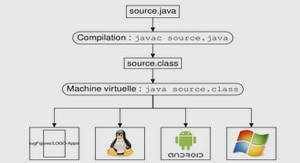
Support de cours Java les cinq étapes de la conception d’un objet, tutoriel & guide de travaux pratiques Java en pdf.
Les tableaux
Les tableaux ont déjà été introduits dans la dernière section du Chapitre 4, qui montrait comment définir et initialiser un tableau. Ce chapitre traite du stockage des objets, et un tableau n’est ni plus ni moins qu’un moyen de stocker des objets. Mais il existe de nombreuses autres manières de stocker des objets : qu’est-ce qui rend donc les tableaux si spécial ?
Les tableaux se distinguent des autres types de conteneurs sur deux points : l’efficacité et le type. Un tableau constitue la manière la plus efficace que propose Java pour stocker et accéder aléatoirement à une séquence d’objets (en fait, de références sur des objets). Un tableau est une simple séquence linéaire, ce qui rend l’accès aux éléments extrêmement rapide ; mais cette rapidité se paye : la taille d’un tableau est fixée lors de sa création et ne peut être plus être changée pendant toute la durée de sa vie. Une solution est de créer un tableau d’une taille donnée, et, lorsque celui-ci est saturé, en créer un nouveau et déplacer toutes les références de l’ancien tableau dans le nouveau. C’est précisément ce que fait la classe ArrayList, qui sera étudiée plus loin dans ce chapitre. Cependant, du fait du surcoût engendré par la flexibilité apportée au niveau de la taille, une ArrayList est beaucoup moins efficace qu’un tableau.
La classe conteneur vector en C++ connaît le type des objets qu’il stocke, mais il a un inconvénient comparé aux tableaux de Java : l’opérateur [] des vector C++ ne réalise pas de contrôle sur les indices, on peut donc tenter d’accéder à un élément au-delà de la taille du vector [44]. En Java, un contrôle d’indices est automatiquement effectué, qu’on utilise un tableau ou un conteneur – une exception RuntimeException est générée si les frontières sont dépassées. Comme vous le verrez dans le Chapitre 10, ce type d’exception indique une erreur due au programmeur, et comme telle il ne faut pas la prendre en considération dans le code. Bien entendu, le vector C++ n’effectue pas de vérifications à chaque accès pour des raisons d’efficacité – en Java, la vérification continuelle des frontières implique une dégradation des performances pour les tableaux comme pour les conteneurs.
Les autres classes de conteneurs génériques qui seront étudiés dans ce chapitre, les Lists, les Sets et les Maps, traitent les objets comme s’ils n’avaient pas de type spécifique. C’est à dire qu’ils les traitent comme s’ils étaient des Objects, la classe de base de toutes les classes en Java. Ceci est très intéressant d’un certain point de vue : un seul conteneur est nécessaire pour stocker tous les objets Java (excepté les types scalaires – ils peuvent toutefois être stockés dans les conteneurs sous forme de constantes en utilisant les classes Java d’encapsulation des types primitifs, ou sous forme de valeurs modifiables en les encapsulant dans des classes personnelles). C’est le deuxième point où les tableaux se distinguent des conteneurs génériques : lorsqu’un tableau est créé, il faut spécifier le type d’objets qu’il est destiné à stocker.
Ce qui implique qu’on va bénéficier d’un contrôle de type lors de la phase compilation, nous empêchant de stocker des objets d’un mauvais type ou de se tromper sur le type de l’objet qu’on extrait. Bien sûr, Java empêchera tout envoi de message inapproprié à un objet, soit lors de la compilation soit lors de l’exécution du programme. Aucune des deux approches n’est donc plus risquée que l’autre, mais c’est tout de même mieux si c’est le compilateur qui signale l’erreur, plus rapide à l’exécution et il y a moins de chances que l’utilisateur final ne soit surpris par une exception.
Du fait de l’efficacité et du contrôle de type, il est toujours préférable d’utiliser un tableau si c’est possible. Cependant, les tableaux peuvent se révéler trop restrictifs pour résoudre certains problèmes. Après un examen des tableaux, le reste de ce chapitre sera consacré aux classes conteneurs proposées par Java.
Les tableaux sont des objets
Indépendamment du type de tableau qu’on utilise, un identifiant de tableau est en fait une référence sur un vrai objet créé dans le segment. C’est l’objet qui stocke les références sur les autres objets, et il peut être créé soit implicitement grâce à la syntaxe d’initialisation de tableau, soit explicitement avec une expression new. Une partie de l’objet tableau (en fait, la seule méthode ou champ auquel on peut accéder) est le membre en lecture seule length qui indique combien d’éléments peuvent être stockés dans l’objet. La syntaxe « [] » est le seul autre accès disponible pour les objets tableaux.
L’exemple suivant montre les différentes façons d’initialiser un tableau, et comment les références sur un tableau peuvent être assignées à différents objets tableau. Il montre aussi que les tableaux d’objets et les tableaux de scalaires sont quasi identiques dans leur utilisation. La seule différence est qu’un tableau d’objets stocke des références, alors qu’un tableau de scalaires stocke les valeurs directement.
Le tableau a n’est initialement qu’une référence null, et le compilateur interdit d’utiliser cette référence tant qu’elle n’est pas correctement initialisée. Le tableau b est initialisé afin de pointer sur un tableau de références Weeble, même si aucun objet Weeble n’est réellement stocké dans le tableau. Cependant, on peut toujours s’enquérir de la taille du tableau, puisque b pointe sur un objet valide. Ceci montre un inconvénient des tableaux : on ne peut savoir combien d’éléments sont actuellement stockés dans le tableau, puisque length renvoie seulement le nombre d’éléments qu’on peut stocker dans le tableau, autrement dit la taille de l’objet tableau, et non le nombre d’éléments qu’il contient réellement. Cependant, quand un objet tableau est créé, ses références sont automatiquement initialisées à null, on peut donc facilement savoir si une cellule du tableau contient un objet ou pas en testant si son contenu est null. De même, un tableau de scalaires est automatiquement initialisé à zéro pour les types numériques, (char)0 pour les caractères et false pour les booleans.
Le tableau c montre la création d’un objet tableau suivi par l’assignation d’un objet Weeble à chacune des cellules du tableau. Le tableau d illustre la syntaxe
d’« initialisation par agrégat » qui permet de créer un objet tableau (implicitement sur le segment avec new, comme le tableau c) et de l’initialiser avec des objets Weeble, le tout dans une seule instruction.
L’initialisation de tableau suivante peut être qualifiée d’« initialisation dynamique par agrégat ». L’initialisation par agrégat utilisée par d doit être utilisée lors de la définition de d, mais avec la seconde syntaxe il est possible de créer et d’initialiser un objet tableau n’importe où. Par exemple, supposons que hide() soit une méthode qui accepte un tableau d’objets Weeble comme argument. On peut l’appeler via :
hide(d);
mais on peut aussi créer dynamiquement le tableau qu’on veut passer comme argument :
hide(new Weeble[] { new Weeble(), new Weeble() });
Cette nouvelle syntaxe est bien plus pratique pour certaines parties de code.
L’expression :
a = d;
montre comment prendre une référence attachée à un tableau d’objets et l’assigner à un autre objet tableau, de la même manière qu’avec n’importe quel type de référence. Maintenant a et d pointent sur le même tableau d’objets dans le segment.
La seconde partie de ArraySize.java montre que les tableaux de scalaires fonctionnent de la même manière que les tableaux d’objets sauf que les tableaux de scalaires stockent directement les valeurs des scalaires.
Conteneurs de scalaires
Les classes conteneurs ne peuvent stocker que des références sur des objets. Un tableau, par contre, peut stocker directement des scalaires aussi bien que des références sur des objets. Il est possible d’utiliser des classes d’« encapsulation » telles qu’Integer, Double, etc. pour stocker des valeurs scalaires dans un conteneur, mais les classes d’encapsulation pour les types primitifs se révèlent souvent lourdes à utiliser. De plus, il est bien plus efficace de créer et d’accéder à un tableau de scalaires qu’à un conteneur de scalaires encapsulés.
Bien sûr, si on utilise un type primitif et qu’on a besoin de la flexibilité d’un conteneur qui ajuste sa taille automatiquement, le tableau ne convient plus et il faut se rabattre sur un conteneur de scalaires encapsulés. On pourrait se dire qu’il serait bon d’avoir un type ArrayList spécialisé pour chacun des types de base, mais ils n’existent pas dans Java. Un mécanisme de patrons permettra sans doute un jour à Java de mieux gérer ce problème [45].
Renvoyer un tableau
Supposons qu’on veuille écrire une méthode qui ne renvoie pas une seule chose, mais tout un ensemble de choses. Ce n’est pas facile à réaliser dans des langages tels que C ou C++ puisqu’ils ne permettent pas de renvoyer un tableau, mais seulement un pointeur sur un tableau. Cela ouvre la porte à de nombreux problèmes du fait qu’il devient ardu de contrôler la durée de vie du tableau, ce qui mène très rapidement à des fuites de mémoire.
Java utilise une approche similaire, mais permet de « renvoyer un tableau ». Bien sûr, il s’agit en fait d’une référence sur un tableau, mais Java assume de manière transparente la responsabilité de ce tableau – il sera disponible tant qu’on en aura besoin, et le ramasse-miettes le nettoiera lorsqu’on en aura fini avec lui.
La méthode flavorSet() crée un tableau de Strings de taille n (déterminé par l’argument de la méthode) appelé results. Elle choisit alors au hasard des parfums dans le tableau flav et les place dans results, qu’elle renvoie quand elle en a terminé. Renvoyer un tableau s’apparente à renvoyer n’importe quel autre objet – ce n’est qu’une référence. Le fait que le tableau ait été créé dans flavorSet() n’est pas important, il aurait pu être créé n’importe où. Le ramasse-miettes s’occupe de nettoyer le tableau quand on en a fini avec lui, mais le tableau existera tant qu’on en aura besoin.
Notez en passant que quand flavorSet() choisit des parfums au hasard, elle s’assure que le parfum n’a pas déjà été choisi auparavant. Ceci est réalisé par une boucle do qui continue de tirer un parfum au sort jusqu’à ce qu’elle en trouve un qui ne soit pas dans le tableau picked (bien sûr, on aurait pu utiliser une comparaison sur String avec les éléments du tableau results, mais les comparaisons sur String ne sont pas efficaces). Une fois le parfum sélectionné, elle l’ajoute dans le tableau et trouve le parfum suivant (i est alors incrémenté).
main() affiche 20 ensembles de parfums, et on peut voir que flavorSet() choisit les parfums dans un ordre aléatoire à chaque fois. Il est plus facile de s’en rendre compte si on redirige la sortie dans un fichier. Et lorsque vous examinerez ce fichier, rappelez-vous que vous voulez juste la glace, vous n’en avez pas besoin.
La classe Arrays
java.util contient la classe Arrays, qui propose un ensemble de méthodes static réalisant des opérations utiles sur les tableaux. Elle dispose de quatre fonctions de base : equals(), qui compare deux tableaux ; fill(), pour remplir un tableau avec une valeur ; sort(), pour trier un tableau ; et binarySearch(), pour trouver un élément dans un tableau trié. Toutes ces méthodes sont surchargées pour tous les types scalaires et les Objects. De plus, il existe une méthode asList() qui transforme un tableau en un conteneur List – que nous rencontrerons plus tard dans ce chapitre.
Bien que pratique, la classe Arrays montre vite ses limites. Par exemple, il serait agréable de pouvoir facilement afficher les éléments d’un tableau sans avoir à coder une boucle for à chaque fois. Et comme nous allons le voir, la méthode fill() n’accepte qu’une seule valeur pour remplir le tableau, ce qui la rend inutile si on voulait – par exemple – remplir le tableau avec des nombres aléatoires.
Nous allons donc compléter la classe Arrays avec d’autres utilitaires, qui seront placés dans le package com.bruceeckel.util. Ces utilitaires permettront d’afficher un tableau de n’importe quel type, et de remplir un tableau avec des valeurs ou des objets créés par un objet appelé générateur qu’il est possible de définir.
Du fait qu’il faille écrire du code pour chaque type scalaire de base aussi bien que pour la classe Object, une grande majorité de ce code est dupliqué [46]. Ainsi, par exemple une interface « générateur » est requise pour chaque type parce que le type renvoyé par next()
Préface
Introduction
1) Introduction sur les Objets
Les bienfaits de l’abstraction
Un objet dispose d’une interface
L’implémentation cachée
Réutilisation de l’implémentation
Héritage : réutilisation de l’interface
Les relations est-un vs. est-comme-un
Polymorphisme : des objets interchangeables
Les langages de script
Analyse et conception
Phase 0 : Faire un plan
L’exposé de la mission
Phase 1 : Que construit-on ?
Phase 2 : Comment allons-nous le construire ?
Les cinq étapes de la conception d’un objet
Indications quant au développement des objets
Phase 3 : Construire le coeur du système
Phase 4 : Itérer sur les cas d’utilisation
Phase 5 : Evolution
Les plans sont payants
Règles de base
1. Cours
2. Projet à faible risque
3. S’inspirer de bonnes conceptions
4. Utiliser les bibliothèques de classes existantes
5. Ne pas traduire du code existant en Java
2 : Tout est Objet
Les objets sont manipulés avec des références
Vous devez créer tous les objets
Où réside la mémoire ?
Cas particulier : les types primitifs
Nombres de grande précision
Tableaux en Java
Vous n’avez jamais besoin de détruire un objet
Notion de portée
Portée des objets
Créer de nouveaux types de données : class
Champs et méthodes
Valeurs par défaut des membres primitifs
Méthodes, paramètres et valeurs de retour
La liste de paramètres
Construction d’un programme Java
Visibilité des noms
Utilisation d’autres composantes
Le mot-clef static
Votre premier programme Java
Compilation et exécution
Commentaires et documentation intégrée
Commentaires de documentation
Syntaxe
Les onglets de documentation de variables
Les onglets de documentation de méthodes
Exercices
3 : Contrôle du Flux de Programme
Utilisation des opérateurs Java
Priorité
L’affectation
L’aliasing pendant l’appel des méthodes
Les opérateurs mathématiques
Les opérateurs unaires (à un opérande) moins et plus
Incrémentation et décrémentation automatique
Les opérateurs relationnels
Tester l’équivalence des objets
L’opérateur virgule
L’opérateur + pour les String
4: Initialisation & Nettoyage
Garantie d’initialisation grâce au constructeur
Surcharge de méthodes
Différencier les méthodes surchargées
Résumé
Exercices
5 : Cacher l’Implémentation
package : l’unité de bibliothèque
Créer des noms de packages uniques
Collisions
Une bibliothèque d’outils personnalisée
Utilisation des imports pour modifier le comportement
Avertissement sur les packages
Les spécificateurs d’accès Java
Exercices
6 : Réutiliser les classes
Syntaxe de composition
La syntaxe de l’héritage
Initialiser la classe de base
Constructeurs avec paramètres
Attraper les exceptions du constructeur de base
Combiner composition et héritage
Traduction de « Thinking
7: Polymorphisme
Upcasting
Pourquoi utiliser l’upcast?
The twist
Liaison de l’appel de méthode
Produire le bon comportement
Extensibilité
Redéfinition et Surcharge
8 : Interfaces & Classes Internes
Interfaces
« Héritage multiple » en Java
Combinaison d’interfaces et collisions de noms
Etendre une interface avec l’héritage
Groupes de constantes
Initialisation des données membres des interfaces
Interfaces imbriquées
Exercices
9 : Stockage des objets