la réalisation d’une ou plusieurs de ces étapes lors la configuration du service, c’est-à-dire avant l’occurrence de la panne.
Protection
La protection possède plusieurs configurations avec la protection dédiée (1+1), la protection dédiée avec du trafic externe (1 :1), la protection partagée avec du trafic externe (1 :N ) et la protection multi-chemin partagée avec du trafic externe (M :N ).
Dans le cas de la protection 1+1, le trafic est envoyé simultanément sur deux chemins dis-joints, un chemin principal (working) et un chemin de protection, c’est ensuite la destination qui sélectionne le meilleur signal. Dans le cas d’une panne, le routeur de destination ne reçoit plus de données du LSP principal et utilise donc le LSP de protection pour réceptionner les donnés. Cela nécessite d’utiliser le double de la bande passante du LSP mais permet le rétablissement de la connexion en un temps minimal.
1. Protection (G)MPLS
2. Restauration (G)MPLS
La protection 1 :1 est aussi un mode très coûteux. Un LSP de protection associé au LSP principal est réservé mais le trafic n’est envoyé que sur chemin principal. Les ressources de protection ne peuvent pas être réservées pour un autre LSP de même importance mais elles sont disponibles pour du trafic de moindre priorité tel que le Best Effort. Lors d’une panne, le nœud source doit effectuer une étape légère de signalisation afin de basculer le trafic sur le chemin de protection pré-réservé.
La protection 1 :N diffère de la protection 1 :1 en ce qu’un chemin de protection pré-alloué est associé à plusieurs LSP principaux (N ). Il n’en résulte qu’un risque lors d’une panne si le chemin de protection est déjà utilisé par un autre LSP, ceci entraîne une indisponibilité importante. De plus, le basculement du trafic implique des actions supplémentaires par rapport au schéma 1 :1 qui allongent légèrement le délai de rétablissement du LSP.
Enfin le dernier schéma M :N est un cas ou N chemins principaux sont protégés par M chemins secondaires. C’est une configuration qui englobe les configurations 1 :1 et 1 :N et où les M chemins de redondance sont partagés entre N connexions. De manière similaires aux cas 1 :1 et 1 :N les ressources sont pré-allouées, mais elles sont utilisables par du trafic moins prioritaire. Lors d’une panne, une action de signalisation est nécessaire afin de régler chaque routeur de protection au basculement du trafic du LSP perturbé par la panne.
Restauration
La restauration est conçue pour réagir aux pannes et être efficace en terme d’utilisation de bande passante mais avec un calcul de routes et une réservation des ressources dynamique, ce qui est moins rapide que les techniques de protection. Il existe trois schémas de restauration qui sont le reroutage complet (full-rerouting), la restauration pré-calculée (pre-computed restoration) et la restauration pré-planifiée (pre-planned restoration).
Le mécanisme de restauration, aussi appelé reroutage, utilise le concept de Make-Before-Break [ABG+ 01]. Le MBB 1 permet à un ancien chemin de toujours être utilisé pendant la mise en place du nouveau chemin, et ce, sans devoir réserver les ressources en double. Une fois la configuration terminée, le nœud effectuant le reroutage bascule le trafic sur le nouveau chemin puis libère les ressources de l’ancien chemin. Cette fonctionnalité est disponible avec le protocole RSVP-TE grâce à l’option Shared Explicit [ABG+ 01] mais aussi avec le protocole CR-LDP.
Lors d’une restauration, le chemin secondaire est établi après trois étapes : le calcul de routes, la signalisation et la réservation des ressources. Le reroutage complet est le cas le plus dynamique où ces trois étapes sont déclenchées après la détection de la panne. La restauration pré-calculée est plus rapide puisque le calcul de routes a déjà été effectué ; il ne reste plus que la signalisation et la réservation de ressources à compléter au moment de la panne. Enfin, la restauration pré-planifiée signifie que la sélection de la route ainsi que la signalisation ont été effectuées à l’avance, il ne reste donc plus que la réservation de ressources.
En conséquence, les performances en terme d’indisponibilité de chaque mécanisme dépendent des étapes restantes à effectuer pour établir un chemin de secours après l’occurrence de la panne.
Problématique
Le protocole GMPLS possède deux catégories de dispositifs de résilience dont chacun pos-sède des atouts. La protection permet une interruption de service minimum au détriment de la consommation de ressources, alors que la restauration, grâce à sa nature dynamique, est très efficace dans l’utilisation des ressources mais en assurant une disponibilité moins élevée. En effet, la restauration n’est mise en place dynamiquement que lors d’une panne, ce qui en fait un mécanisme efficace en terme d’utilisation de ressources, mais cette mise en place dynamique met du temps pour établir le nouveau LSP engendrant une interruption de service importante. La protection est bien plus rapide pour rétablir le service puisqu’un LSP de protection est déjà réservé. Mais cette réservation nécessite l’utilisation de deux fois plus de ressources, alors même que les ressources de protection ne sont utilisées que dans de rares occasions. Le mécanisme de protection est très coûteux pour l’opérateur.
Le choix de la technique de résilience à utiliser pour un opérateur est difficile. Ce choix est basé sur le type de trafic à protéger, son importance, ses besoins en QoS mais aussi sur la fiabilité des équipements traversés par le flux. Ce paramètre est difficile à prendre en compte puisque un même chemin peu posséder des tronçons d’anciens équipements ayant une fiabilité faible ainsi que des parties composées d’équipements de dernière génération avec une meilleure fiabilité. L’opérateur doit donc considérer le pire cas, ce qui peut l’entraîner à opter pour un schéma de protection qui lui sera très coûteux. De plus, la nature statique de la gestion des pannes accentue le problème. En effet, le type de mécanisme de résilience à appliquer à un LSP est configuré lors de la mise en place du service et rarement remis en cause par la suite. Les statistiques de fiabilité des équipements utilisés pour le choix du type de protection sont des statistiques très long terme, qui représentent plus une tendance qu’une donnée précise et qui peuvent ne plus être valides dans le futur. La complexité du choix de la bonne méthode à utiliser, ainsi que la lourdeur de sa mise en place contraint les opérateurs à ne pas remettre en cause leur configuration de gestion des pannes initiales, même si celle-ci n’est peut-être plus adaptée à la situation.
Enfin, la probabilité de panne des équipements est une donnée qui peut être extrêmement volatile, la mise à jour d’un système d’exploitation de certains routeurs peut engendrer un nombre important de pannes pendant une courte période, le dysfonctionnement d’un système de refroidissement peut augmenter de manière significative la probabilité de panne de certains équipements pendant une période de temps fini. Des événements réseaux comme les LSA storms, la propagation d’un virus, ou une attaque de pirates informatiques ont aussi un impact sur la probabilité de panne d’un équipement.
La nature statique de l’utilisation de la résilience GMPLS oblige les opérateurs à utiliser des statistiques longs termes, laissant de coté l’aspect dynamique de l’évolution de la probabilité de panne au court du temps. La conséquence de cela se manifeste par une consommation de ressources très coûteuse de l’utilisation des techniques de protection, alors que cela n’est pas nécessaire la plupart du temps. Cependant, afin de fournir une disponibilité importante, la nature statique de la résilience contraint les opérateurs à surdimensionner la protection afin de minimiser leur risque d’interruption de service. L’autre choix peut-être d’utiliser la restauration qui est beaucoup moins coûteuse, mais qui fournit des performances de disponibilité moindre qui ne sont pas suffisantes pour assurer la QoS nécessaire au trafic dit premium.
Une protection trop coûteuse ou une restauration peu performante sont actuellement les deux seules alternatives qui s’offrent aux opérateurs.
Une protection moins coûteuse et une restauration plus ra-pide
Malgré l’existence d’un ensemble complet de dispositifs de résilience au sein du protocole GMPLS, l’utilisation à bon escient du mécanisme adapté est un problème en soi. Le choix de la stratégie à adopter est un problème pour de nombreux opérateurs auxquels la communauté scientifique a tenté de répondre [CLSS02]. Ce n’est pas un problème simple puisque chaque technique possède des avantages et des inconvénients. La protection permet une interruption minimum mais est très coûteuse alors que la restauration est peu onéreuse mais engendre une indisponibilité importante. Des propositions ont été faites afin d’améliorer l’efficacité des mécanismes de résilience, soit en améliorant le coût des dispositifs de protection, soit d’une manière plus commune, en diminuant le temps de rétablissement du service avec le mécanisme peu coûteux de la restauration.
La protection a pour principal inconvénient de nécessiter la réservation des ressources pour les LSP de protection, ce qui est très coûteux en CAPEX comme en OPEX. Pour réduire ce défaut, le concept de préemption permet à plusieurs LSP de réserver une même ressource, un ordre de priorité permettant d’arbitrer l’utilisation de la ressource lorsque plusieurs LSP veulent l’utiliser en même temps. Cette possibilité augmente le temps de rétablissement d’un service car il est désormais nécessaire de signaler le choix d’utilisation de la ressource partagée, mais cela reste plus performant que la restauration et permet de diminuer les coûts. Néanmoins, l’utilisation de cette option est complexe. Il est difficile pour un opérateur de maîtriser entiè-rement son comportement et d’en prévoir les conséquences. En réponse, de nombreux travaux [Gro04, LGS02, CTS03, GAVC05, SFT+ 06] ont proposé des approches pour partager efficace-ment les ressources de protection et ainsi de faire baisser le coût de cette technique. Mais la restauration reste toujours plus intéressante en terme de coût et possède une nature dynamique qui la rend plus robuste aux multiples pannes.
L’autre alternative est l’amélioration des performances de la restauration. Cette option a été de loin la plus étudiée. Comme vu aux Sec. 2.4 et 3.4, de nombreuses propositions ont été faites pour réduire les différente étapes de la convergence des protocoles IGP [FFEB05] afin de rendre viable l’utilisation de la restauration pour les réseaux à haute disponibilité [SRM02, PIKF04]. De plus, en ce qui concerne l’utilisation de la technologie de commutation de paquets, il existe de manière similaire à la restauration IP, des mécanismes permettant d’outrepasser le délai de convergence par des décisions locales mettant en place des chemins temporaires [TWFV06]. Le MPLS Fast ReRoute (MPLS FRR) [RI07, PSA05, VPD04] comme le IP FRR possède les techniques de Loop Free Alternate (LFA), de U turn alternate, de Not-via address et de tunneling. De nombreux travaux ont proposé des modalités d’amélioration de la mise en œuvre du MPLS FRR [RI07, WWM+ 10] mais cette solution ne permet pas d’assurer une disponibilité comparable à la protection et génère des topologies non optimales avec des chemins plus longs, des délais d’acheminement plus longs et de possibles boucles de routage.
En dépit des évolutions améliorant les deux catégories de mécanismes de résilience, et au regard de la nature statique des stratégies de gestion des pannes actuelles, le choix de confi-guration est toujours un compromis entre vitesse et consommation de ressources. En réponse, nous proposons une approche d’autoréparation complètement différente qui utilise l’estimation en temps réel du risque de pannes pour alterner dynamiquement entre la protection et la res-tauration afin de minimiser les coûts consacrés à la gestion des pannes tout en maintenant une disponibilité importante.
Description de la proposition
Le principal défaut des dispositifs de résilience de GMPLS est leur nature statique alors que la probabilité de panne évolue dans le temps. Avec des modules RAM capables de détecter en temps réel lorsque le risque de panne devient important, il devient possible d’envisager d’utiliser cette information pour modifier dynamiquement la gestion des pannes. Une telle intervention nécessite qu’elle soit effectuée en quelques secondes maximum ce que n’est pas capable de réa-liser un opérateur humain. C’est pourquoi le principe de réseau autonome est le candidat idéal pour implémenter une telle fonctionnalité au sein des équipements réseaux. L’utilisation d’une information de risques fourni par le RAM permet au réseau d’adapter de manière extrêmement rapide son mécanisme de gestion des pannes au risque de pannes en temps réel et ainsi d’obtenir une meilleure efficacité. Notre proposition a pour but de fournir une protection minimum lorsque le risque de panne est faible afin de limiter le coût de la gestion des pannes, et une protection maximum lorsqu’un risque de panne est détecté, afin de minimiser le délai de rétablissement du LSP. Le mécanisme ALR 1 repose sur l’utilisation de la restauration en temps normal, et de l’établissement de LSP de protection temporaire lorsqu’un élément du LSP est concerné par une prédiction de panne [VNC12, WTVL13, PKM+ 09, PKA+ 10, VCL+ 11]. On obtient donc pour un coût proche de la restauration, de meilleures performances en termes de disponibilité.
Aperçu général du principe de résilience dynamique
L’objectif du dispositif ALR est d’améliorer les performances de la résilience de GMPLS en introduisant la prédiction de pannes au sein des équipements de réseau. Le mécanisme joue sur l’augmentation temporaire du niveau de protection d’un LSP possédant un routeur risqué afin d’être prêt si une panne devait effectivement apparaître [VNC12, WTVL13, PKM+ 09, PKA+ 10, VCL+ 11]. Le reste du temps, quand le risque de panne est faible, le LSP peut rester moins protégé ce qui permet à l’opérateur d’avoir plus de ressources disponibles.
L’objectif de cette proposition n’est pas d’assurer une disponibilité semblable à la protection, mais d’exploiter au mieux les informations sur les pannes possibles dans le réseau afin d’améliorer la disponibilité fournit par la restauration. Ainsi, lors d’une prédiction de panne, la rapidité d’exécution des machines permet au couple RAM et au module FMF du R&S_DE de déclencher la modification du mécanisme de résilience des LSP concernés par la panne, afin, le cas échéant, d’être capable de rétablir le LSP dans un délai minimum. De plus, cette méthode permet les performances de disponibilité de la protection avec l’avantage de la restauration puisque l’on connaît à l’avance les éléments concernés par la future panne. Ainsi il est possible d’adapter le chemin du LSP de protection de façon optimale pour n’exclure que les éléments risqués.
Si par contre la prédiction devait s’avérer être fausse, le trafic ne serait pas impacté, mais les ressources réservées pendant le temps de la prédiction Δtp auraient été inutilement consommées, créant un coût supplémentaire. Néanmoins, cette surconsommation limitée au temps Δtp reste négligeable comme en atteste les résultats obtenus. (Cf les sections suivantes). Enfin, si une panne n’est pas précédée par une prédiction, c’est le dispositif de restauration qui est utilisé pour rétablir les services perturbés. Cela permet d’obtenir un meilleur ratio coût/disponibilité que les mécanismes de protection et de restauration du protocole GMPLS en exploitant les indicateurs de l’état de santé du réseau, ainsi que la rapidité d’exécution (supérieure à celle d’un être humain) que permet l’autoréparation.
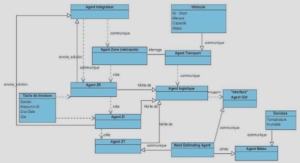
Afin de réaliser ce changement dynamique, le module FMF du R&S_DE (voir Fig. 4.2), suite à la réception d’une information de risques de panne en provenance du RAM, doit prendre le contrôle des éléments en charge du protocole GMPLS (i.e. OSPT-TE et RSVP-TE) sur le Ingress router de chaque LSP concerné par la panne afin de modifier le mécanisme de résilience associé à chaque LSP. Pour ce faire, il est nécessaire de prendre en compte les spécificités et outils du protocole GMPLS tel que le MBB et le XRO 1 .