Approche semi-classique de l’information quantique
Genèse de l’information quantique et conjecture de Moore
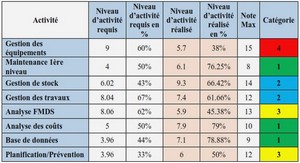
Depuis le début des années 70, date à laquelle est commercialisé le premier microprocesseur Intel 4004 (doté alors de 2300 transistors à 4 bits), les microprocesseurs n’ont eu de cesse d’augmenter leur puissance de calcul par l’augmentation de leur densité de transistors. En 1965, Gordon Moore publie dans la revue Electronics Magazine un article célèbre dans lequel il postule une augmentation exponentielle du nombre de transistors dans les microprocesseurs tous les deux ans environ. Lorsqu’il postule cette conjecture [2], Moore ne se base que sur 5 observations étalées de 1959 à 1965 (comme l’on peut l’observer sur la gure 1.1 de l’article d’origine)Cependant de façon remarquable, cette conjecture a continué de se vérier jusqu’à nos jours, montrant certes un écart à la loi postulée originellement par Moore (le doublement de la densité de transistors se faisant entre 1.3 et 1.8 ans), mais témoignant cependant de la justesse de son intuition (cf. gure 1.2).
Naissance de l’idée d’un ordinateur quantique
La conjecture de Moore porte en elle-même une limitation intrinsèque, puisque l’on ne peut envisager de dépasser une valeur de densité limite, qui correspondrait alors à la limite inférieure que l’on est capable d’atteindre en terme de miniaturisation des transistors (de l’ordre de la dizaine d’atomes). Il s’est donc rapidement avéré indispensable de rééchir à d’autres ressources que la miniaturisation pour améliorer la puissance des microprocesseurs. En 1982, Richard Feynman constatant à quel point il est complexe de simuler des systèmes quantiques sur des ordinateurs classiques, est le tout premier à proposer de construire des ordinateurs quantiques qui seraient capables de tirer parti de ce qu’ore la mécanique quantique comme ressources (superposition d’états, interférence, intrication, etc.). C’est à la même époque que David Benio propose au contraire d’utiliser ces ressources pour obtenir une accélération exponentielle des calculs classiques. De tels exemples d’accélération du calcul quantique sur le calcul classique existent, le plus célèbre étant celui de l’algorithme de Shor [3]. Ce dernier permet de factoriser un entier N en O (log(N) 3 ) opérations, alors qu’aujourd’hui le meilleur algorithme classique ne sait faire mieux qu’en un nombre O(e P 1/3 log(P) 2/3 ) d’opérations, où P = log(N) (c’est à dire en un nombre exponentiel d’opérations par rapport à la taille du système). Même si aujourd’hui les applications pratiques restent modestes (on ne sait encore factoriser que de petits nombres), la crainte qu’un ordinateur quantique soit au moins par la théorie capable de déchirer des messages cryptés par la méthode RSA en un temps polynomial, a provoqué l’intérêt de nombreux acteurs (gouvernementaux notamment), et entraîné dans son sillage un développement inespéré de tout le domaine de l’information quantique. D’autres exemples d’accélération existent : l’algorithme de Grover par exemple [4], est capable de retrouver un élément parmi N, en un nombre √ N d’opérations alors que le meilleur algorithme classique ne sait faire mieux qu’en un nombre N d’opérations. On peut également citer le problème de Simon [5] dans lequel on cherche pour une fonction f : {0, 1} m → {0, 1} m , à trouver s tel que ∀x ̸= y : f(x) = f(y) ⇔ y = x ⊕ s, et pour lequel on obtient une accélération d’un nombre exponentiel d’opérations (pour le meilleur algorithme classique connu), à un nombre polynomial d’opérations (pour l’algorithme quantique). Enn on peut citer les travaux récents de Lloyd, Harrow et Hassidim [6], sur la résolution de systèmes d’équations linéaires, où l’on observe pour N équations une accélération d’un nombre O(N) d’opérations pour le meilleur algorithme classique connu, à un nombre poly(log(N)). Nous le voyons donc, utiliser une approche quantique de certains algorithmes classiques, peut conduire à de véritables accélérations salvatrices, ouvrant au moins dans la théorie, la possibilité de résoudre toute une nouvelle classe de problèmes de complexité inaccessible aux ordinateurs classiques. Cependant, nous restons encore aujourd’hui dans l’ignorance des limitations qui seraient celles d’un ordinateur quantique. Ignorance qui s’ajoute à la diculté de trouver quels algorithmes quantiques sont exponentiellement plus ecaces que leurs homologues classiques.
Naissance du traitement quantique de l’information
L’expérience sensible qu’il a du monde, a conduit l’homme à subdiviser l’univers en des catégories distinctes, et à construire une représentation relativement manichéenne de son environnement existentiel : froid/chaud, lent/rapide, mort/vivant, ouvert/fermé, etc. On peut dire sans trop de crainte, que c’est de cette expérience quotidienne d’un univers où existent des états classiques exclusifs l’un de l’autre qu’est née un jour la logique binaire dans le domaine du traitement de l’information. Cependant, avec le temps, l’homme s’est rendu compte de la diculté qu’il y avait à réduire l’existant à de simples catégories, et que bien souvent, tout était question de points de vue. Ainsi la relativité lui a par exemple révélé que le cadre même dans lequel il existe (l’espace, le temps) n’est en rien absolu, et que l’essence profonde des choses lui est dissimulée. La mécanique quantique quant à elle, lui a enseigné que les constituants élémentaires de la matière (atomes, électrons, photons, etc.) étaient décrits par des fonctions d’onde donnant la probabilité lors d’une mesure de trouver le système dans tel ou tel état quantique, l’obligeant à se détacher de cette intuition classique naturelle qu’il a du monde au travers de ses sens. Cette étrangeté du monde quantique qui choque la connaissance que nous avons du monde, a été particulièrement bien illustrée par l’expérience de pensée de Schrödinger dans laquelle un dispositif dépendant de l’état quantique d’un atome (qui a 50% de chance d’être dans un état A où dans un état B), doit déclencher tout un processus conduisant à la mort d’une pauvre chat innocent, entraînant ce raisonnement absurde que tant qu’aucun observateur n’observe le système, le chat se retrouve dans un état quantique de superposition cohérente : √ 1 2 (|mort⟩ + |vivant⟩) (cf. gure 1.3). Bien évidemment l’expérience quotidienne nous prouve que les objets macroscopiques n’exis tent pas dans de tels états de superposition quantique (en raison de phénomènes de décohérence (d’autant plus rapides que le système est important) qui entraînent la disparition quasiimmédiate des cohérences de la matrice densité du système macroscopique et ne laissent subsister qu’une distribution de probabilités délocalisée). De ce constat qu’un objet quantique peut exister dans une superposition cohérente d’états qui seraient classiquement exclusifs les uns des autres, nous pouvons dire qu’est née un jour l’idée d’un traitement quantique de l’information.
Avant-propos |