Cours bilan de la variabilité génétique du Mérinos de Rambouillet, tutoriel & guide de travaux pratiques en pdf.
Composition des échantillons analysés
Depuis 1786, date de création de la race, chaque animal est en théorie répertorié dans un fichier généalogique papier. Cependant, nous analyserons le fichier informatique dont on dispose aujourd’hui : l’animal le plus vieux répertorié est né en 1962. L’étude démographique du troupeau menée par Pro d’homme (1986), qui avait utilisé les documents sur papier disponibles, remonte plus loin, à partir de 1866, e t se termine en 1983. Notre travail pourra ainsi entrer en continuité avec le sien.
Ce fichier des généalogies répertorie 3130 animaux, dont 1483 mâles et 1647 femelles, nés entre 1962 et 2006.
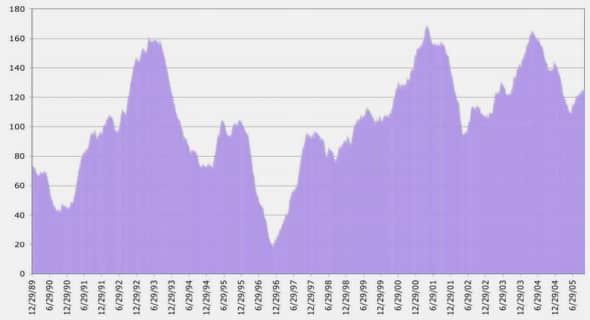
La répartition des effectifs par année de naissance(figure 6) montre une augmentation progressive des effectifs enregistrés jusqu’aux années 1980, puis une stabilisation jusqu’à nos jours, avec une année 1993 extraordinaire qui présente une anomalie certainement due à des défauts d’enregistrement.
Figure 6 : Répartition de l’effectif total du fichier généalogies du troupeau Mérinos de Rambouillet par millésime (d’après la base de données nationale).
Parmi les animaux enregistrés dans cette base de données, nous avons choisi cinq échantillons sur lesquels analyser la variabilité énérgetique :
• Les mâles actifs entre 1984 et 1986 : 28 animaux
• Les mâles actifs entre 1994 et 1996 : 28 animaux
• Les mâles actifs entre 2004 et 2006 : 37 animaux
• Les mâles actifs en 2006 : 18 animaux
• Les femelles actives en 2006 : 168 animaux.
Par définition, un « reproducteur actif » est un reproducteur ayant eu des descendants à la campagne suivante.
Le choix des trois premiers échantillons nous permet d’étudier l’évolution de la variabilité génétique, alors que les deux derniers nous renseignent sur la situation actuelle.
Cet échantillonnage a été choisi parmi les animaux à partir de 1984, car les informations du fichier généalogique nous semblent les plus fiables à partir de cette époque, le nombre d’animaux enregistrés étant plus important. Les échantillons ont été sélectionnées arbitrairement afin d’être bien répartis dans le temps (10 ans d’intervalle entre chaque échantillon), et de comporter un nombre d’animaux relativement homogène.
Comme ces échantillons proviennent du fichier national informatisé (aussi appelé Base de Données Nationale) dont la qualité est limitée voir( Palhière et al., 2006), les résultats obtenus sont souvent biaisés.
Paramètres retenus et moyens informatiques utilisés.
Le plan et les paramètres analysés présentés dans cette partie sont inspirés de diverses études similaires précédemment publiées. Citons tudel’é des races bovines à très petits effectifs (Danchin-Burge et Avon, 2000 ; Avon et au Colle, 2006), des races ovines laitières (Palhière et al., 2000) et bovines laitières (Moureaux et al., 1996 et 2000), et enfin, de six races ovines allaitantes (Huby et al., 2003).
Caractérisation de la richesse de l’information généalogique disponible
Tout d’abord, l’étude portera sur le fichier des généalogies, qui permet de caractériser l’information généalogique dont on dispose, base del’analyse de la variabilité fondée sur les pedigrees. L’information généalogique est un outild’évaluation de la variabilité génétique, mais sa fiabilité dépend de la rigueur d’enregistrement des généalogies. (Verrieret al., 2005).
Nombre d’ancêtres et parents connus
La qualité de l’information généalogique s’évaluearp l’étude du nombre d’ancêtres et de parents connus. Ce critère a été utilisé auparantv pour l’estimation de la variabilité génétique des races bovines laitières françaises par Moureaux et al., (1996 puis 2000).
Nombre d’Equivalents générations
Un autre critère caractérisant notre connaissance des généalogies est le nombre d’équivalents générations connus (EqG). Il s’obtient en sommant les coefficients (1/2)n sur tous les ancêtres connus, n étant le rang d’ascendance de l’ancêtre. Un parent compte ainsi pour 0,5 et un grand-parent pour 0,25.
Appréciation de la variabilité génétique. i. Consanguinité et apparentement
L’intérêt d’étudier la consanguinité lors de l’étude e la variabilité génétique a été abordé p. 16 et 31. L’étude de l’évolution du coefficient de consanguinité sur une période choisie et de l’apparentement intra et inter échantillons sont des indicateurs de l’évolution de la variabilité génétique. Ces paramètres ont étélculésca à la SAGA par le programme PARENTE (Boichard, 2002), qui donne les coefficients de parenté entre les échantillons choisis, et par le logiciel PEDIG.
Les logiciels permettant l’obtention de ces données brutes que nous avons analysées ont été manipulés par Isabelle Palhière.
Probabilité d’origine des gènes
Les critères de probabilité d’origine des gènes (définis p. 31 à 33), que nous avons analysés et comparés à d’autres races, ont été calculés grâce aux logiciels cités ci-dessus manipulés par Isabelle Palhière.