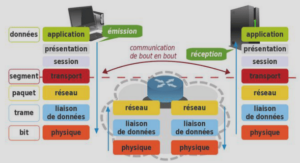
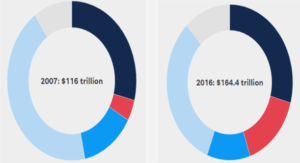
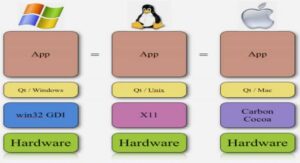
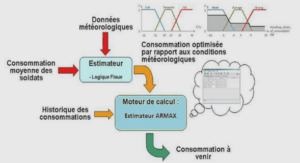
Conception des chaînes logistiques : Problème de localisation
Nous présentons dans cette section certains modèles de localisation-allocation qui constituent la base des problèmes de conception des réseaux de distribution. Tout une ligne de recherche s’est développée autour de l’un des tous premiers pionniers de la théorie de la localisation [Weber, 1909]. Le livre publié par Weber constitue l’un des premiers apports théoriques sur les facteurs clés de localisation des industries/entreprises à l’échelle régionale ou nationale. [Weber, 1909] prend en compte les coûts de transport des produits, les coûts de la main d’œuvre et les économies d’agglomération (réduction des taxes par exemple) que propose un grand marché urbain. A partir de ces facteurs, il définit la localisation optimale pour chaque entreprise qui a pour objectifs de minimiser les coûts de production et satisfaire les demandes du marché. Depuis les travaux de Weber, plusieurs travaux ont été réalisés traitant des problèmes de localisation allocation.
Modèles déterministes
Le problème de localisation-allocation résulte de deux problèmes de prise de décision à différents niveaux : niveau stratégique (décision de localisation) et niveau tactique (décision d’allocation). Dans [Martel, 2001], l’auteur présente un problème de localisation pure. L’auteur propose une formulation du problème: soit J sites (centres de distribution, productions, entrepôts, …etc.) à localiser dans un ensemble S de sites potentiels (emplacements), où J ⊆ S. Il se place dans le cas où les flux des produits qui circulent à travers chacun des sites sont connus. Toutefois, les coûts d’implantation et d’opération d’un site dépendent de l’endroit où il se situe. Le problème consiste à chercher la meilleure localisation des J sites de façon à minimiser une fonction coût total linéaire.
A présent, nous considérons les problèmes de localisation-allocation. Le plus souvent, les décisions de localisation et les décisions d’allocation doivent être prises simultanément. Nous présentons ci-dessous les modèles déterministes qui constituent la base de ces problèmes. Nous citons ici à titre d’exemples (i) le problème P médian « P-median problem » (ii) le problème de recouvrement « set covering problem » et le problème de couverture maximale « maximal covering problem » (iii) le problème du centre « center problem ».
[Hakimi, 1964] propose une méthode par simple énumération. [Garey et al., 1979] montre que le problème est NP-difficile. Plusieurs méthodes heuristiques ont été développées. Certaines permettent d’obtenir de bonnes solutions ou bien de calculer des solutions intermédiaires lors d’utilisation des méthodes de séparation et évaluation; les travaux de [Maranzana, 1964] et [Teitz et al., 1968] en sont des exemples. Par ailleurs [Efroymson et al., 1966] et [Jarvinen et al., 1972] proposent une méthode par séparation et évaluation (Branch & Bound). Dans [Galvão et al., 1989] et [Beasley, 1993], les auteurs proposent également une méthode par séparation et évaluation. Ils proposent aussi une méthode basée sur la relaxation lagrangienne et le problème dual est résolu par la technique d’optimisation par le sous gradient.
Pour résoudre le problème de « set covering problem », [Garfinkel et al., 1972] propose un algorithme de Branch & Bound. Celui-ci reprend l’architecture générale d’une méthode de Branch & Bound mais en utilisant des règles d’évaluation et de parcours de l’arbre de recherche bien adaptées. Dans [Feo et al., 1994], les auteurs utilisent une métaheuristique GRASP (Greedy Randomized Adaptative Search Procedures) pour résoudre le problème. Le principe général de GRASP consiste à utiliser plusieurs fois un algorithme glouton choisissant les variables fixées de manière partiellement aléatoire puis à améliorer les différentes solutions ainsi trouvées grâce à une recherche locale. Une approche par relaxation lagrangienne est proposée par [Beasley, 1990]. De même, [Beasley et al., 1996] propose une méthode d’optimisation par les algorithmes génétiques. Pour une analyse plus complète du problème de recouvrement, les articles [White et al., 1974] et [Schilling et al., 1993] sont de bonnes références.
Les problèmes de recouvrement, de P-median et du centre présentés ci dessus constituent une base solide des modèles déterministes rencontrés dans la théorie des problèmes de localisation. Dans la suite, nous présentons d’autres formulations classiques rencontrées dans la littérature dédiée au problème de localisation. En effet, le premier problème classique de localisation est celui de « Fixed Charge Facility Location Problem ». Pour ce problème, toutes les données sont connues de manière déterministe. L’objectif consiste à trouver les meilleures localisations des sites (usines/centres de distribution) et les modes de transport à utiliser pour servir les différentes zones de demande tout en minimisant les coûts fixes de localisation et de transport sous la contrainte que toutes les demandes soient satisfaites. Il existe deux versions du problème : (i) le problème où la capacité des sites est illimitée « uncapacitated fixed charge facility location problem (UCFLP) » et (ii) le problème où les sites ont une capacité finie (capacitated plant location problem (CPLP)).
Geoffrion et al., 1974] montrent qu´en utilisant la méthode par séparation et évaluation, la méthode par relaxation lagrangienne est très efficace dans la recherche d’une solution optimale. Dans le même article, les auteurs tiennent compte de l’activité de transport entre les fournisseurs et les centres de distribution. Dans [Daskin, 1995] et [Galvao et al., 1993], les auteurs utilisent des méthodes basées sur la relaxation lagrangienne pour résoudre le problème. Une méthode efficace basée sur la recherche du voisinage utilisée aussi dans la résolution du problème Pmedian est proposée dans [Hansen et al., 1997]. Par ailleurs, [Al-Sultan et al., 1999] proposent une méthode de recherche Tabou pour résoudre le problème. La méthode a été testée avec succès mais sur des problèmes de tailles faibles.
Modèles stochastiques
La plupart des travaux rapportés dans la littérature traitant des problèmes de localisation présentent des modèles déterministes connus comme NP-difficiles et par conséquent extrêmement difficiles à résoudre. Malgré la formulation assez convenable des modèles déterministes, ceux ci ne présentent pas avec fidélité la réalité. C’est la raison pour laquelle, récemment, plusieurs auteurs ont essayé de relâcher certaines des hypothèses simplistes des modèles déterministes en introduisant des aspects liés à l’incertitude comme les demandes clients, les délais d’approvisionnement, l’indisponibilité des sites, …etc.
[Manne, 1961] est l’un des premiers auteurs à introduire l’incertitude dans les données lors de l’étude des problèmes de localisation. L’auteur s’intéresse au problème d’expansion des capacités des sites sur un horizon infini lorsque les demandes clients suivent une certaine loi de probabilité. Avec l’hypothèse que les demandes non satisfaites sont mises en attente pour une nouvelle commande. Une analyse de sensibilité en perturbant la variance des demandes est proposée. Il montre que lorsque la variance de demande augmente, les coûts d’expansion des sites augmentent. Dans [Bean et al., 1992], les auteurs relaxent certaines hypothèses de [Manne, 1961] en supposant une demande discrète ou continue et considèrent que les demandes non satisfaites sont perdues. Cependant, ils supposent qu’un site de capacité finie est ajouté si un site existant est défaillant.
[Mirchandani, 1980] et [Mirchandani et al., 1979] proposent une extension du problème Pmedian de Hakimi en supposant une variation des connexions de transport. Les auteurs montrent que la démonstration proposée par Hakimi sur l’existence d’une solution optimale en un point d’un nœud du réseau, peut être généralisée dans le cas des réseaux stochastiques. [Berman et al., 1984] et [Berman et al., 1982] proposent une extension de l’analyse faite par [Mirchandani et al., 1979] en introduisant la possibilité de re-localiser un ou plusieurs de P sites au cas où il y aurait des changements sur le temps de livraison. Ils définissent l’état du système de telle sorte que chaque état est différent des autres par un changement de temps de transport sur une connexion du réseau. Dans tous ces travaux, le problème P median est modélisé par une matrice de transition de Markov. [Berman et al., 1982] proposent une heuristique de substitution pour déterminer la localisation ou la re localisation optimale d’un site dans cet environnement multi variant.
Dans [Aikens, 1985], l’auteur présente une version stochastique du problème (CPLP) où il considère que la demande client est aléatoire. Le modèle permet de localiser de nouveaux sites dans un réseau où il existe déjà des sites localisés. Pour résoudre le problème, l’auteur propose une méthode combinant une méthode de séparation et évaluation développée par [Balachandran et al., 1974] et une méthode heuristique proposées par [LeBlanc, 1977]. De plus, [Aikens, 1985] rapporte sur l’insuffisance et la faiblesse des modèles déterministes existants et propose en perspective d’étendre ces modèles aux problèmes dynamiques multi produits et d’élargir ainsi le champ des contraintes. Dans [França et al., 1982], les auteurs utilisent la méthode de décomposition de Benders pour résoudre une combinaison du problème (CPLP) avec un problème de transport stochastique où la demande client est aléatoire. Dans [Louveaux, 1986], l’auteur présente des versions stochastiques du problème P median et du problème (CPLP). L’auteur considère que la demande des clients, les coûts de production et de transport sont des variables aléatoires. L’objectif est de déterminer la localisation des sites, la capacité des sites et la meilleure allocation des clients aux sites dans le but de maximiser le profit du système.
[Ricciardi et al., 2002] considère un problème de localisation en supposant des coûts aléatoires d’exploitation dans les centres de distribution. L’objectif est de minimiser le coût total de transport entre les centres de production et les centres de distribution et entre les centres de distribution les zones de demande (clients), plus le coût total moyen d’exploitation des centres de distribution. Ils supposent au préalable que la localisation des centres de distribution est connue et s’intéressent aux flux de matière dans le réseau. Le problème est modélisé comme un programme mathématique non linéaire avec variables entières. Pour résoudre le problème, une méthode heuristique passée sur la relaxation lagrangienne est proposée.
Dans [Snyder, 2003] et [Snyder, 2004], l’auteur présent un état de l’art très riche des modèles stochastiques existants ainsi que des méthodes de résolution développées. La plupart des modèles ont comme objectif la minimisation des coûts ou la maximisation du profit de l’ensemble du réseau logistique. Certains modèles sont développés en utilisant des approches probabilistes, d’autres des approches dynamiques. L’auteur rapporte que les méthodes développées utilisent le plus souvent des heuristiques basées sur la relaxation lagrangienne, la recherche Tabou, les algorithmes génétiques, …etc. D’autres méthodes utilisent la technique généralisée de programmation stochastique.
Pour certains problèmes frontières, [Eppen et al., 1989] se sont intéressés aux problèmes de localisation avec choix des configurations des usines lorsque le prix des produits et les demandes clients sont aléatoires durant un horizon de planification. [Goetschalckx et al., 1999] ont étudié un problème de localisation des centres de distribution avec des demandes clients saisonnières et deux échelons de production, où chaque production nécessite un choix d´équipement. [Paquet et al., 2001] proposent un modèle de localisation incluant les décisions de configuration des centres de production lorsque la chaîne logistique fabrique des produits avec des nomenclatures complexes.
Introduction Générale |