Rappels sur la gestion de la haute disponibilité des systèmes dans le Cloud Computing
La haute disponibilité (HA) permet d’assurer et de garantir le bon fonctionnement en continu, sana défaillance des services ou applications et ce 7j/7 et 24h/24.
De nombreux services peuvent être utilisés pour assurer la disponibilité d’un service tels que : l’équilibrage de charge (Load Balancing), la tolérance aux pannes (Failover), la réplication des données, etc. pour limiter l’indisponibilité d’un SI.
La tolérance aux pannes
La tolérance aux pannes est la capacité du système à résister aux changements brusques qui se créent en raison de pannes matérielles, logicielles, congestions du réseau, etc.
La gestion des pannes dépend de deux paramètres importants que sont : le RPO (Recovery Point Objective) qui définit la quantité de données à perdre lors d’un sinistre et le RTO (Recovery Time Objective) qui détermine le temps d’arrêt minimum pour la récupération après un sinistre.
Il existe deux stratégies standards de tolérance aux pannes, à savoir la stratégie proactive et la stratégie réactive.
➢ La politique de tolérance aux pannes proactive [7] : le principe de cette politique est d’éviter les pannes en prenant de manière proactive des mesures préventives et remplacer les composants susceptibles de tomber en panne. Les techniques basées sur la politique proactive sont :
• La migration préventive : qui utilise un système de contrôle en boucle de rétroaction où les applications sont constamment surveillées et analysées.
• Rajeunissement du logiciel : avec cette technique des redémarrages périodiques sont programmés pour le système et après chaque redémarrage le système reprend avec un état neuf.
➢ La politique de tolérance aux pannes réactive [7] : cette politique est utilisée pour réduire l’effet des pannes qui sont déjà survenues. Sur la base de la politique de tolérance aux pannes réactive deux techniques sont utilisées :
• Checkpointing (point de contrôle) / Restart (redémarrage) : les tâches échouées sont redémarrées à partir du point de contrôle avant le point de défaillance plutôt que le point de départ. Cette technique est efficace pour les applications de grandes envergures dans le Cloud.
• Réplication : cette technique de réplication consiste à conserver plusieurs copies de données. Différents réplicas vont s’exécuter en utilisant des ressources différentes jusqu’à ce que la tâche soit terminée.
La réplication des données
La réplication est l’élément clé pour augmenter l’accessibilité, la tolérance aux pannes et la disponibilité dans tous les types de systèmes distribués.
Il existe deux types de réplications : la réplication synchrone et la réplication asynchrone
➢ La réplication synchrone : elle garantit que lorsqu’une transaction met à jour une réplique primaire, toutes ses répliques secondaires sont mises à jour dans la même transaction. L’avantage de la mise à jour synchrone est de garder toutes les données au même niveau de mise à jour. Alors le système peut garantir la fourniture de la dernière version des données quel que soit la réplique accédée [8].
➢ La réplication asynchrone : c’est le mode de distribution dans lequel certaines sous-opérations locales effectuée suite à une mise à jour globale sont accomplies dans des transactions indépendantes en temps différé [8].
Elle est basée sur deux approches :
• Approche basée sur l’état : la réplique source est mise à jour ensuite le sous-système transmet l’état sur les répliques par la fusion de l’état livré à l’état local
• Approche basée sur les opérations : le sous-système envoie l’opération de mise à jour et ses paramètres à toutes les répliques.
L’équilibrage de charge (Load Balancing)
L’équilibrage de charge est une partie importante qui garantit que tous les appareils ou processus effectuent la même quantité de travail dans le même temps. Avec le partage de charge, chaque nœud peut fonctionner et les données peuvent aussi être reçues et envoyées sans délai [9].
Dans le but de rendre les ressources accessibles aux utilisateurs finaux avec facilité et commodité, différents algorithmes pour l’équilibrage de charge ont été développés tels que : Round Robin, Weighted Round Robin, Least Connections, Weighted Least Connections, Random etc.
➢ Round Robin : c’est un algorithme qui est facile à mettre en œuvre. Par exemple soit deux serveurs en attente de requêtes derrière notre équilibreur de charge. Une fois que la première demande arrive, l’équilibreur transmettra cette demande dans le premier serveur. Lorsque la demande arrive (peut-être d’un autre client), cette demande sera transmise au deuxième serveur. Comme, le deuxième serveur est le dernier de ce cluster, la troisième requête sera renvoyée au premier serveur, la quatrième au deuxième serveur et ainsi de suite de manière cyclique.
L’algorithme Round Robin est le meilleur pour les clusters composés de serveurs avec les mêmes spécifications. Dans d’autres situations nous pouvons observer d’autres algorithmes, comme ceux-ci-dessous.
➢ Weighted Round Robin : cet algorithme est similaire au Round Robin car la façon dont les demandes sont attribuées aux nœuds est cyclique bien qu’elle soit tordue. Le nœud avec les spécifications les plus élevées aura un plus grand nombre de demandes.
Généralement, on spécifie des poids proportionnellement aux capacités réelles. De ce fait si la capacité du serveur 1 est 4 fois plus grande à celle du serveur 2, on peut lui donner un poids de 4 et le serveur 2 un poids de 1.
Figure 14: L’algorithme Weighted Round Robin
De la sorte, lorsque les clients commencent à arriver, les 4 premiers seront affectés au serveur 1 et le 5ème client au serveur 2. Si plus de clients arrivent, la même séquence sera suivie. Autrement dit le 6ème, 7ème, 8ème et le 9ème client iront dans le serveur 1 et le 10ème dans le serveur 2, ainsi de suite.
➢ Least Connections : cet algorithme prend en compte l’état (nombre de connexions) actuel de chaque serveur. Lorsqu’un client tente de se connecter, l’équilibreur essaie de déterminer quel serveur a le moins de connexion, puis attribue la nouvelle connexion à ce serveur.
Alors, si le 5ème client tente de se connecter après que le 1ère et le 3ème client soient déjà déconnectés mais que le 2ème et le 4ème soient toujours connectés, l’équilibreur de charge attribuera le 5ème client au serveur 1 au lieu du serveur 2.
Figure 15: L’algorithme Least Connection
➢ Weighted Least Connections : avec cet algorithme, un composant poids basé sur les capacités de chaque serveur est introduit. On doit spécifier au préalable le poids de chaque serveur comme dans le Weighted Round Robin.
Un équilibreur de charge qui implémente le Weighted Least Connections prendra désormais deux choses en considération : les poids/capacités de chaque serveur et le nombre actuel de clients connectés sur chaque serveur.
➢ Random : il met une correspondance aléatoire les clients et les serveurs, c’est-à-dire en utilisant un générateur de nombres aléatoires sous-jacent. Au cas où l’équilibreur de charge reçoit un grand nombre de requêtes, l’algorithme Random sera en mesure de distribuer les requêtes uniformément aux nœuds. Comme le Round Robin, le Random est suffisant pour les clusters constitués de nœuds avec des configurations identiques.
Gestion de la haute disponibilité des dispositifs
De nos jours, les systèmes de gestion de l’apprentissage (LMS) sont largement utilisés pour ajouter une valeur supplémentaire au processus d’apprentissage traditionnel. L’un des LMS open source les plus populaires est Moodle et est utilisé dans de nombreuses universités. Les données dans Moodle augmentent constamment avec de plus en plus d’utilisateurs (étudiants, etc.), de cours, de matériaux, de journaux, etc. Cela augmente le temps de réponse du serveur et entraîne une forte charge du serveur.
L’objectif principal de cette partie est de proposer une architecture Moodle hautement disponibilité. Puisque la plateforme e-learning choisi (Moodle) va s’intégrer avec BigBluButton, alors l’architecture va garantir la haute disponibilité de ces deux dispositifs.
Cependant, notons que la manière dont la haute disponibilité est gérée pour la plateforme Moodle est différente de celle utilisée pour BigBluButton.
Gestion de la haute disponibilité de Moodle
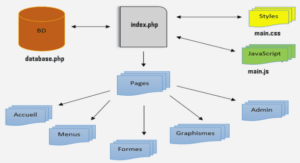
Une plateforme Moodle est constituée de trois (3) éléments que sont :
• Le code de Moodle (les fichiers PHP, JS, CSS, …) ;
• Le contenu de la base de données stocké dans une autre application type MySQL, PostgreSQL,… ;
• Et le dossier Moodledata.
Sans l’un de ces trois (3) éléments, la plateforme ne sera pas complète.
La conception de Moodle avec une séparation des couches d’application permet des configurations évolutives. D’ailleurs les grands sites séparent généralement le serveur web et la base de données sur des serveurs distincts.
Il est aussi possible d’équilibrer la charge d’une installation Moodle en utilisant plusieurs serveurs Web qui doivent interroger la même base de données et faire référence au même magasin de fichiers. De même, cette base de données peut être un cluster de serveurs.
Mais notons que, la méthode la plus rapide et la plus efficace que nous puissions faire pour améliorer les performances d’un serveur web Moodle est d’augmenter sa quantité de RAM par exemple 4 Go ou plus. L’augmentation de la mémoire permettra à un serveur web Moodle de gérer plus d’utilisateurs simultanément (50 utilisateurs simultanés par giga de ram).
Alors pour atteindre à la fois la haute disponibilité et la scalabilité de Moodle, nous allons :
➢ Utiliser un pool de serveurs web qui vont interroger un cluster de base de données.
➢ Les nœuds du cluster vont être tous des maîtres car Moodle repose beaucoup sur les interactions synchrones. Ainsi les utilisateurs peuvent écrire et lire sur n’importe quel nœud du cluster.
➢ Chaque serveur du pool sera configuré avec une quantité de RAM en fonction des besoins en nombre de connections.
Gestion de la haute disponibilité de BigBluButton
BigBluButton (BBB) : il fournit un large éventail de fonctionnalités de vidéoconférence (audio, vidéo, partage d’écran, tableau blanc, enregistrement de session, etc.) le tout sur une interface utilisateur simple et intuitive.
BBB fournit une solution libre-service, évolutive et conviviale qui permet aux utilisateurs de créer des comptes d’utilisateurs, de créer des réunions, d’inviter des utilisateurs qui peuvent ensuite confirmer l’invitation et de suivre si les utilisateurs y participent ou non, ainsi que de nombreuses autres fonctionnalités. La création de l’API BigBluButton sur les serveurs BigBluButton est nécessaire pour permettre aux applications clientes comme Moodle de créer des salles et des réunions sur l’une des instances de serveur.
Pour gérer la haute disponibilité de BigBluButton nous allons utiliser :
➢ Scalelite qui est un équilibreur de charge open-source, conçu spécifiquement pour BigBluButton, qui répartit uniformément la charge de réunion sur un pool de serveurs BigBluButton. Scalelite fait apparaître le pool de serveurs BigBluButton à notre application frontale Moodle, comme un serveur BigBluButton unique mais très évolutif. Scalelite a été publié par Blindside Networks sous licence AGPL le 13 mars 2020, en réponse à la forte demande des universités cherchant à faire évoluer BigBluButton suite à la pandémie COVID-19 [16].
Cependant pour accueillir un nombre important d’utilisateurs sur chaque serveur, les serveurs BigBluButton doivent chacun assurer une scalabilité verticale. Ainsi chacun d’eux sera configuré avec des capacités importantes pour garantir une scalabilité verticale. Et notons qu’un seul serveur BigBluButton qui répond à la configuration minimale prend en charge environ 200 utilisateurs simultanés.