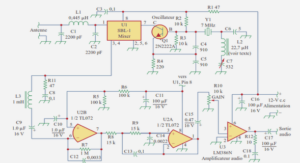
DIAGNOSTIC EMBARQUÉ APPLIQUÉ A UN
SYSTÈME MÉCANIQUE : MOTEUR DIESEL
Diagnostic des défaillances
L’objectif du diagnostic des défaillances est la détection et l’identification de l’état ou mode opérationnel d’un système dans l’instant actuel. La surveillance d’un système consiste à diagnostiquer ses états et modes défaillants. Le pronostic est la prédiction des possibles états futurs dans lesquels un système peut évoluer. Alors, une fois les états futurs identifiés, le pronostic nous permettrait d’estimer le temps de vie restant d’un système à partir de son état actuel jusqu’à un état défaillant [DIEZ LLEDO 08].
La surveillance
La surveillance est un dispositif passif, informationnel, qui analyse l’état du système et fournit des indicateurs. La surveillance consiste à détecter et classer les défaillances en observant l’évolution du système, puis à les diagnostiquer en localisant les éléments défaillants et en identifiant les causes premières. Donc la surveillance se décompose en deux fonctions qui sont la détection et le diagnostic [RACOCEANU 06]
La détection
Elle permet la détection des dysfonctionnements dans le système. Si l’on dispose d’un modèle nominal, un dysfonctionnement se caractérisera par l’éloignement des paramètres du procédé de ceux du modèle de bon fonctionnement. En présence d’un modèle de dysfonctionnement, la détection identifie clairement le défaut connu a priori [RIPOLL 99].
Le diagnostic
Le diagnostic est l’identification de la cause probable de la (ou des) défaillance(s) à l’aide d’un raisonnement logique fondé sur un ensemble d’informations provenant d’une inspection, d’un contrôle ou d’un test. [AFNOR, CEI], [BOUZIDI 16]. Il s’intègre dans le cadre plus général de la surveillance et de la supervision. Il consiste à localiser les éléments défaillants et à identifier les causes à l’origine du problème ; ceci en établissant un lien causal entre les symptômes et les éléments fautifs à remplacer. La phase qui suit correspond à la décision. Elle a pour rôle de déterminer et d’engager les actions permettant de ramener au mieux le système dans un état normal. La fonction de diagnostic se décompose en deux fonctions élémentaires, la première c’est la localisation et l’autre c’est l’identification des causes
Localisation
la localisation suit l’étape de détection ; elle a pour but de remonter à l’origine du défaut détecté.
Identification de défauts
la tâche d’identification a pour but de déterminer du type, de l’amplitude, de la localisation et des instants de détection des défauts. Généralités sur le diagnostic des systèmes
Terminologie de diagnostic
Nous présentons dans ce paragraphe la définition des termes principaux utilisée dans le domaine du diagnostic. Un défaut (fault) est considéré comme un écart du comportement normal. Il s’exprime par une déviation d’une propriété ou d’un paramètre caractéristique du procédé. Un défaut est donc une anomalie de comportement qui peut présager une défaillance à venir. Selon [ZWINGELSTEIN 95] un défaut est tout écart entre la caractéristique observée sur le dispositif et la caractéristique de référence lorsque celui-ci est en dehors des spécifications. Une défaillance est la cessation de l’aptitude d’un ensemble à accomplir sa ou ses fonctions requises avec les performances définies dans les spécifications techniques. Une panne est l’inaptitude d’une entité (composant ou système) à assurer une fonction requise. Elle provoque un arrêt complet du procédé. Validation de mesures Caractérisation du fonctionnement . Les pannes permanentes peuvent être la conséquence du changement progressif des caractéristiques d’un composant. Les pannes intermittentes sont très souvent le prélude à une panne permanente et expriment une dégradation progressive des performances du procédé [ALEXANDRE06]. La détection des défauts (fault detection) c’est la détermination des défauts et leurs instants de détection dans un système. L’isolation des défauts (fault isolation) consiste à déterminer le type de défaut, de la localisation et des instants de détection de ce dernier. L’identification des défauts est le fait d’estimer l’amplitude et l’évolution temporelle du défaut afin d’expliquer au mieux le comportement du système [GUILLAUME 05]
Classification des méthodes de diagnostic
Les méthodes de diagnostic utilisées dans l’industrie sont très variées. Leur principe général repose sur la comparaison entre les données observées au cours du fonctionnement du système et les connaissances acquises sur son comportement normal et ses comportements de défaillance [COMBACAU 91]. Les méthodes de diagnostic se distinguent selon la dynamique du procédé (discret, continu ou hybride), l’implémentation du diagnostic en ligne et/ou hors ligne, la nature de l’information (qualitative ou quantitative), … En général ces méthodes sont divisées en deux catégories : Les méthodes externes (model-free methods) qui sont des méthodes soient à base de connaissance, soient des méthodes empiriques et/ou de traitement du signal. Les méthodes internes (model-based methods) qui représentent des méthodes à base de modèles quantitatifs et/ou qualitatifs.
Méthodes externes
Les méthodes externes considèrent le système comme une boîte noire et elles utilisent uniquement un ensemble de mesures et/ou de connaissances heuristiques sur le système. Elles n’ont besoin d’aucun modèle mathématique pour représenter le fonctionnement du procédé. Ces méthodes comprennent les méthodes à base de reconnaissance des formes, de réseaux de neurones, ou de systèmes experts.
Reconnaissance des formes
Ces méthodes reposent sur l’utilisation des algorithmes de classification des formes et des mesures (continues ou discrètes). Le fonctionnement d’un système de diagnostic par reconnaissance des formes se déroule en trois phases [DERBEL 09]. Une phase d’analyse qui consiste à déterminer et à réduire l’espace de représentation des données et à définir l’espace de décision permettant de spécifier l’ensemble des classes possibles ; Généralités sur le diagnostic des systèmes 9 | P a g e Une phase de choix d’une méthode de décision permettant de définir une règle de décision qui a pour fonction de classer les nouvelles observations dans les différentes classes de l’ensemble d’apprentissage ; Une phase d’exploitation qui détermine, en appliquant la règle de décision, le mode de fonctionnement du système en fonction de chaque nouvelle observation recueillie sur le processus.
Réseaux de neurones
Un réseau de neurones artificiels est un modèle de calcul dont la conception est très schématiquement inspirée du fonctionnement des neurones biologiques. Ils sont des outils particuliers adaptés pour aider les spécialistes de maintenance dans ces activités de reconnaissance et de classification. Pour ces raisons. De nombreuses études pilotes sont entreprises dans le secteur de maintenance pour évaluer les apports des réseaux de neurones avant leur mise en œuvre de façon opérationnelle. Les réseaux de neurones sont des réseaux fortement connectés de processeur élémentaire fonctionnant en parallèle. Chaque processeur élémentaire calcule une sortie unique sur la base des informations qu’il reçoit [TOUZET 92]. Un RNA se compose typiquement d’une couche d’entrée, d’une ou de plusieurs couches intermédiaires ou cachées et d’une couche de sortie, chaque neurone est connecté à d’autres neurones d’une couche suivante par des poids synaptiques adaptables. La figure 1.2 illustre le schéma général d’un neurone. Chaque nœud i calcule la somme de ses entrées X Xn , , 1 , pondérées par les poids synaptiques i in , , 1 correspondants ; la valeur obtenue représente l’état interne du neurone i . Ce résultat est transmis à une fonction d’activation F. La sortie i y est l’activation du neurone [KEMPOWSKY 04]. Le modèle général du neurone est représenté par : N n i inX n 1 (1.1) i F i y (1.2) X1 Xn ui yi XN Figure 1.2 : Schéma général d’un neurone. Wi1 Win f WiN Généralités sur le diagnostic des systèmes 10 | P a g e (a) (b) (c) (d) Figure 1.3 : fonction d’activation les plus utilisées : (a) fonction à seuil, (b) fonction linéaire, (c) fonction sigmoïde, (d) fonction gaussienne. Le choix d’une fonction d’activation influx directement sur le réseau de neurones, c’est bien important de bien choisi pour l’obtention d’un modèle utile en pratique. La fonction d’activation fait transformer un signal d’entrée dans un neurone à un signal de sortie (réponse). Les fonctions d’activation les plus utilisés sont présentées via la figure
Systèmes experts
Un système expert utilise la connaissance correspondant à un domaine spécifique afin de fournir une performance comparable à l’expert humain. En général, les concepteurs des systèmes experts effectuent l’acquisition de connaissances grâce à un ou plusieurs interviews avec les experts du domaine. Les humains qui enrichissent le système avec leurs connaissances fournissent leur connaissance théorique ou académique et aussi des heuristiques qu’ils ont acquises grâce à l’utilisation de leurs connaissances [TOUZET 92]. La qualité première des systèmes experts réside dans leur efficacité au niveau temps de calcul. Le système doit simplement attendre les événements observables des règles pour sauter directement aux conclusions. Figure 1.4 : Architecture d’un système expert. EXPERT Base de connaissances Base de règles UTILISATEUR Moteur d’inférence Base de faits Généralités sur le diagnostic des systèmes 11 | P a g e Un système expert est composé de deux parties indépendantes [KEMPOWSKY 04] (voir Figure 1.4) : Une base de connaissance elle-même composé d’une base de règles qui modélise la connaissance du domaine considéré et d’une base de faits qui contient les informations concernant le cas traité, Un moteur d’inférences capables de raisonner à partir des informations contenues dans la base de connaissances, de faire des déductions,… etc. Au fur et à mesure que les règles sont appliquées des nouveaux faits se déduisent et se rajoutent à la base de faits.
Méthodes internes
Cette famille de méthodes est principalement dérivée de techniques utilisées par les automaticiens. À partir de modèles physiques ou de comportements validés par les techniques d’identification de paramètre, il devient possible de mettre en œuvre la méthode du problème inverse. Le diagnostic de défaillance est possible en suivant en temps réel l’évolution des paramètres physiques ou bien en utilisant de modèle de type boîte noire. Elles impliquent une connaissance approfondie du fonctionnement sous la forme de modèles mathématiques qui devront être obligatoirement validés expérimentalement avant toute utilisation industrielle. Les méthodes de diagnostic internes se regroupent en trois grandes familles : méthodes de modèle, méthodes d’identification de paramètre et les méthodes d’estimation du vecteur d’état.
Méthodes de modèle
Cette méthode consiste à comparer les grandeurs déduites d’un modèle représentatif du fonctionnement des différentes entités du processus avec les mesures réelles directement observées sur le processus industriel.
Méthodes d’identification de paramètre
Cette méthode s’applique dans les cas particuliers où l’on souhaite suivre l’évolution de certains paramètres physiques critiques pour le fonctionnement et qui ne sont pas mesurables directement [BDIRINA 06].
Méthodes d’estimation du vecteur d’état
La généralisation du principe de diagnostic de défaillance par la méthode de l’identification de paramètre a été rendue possible en considérant les modèles physiques d’un processus sous la forme d’équations d’état. Pour les systèmes à plusieurs entrées et à plusieurs sorties. Le modèle est constitué par un ensemble de n équations différentielles du premier ordre. Les n composantes du vecteur d’état x forment un espace à n dimensions appelées espace d’état. Généralités sur le diagnostic des systèmes 12 | P a g e Grâce à cette représentation d’état il est possible de connaître tous les états internes du processus. L’intérêt de cette représentation réside dans sa généralité. Elle peut être utilisée aussi bien pour les systèmes monovariables que multivariables. Les méthodes de diagnostic par les techniques du vecteur d’état sont performantes à la condition expresse que la structure du modèle reflète exactement le comportement du système. Dans le cas contraire les résultats des estimations sont à prendre avec beaucoup de précautions. Elles ont fait leurs preuves principalement dans les domaines du spatial et de l’aéronautique ou les modèles de la dynamique du vol sont parfaitement connus.
Méthodes des résidus
L’objectif du résidu est d’être sensible aux défauts. En cas d’absence de défaillance (fonctionnement normal), les résidus doivent avoir une valeur nulle. En présence d’un défaut, le résidu aura une valeur non nulle [Tatiana 04]. Les résidus représentent des changements (divergences) entre le comportement réel du processus et celui prévu par le modèle estimé. Le principe général pour la génération des résidus est illustré sur la figure ci-dessous. Figure 1.5 : Principe de génération des résidus Les techniques les plus utilisées pour la génération des résidus sont : les équations de parité, estimation d’état à partir d’observateurs ou filtres de KALMAN, Estimation paramétrique et analyse structurelle.
Espace de partie
Les méthodes du type d’équations de parité reposent sur la vérification d’une relation statique ou dynamique qui relie les mesures. L’espace de parité peut être vu comme l’espace des résidus possibles. Il est défini comme l’orthogonal de la matrice d’observabilité, ce qui revient à éliminer l’influence de l’état sur le résidu [CHRISTOPHE 00]. Sorties U Y Système θ Modèle estimé ߠ Génération de résidus Résidus ߠ ܻ r Généralités sur le diagnostic des systèmes 13 | P a g e
Observateur
Les méthodes de génération de résidus construites à l’aide d’observateurs reposent sur une estimation de l’état. Un observateur d’ordre réduit à ne considérer qu’une partie du système, donc à estimer une partie de l’état et à éliminer l’autre. Par ailleurs, l’estimation d’une partie du système peut être utilisée pour rejeter les perturbations (découplage direct).
CHAPITRE I : Généralités sur le diagnostic des systèmes |