Évaluation statistique des facteurs dans un modèle probabiliste
Circonscription de l’approche choisie
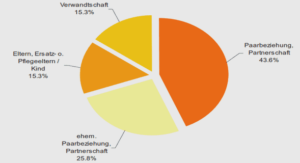
Comme noté ci-dessus, nous sommes intéressée dans une mesure du poids respectif des différents facteurs relevés dans cette thèse, dont nous avons vu qu’ils jouent un rôle dans le choix des expressions référentielles. Nous avons constaté et montré à l’aide de statistiques que, par exemple, la dislocation en français est parmi les expressions préférées dans l’expression du topic en français, et qu’elle joue également souvent un rôle dans des mouvements interactionnels qui effectuent un retour ou un décrochage par rapport au discours précédent. Mais quelle est l’interaction entre ces facteurs ? Est-ce que l’un prime sur l’autre ? Est-ce que les deux se combinent ? C’est à ce type de question que nous tenterons de répondre ici. Puisqu’il ne nous sera pas possible de traiter l’ensemble des expressions linguistiques, nous avons opéré des choix. Nous nous sommes focalisés dans cette thèse davantage sur la référence aux entités, et nous allons adopter également ce focus dans le présent chapitre. En ce qui concerne les noms, il aurait bien sûr été intéressant de comparer les emplois référentiels et non référentiels, mais cela n’aurait pas été pertinent pour les autres expressions considérées ici. Nous devons, pour des raisons de place, laisser de côté ici également la référence à la personne. Parmi les expressions en référence aux entités, nous avons choisi de porter notre intérêt sur les dislocations en français (en allemand, les occurrences sont trop peu fréquentes bien sûr pour une analyse statistique). Nous allons nous intéresser également aux noms, dont nous avons vu dans le chapitre précédent qu’ils peuvent aussi remplir les mêmes fonctions de mouvement interactionnel de RETOUR ou DECROCHAGE et dont nous supposons qu’ils pourraient jouer un rôle plus important en allemand, à la place des dislocations. Nous avons choisi de regarder également les D-Pro de l’allemand, catégorie qui apparaît pour le moment comme intermédiaire ou passe-partout : employée aussi bien pour la continuité que la discontinuité dans la chaîne topicale, nous allons examiner ici son emploi comme fonction de différents facteurs à la fois. Pour le français, nous allons examiner les pronoms démonstratifs et les pronoms personnels clitiques, catégories en construction/acquisition pour les jeunes enfants, et que nous souhaitons opposer aux D-Pro en allemand, qui lui ne fait que très peu usage de pronoms personnels dans la référence aux entités. Enfin, nous allons nous intéresser de plus près aux référents non-verbalisés, dont nous avons vu dans le chapitre précédent que leur emploi dans des mouvements interactionnels qui effectuent un retour sur ce qui précède mérite quelques affinements. Ce sont donc les expressions les plus importantes pour l’encodage du topic auxquels nous allons nous intéresser ici. Pour évaluer l’influence des différents facteurs étudiés sur le choix des expressions référentielles, nous ne pouvons pas nous tourner vers des modèles de régression paramétriques, puisque nos données ne suivent pas une distribution normale. Nous nous sommes alors tournée vers des modèles mixtes (Generalized Linear Mixed-Effects Models), que nous présenterons dans la section suivante.
Introduction du modèle et des facteurs
L’un des intérêts principaux des modèles mixtes est, comme le suggère leur nom, de pouvoir combiner des effets dits « fixes » et des effets aléatoires. Nous pouvons ainsi tester les effets pour lesquels nous pouvons établir une hypothèse forte, i.e. dont nous supposons qu’ils ont une influence sur le choix de l’expression référentielle,253 tout en prenant en compte la variabilité individuelle. En outre, ce test statistique ne requiert pas un nombre identique d’occurrences entre les différentes observations. Nous nous sommes servi de la fonction glmer du programme de statistiques R (R Core Team, 2018), implémentée dans le package lme4 (D. Bates, Maechler, Bolker, & Walker, 2015). Nous sommes partie, pour chaque expression référentielle étudiée dans ce chapitre, du modèle le plus complet théoriquement plausible, incluant des facteurs aléatoires et fixes, et avons procédé à une sélection du modèle le plus adapté par élimination successive des facteurs non significatifs (Zuur, Ieno, Walker, Saveliev, & Smith, 2009). Cette procédure sera précisée plus loin, après l’introduction des facteurs considérés.
Facteurs et variables retenus pour le calcul des effets aléatoires
Nous avons testé comme effet aléatoire la session d’enregistrement, l’enfant cible ainsi que le type de jeu (puzzle, dînette, maison de poupées..). L’influence du type de jeu a d’abord été testée comme effet fixe, mais n’apportait pas de pouvoir explicatif significatif aux modèles, les situations étant finalement trop hétérogènes. En effet, nous avons vu dans les chapitres précédents que le choix des expressions référentielles semble entre autres dépendre de certains genres et mouvements discursifs (nommer et localiser notamment pour les dislocations), et nos exemples ont montré que nous pouvions trouver des dénominations et demandes de dénominations dans les puzzles, mais aussi par exemple dans le jeu avec la maison de poupées. La façon dont nos participants ont investi les différentes situations de jeu semble alors trop hétérogène pour servir de prédicteur pour l’emploi d’une expression plutôt que d’une autre. Nous avons alors tenté de poser le jeu comme variable aléatoire, mais la variance observée pour les jeux dans ces modèles était Zero, lorsque nous prenions en compte aussi les autres effets aléatoires que sont l’enfant étudié et la session d’enregistrement. Pour une partie des enfants, nous disposons d’une seule session, et inclure à la fois la session et les enfants comme facteur aléatoire a également eu comme résultat de renvoyer une variance proche de Zero pour un des facteurs (Enfants), et d’empêcher le modèle à estimer correctement les effets. En effet, ces trois facteurs aléatoires se redoublent ou mesurent peu ou prou la même chose. Il fallait alors n’en retenir qu’un seul. La prise en compte de la session d’enregistrement donnait globalement les modèles les plus forts : c’est alors ce facteur que nous avons retenu comme variable aléatoire dans tous les modèles. Cela nous permet de tenir compte et de contrôler la variation individuelle, et de montrer quels effets fixes expliquent au mieux l’emploi d’une expression, au-delà des différences aléatoires. Les effets fixes considérés sont décrits dans la section suivante.
Facteurs et variables retenus pour le calcul des effets fixes
Nous avons considéré pour chaque modèle différents facteurs formels, informationnels et interactionnels. Certains des facteurs analysés dans les chapitres précédents ont été exclus d’emblée : Nous n’avons ainsi pas retenu la position de l’expression par rapport au verbe. D’une part, ce facteur est lié à d’autres contraintes formelles, et, comme nous l’avons expliqué dans le CHAPITRE VII-4.1, un véritable choix entre position pré- et postverbale est seulement donné dans des énoncés déclaratifs avec verbe en position V2 en allemand. D’autre part, il nous semble que la position dans l’énoncé relève davantage d’une variable dépendante que d’un facteur : il s’agit d’une coréalisation, conjointe au choix de la catégorie grammaticale, en fonction d’autres facteurs que nous étudions ici. Ces raisons valent aussi pour la réalisation prosodique, que nous n’avons pas incluse non plus dans les facteurs à considérer, mais plutôt étudié en tant que variable dépendante. Au vu des résultats des chapitres précédents, il nous a semblé plus intéressant de nous pencher sur la réalisation prosodique des expressions que sur la position par rapport au verbe, pour laquelle nous avons vu qu’elle dépend de différents facteurs à la fois, et qui donne des modèles peu parlants. Parmi les facteurs formels, nous avons considéré la fonction syntaxique. Nous avons considéré également comme facteur formel, pour le français, le cadre ou schème lexico-syntaxique étudié pour les dislocations (voir les CHAPITRE VIII-1.5 et CHAPITRE X). Nous nous sommes basée pour cela sur les schèmes identifiés comme fréquemment associés aux dislocations dans notre corpus, et nous les avons relevés aussi pour les autres expressions référentielles. Pour les facteurs fonctionnels, nous avons retenu plusieurs facteurs liés à la dimension pragmaticodiscursive. Nous avons considéré le statut de topic, la place dans la chaîne topicale, et les différents statuts attentionnels ou discursifs d’un référent. Pour le niveau interactionnel, nous avons regroupé différents phénomènes observés dans le chapitre précédent en une seule catégorie, prenant en compte tous les phénomènes de décrochage ou de RETOUR sur un TdP ou énoncé précédent. Nous avons également considéré à chaque fois le groupe MLU des enfants. Le principe de comparaison dans les modèles employés est un système binaire : toutes les catégories ont été converties en système binaire, i.e. une expression correspond au topic ou non, à la discontinuité topicale ou non, etc., exprimé par 0 ou 1. Le Tableau XI-1 ci-dessous détaille l’ensemble des facteurs retenus :Notons tout de suite que la colinéarité peut poser un problème pour les modèles mixtes, et qu’il n’était pas toujours possible de considérer tous les facteurs à la fois. Il nous fallait à chaque fois trouver un compromis pour les facteurs à considérer. Il faut comprendre la colinéarité comme le fait de mesurer plusieurs fois la même chose. Imaginons une catégorie qui corresponde toujours au topic de l’énoncé. Inclure dans ce cas les facteurs du statut de topic, de la continuité et de la discontinuité topicale revient alors de mesurer plusieurs fois la même chose, et empêche le modèle d’estimer correctement les variances dans les données. Nous avons donc essayé à chaque fois de trouver le meilleur compromis pour un modèle théoriquement valable et statistiquement plausible. Concrètement, cela veut dire que nous avons considéré le facteur TOPDISCONT plutôt que TOPCONTINU dans nos modèles, puisque l’inclusion des deux à la fois posait des problèmes pour une estimation correcte. Dans un souci de cohérence et de comparabilité des différents modèles, nous avons alors choisi de garder les mesures de discontinuité (topicale (TOPDISCONT) et interactionnelle (MVMT_RETOUR)), dont nous avons vu qu’ils sont pertinents pour l’emploi des dislocations.Les modèles que nous présenterons dans les sections suivantes sont le résultat d’une comparaison entre différents modèles possibles pour une catégorie d’expression donnée, pour trouver le modèle le mieux ajusté aux données. La procédure employée était de commencer avec le modèle le plus complexe théoriquement plausible (i.e., considérer tous les facteurs pour lesquels nous supposons une influence sur la variable dépendante, le choix de l’expression référentielle étudiée (plutôt que d’une autre expression). Les modèles sont évalués avec un index de concordance (valeur de C dans la première ligne de chaque table). Cette valeur indique la qualité d’ajustement (goodness of fit) du modèle en question.254 Nous avons procédé à des méthodes d’élimination (et parfois d’ajout) de facteurs par étapes, en évaluant la significativité de chaque facteur et en testant la qualité d’ajustement après suppression des variables non significatives. Différents modèles ont été comparés entre eux à l’aide d’un test du rapport de vraisemblance (likelihood-ratio test, fonction anova() dans R 255). Ce test nous permet d’évaluer si un modèle plus simple est statistiquement comparable au modèle plus complexe, et de choisir le modèle le mieux ajusté, i.e. qui a la meilleure probabilité de générer des distributions de données telles que nous les avons observées. Il faut tout de même ajouter que nous nous intéressons ici avant tout à expliquer les distributions observées, et nous nous servons des statistiques en ce sens, plutôt que de prétendre pouvoir établir des modèles avec un véritable pouvoir prédictif. Pour cela, des données plus homogènes, telles qu’obtenues dans un protocole expérimental seraient probablement nécessaires. Cela n’invalide pas les conclusions que nous allons tirer des modèles retenus, mais justifie que nous avons parfois privilégié l’ajustement le plus plausible en termes de théorie à l’ajustement purement mathématique.