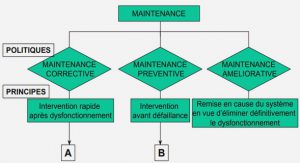
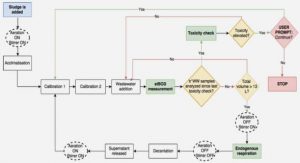
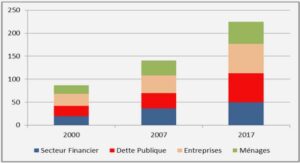
EXERCICES
EXERCICE 1 SÉCURITÉ DE BASE
La décision doit reposer sur la prise en considération de plusieurs points ; la liste ci-dessous n’est pas exhaustive. Aspects techniques. L’une des premières préoccupations doit être d’auditer le type de machine ainsi que le système d’exploitation sur lequel sera hébergé le SGBD. D’autre part, les SGBD sont gourmands en ressources de calcul et de stockage et il faut donc s’assurer que l’on disposera du nécessaire dans ces domaines. On peut supposer que la machine sera connectée à un réseau qu’il faut auditer également. De quel type de connexion dispose l’hébergeur, quels matériels de protection contre les intrusions utilise-t-il ? Le minimum est de disposer d’un dispositif de filtrage pour se protéger des intrusions liées au réseau. Un plus est de disposer de deux fournisseurs d’accès, l’un prenant le relais en cas de faille de l’autre. Enfin, quel matériel de sauvegarde peut-on utiliser, et de quelle taille de stockage disposet-on ? Une sauvegarde quotidienne est indispensable pour une base de données standard, c’est-à-dire sur laquelle les mises à jours sont raisonnablement fréquentes. En cas de mises à jour intensives, on peut prévoir de conserver plusieurs versions de la base sauvegardée. Aspects humains. Les machines et les réseaux aussi performants soient-ils sont gérés avant tout par des êtres humains. Il est donc essentiel de savoir combien de personnes assurent cette mission, et de quelle façon ; d’identifier la politique de sécurité générale : accès physique aux machines, protection contre les intrusions réseau et le suivi des incidents, mise à jour des machines, gestion des comptes …
EXERCICE 2 DISPONIBILITÉ DES DONNÉES
Quel type d’architecture permet de garantir en même temps la haute disponibilité des données et de disposer de sauvegarde ? Quels sont les inconvénients de ce système ?La haute disponibilité nécessite que l’accès aux données soit d’une part permanent et d’autre part performant. Afin de garantir que les données soient disponibles en permanence, on doit effectuer des copies à intervalles réguliers des données qui proviennent d’une base de données « primaire » vers des bases de sauvegarde « secondaires ». En cas de panne du primaire, on peut basculer rapidement vers l’un des secondaires. L’idéal est de disposer de plusieurs secondaires dans des lieux géographiquement éloignés, situés sur des réseaux (informatiques) différents. Disposer en outre d’un accès performant suppose que l’on utilise également les secondaires pour faire de la répartition de charge. Le système de répartition choisi doit tenir Quelles sont les vérifications de base indispensables avant de faire héberger un SGBD serveur de bases de données par une structure ?compte de la « proximité », au sens informatique, du serveur par rapport au client qui effectue la requête. Cette « proximité » peut être calculée en termes de distance – combien de nœuds du réseau sont traversés ? – mais également en termes de charge des branches du réseau. Il existe des outils capables de tenir à jour en permanence ce genre d’informations, mais ils sont assez complexes à gérer. Lors du choix de la machine vers laquelle on va rediriger la demande, on doit prendre en considération également sa charge et donc son aptitude à répondre rapidement. Les inconvénients d’une solution complète de ce type sont évidents. Les applications de répartition de charge sur un réseau standard sont déjà complexes à gérer ; on imagine bien qu’elles le sont d’autant plus lorsque l’on passe à une échelle supérieure. Un autre inconvénient est la difficulté de maintenir des copies des données à jour par rapport à la base primaire. Si les mises à jour sont très fréquentes, il devient difficile de disposer des mêmes données sur tous les secondaires. Une autre solution plus facile à gérer pour répartir « naturellement » la charge entre les serveurs consiste à répartir les données entre ces serveurs. Ainsi, cette opération se fait par l’architecture même de la base de données qui est dite « répartie ». En revanche, cette solution ne résout pas le problème de la recopie des données. Si l’un des serveurs tombe en panne, il n’existe pas, contrairement au système précédent, de mécanisme automatique pour le remplacer. On peut envisager des variantes qui panachent les deux systèmes : par exemple, on peut mettre en place un serveur maître qui recopie une partie des données sur les secondaires. Cette problématique générale est illustrée par les grands moteurs de recherche, ou encore les serveurs de vidéo qui utilisent plusieurs milliers de serveurs répartis sur le réseau Internet.
EXERCICE 3 NIVEAUX D’UTILISATION D’UNE BASE DE DONNÉES
La notion d’utilisateur ne représente pas forcément une personne physique ; il s’agit le plus souvent d’applications qui disposent ou non de droits sur certaines données. En première approche, on peut distinguer trois grandes catégories d’utilisateurs de la base de données. • Les clients peuvent consulter les informations les concernant ainsi que le catalogue des pizzas disponibles avec leur prix et leur composition. • L’activité courante, qui par conséquent va générer les mises à jour les plus fréquentes, est la commande de pizzas. Les utilisateurs concernés sont les employés qui mettent à jour les données de la table ‘commande’, mais également celles de la table ‘client’ pour créer de nouveaux clients le cas échéant. Ils ont accès en lecture à toutes les données des autres tables. • Enfin, les gestionnaires de l’activité doivent pouvoir mettre à jour toutes les informations de gestion : en particulier, celles sur les pizzas, les clients, les livreurs et les voitures utilisées. En revanche, on peut considérer qu’ils n’ont pas besoin de modifier les informations concernant les commandes, mais qu’ils doivent pouvoir y accéder en lecture. Lors de la conception d’une base de données, on doit envisager dès le début les différentes catégories d’utilisateurs qui vont l’utiliser. On considère l’exemple complet « livraison de pizzas » traité au chapitre 5, « Du langage parlé à SQL ». Quels niveaux d’utilisation des données doit-on prévoir ? On se limite aux grandes catégories.