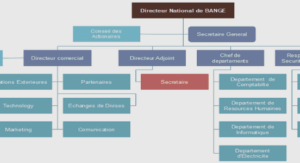
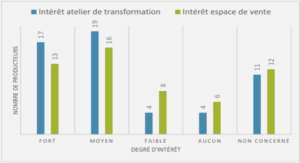
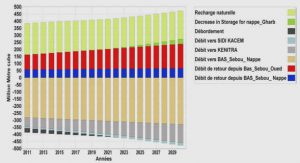
Cours apprentissage ontologique techniques et approches, tutoriel & guide de travaux pratiques en pdf.
Un Processus d’apprentissage consensuel
D’un point de vue l’ensemble des méthodes énoncées par [RIN04], on peut distinguer six étapes suivantes dans un processus d’apprentissage d’ontologies à partir de textes (qui sont d’une certaine façon ou d’une autre, commun à la plupart des méthodes publiées) :
Collection, sélection et prétraitement d’un corpus (textes) approprié (outils TAL).
Découvrez les ensemble des mots (candidats-termes) et expressions équivalentes.
Validation de l’ensemble (établir des concepts) avec l’aide d’un expert du domaine.
Découvrir des ensembles de relations sémantiques en concepts.
Validation des relations et extension des définitions des concepts à l’aide d’un expert du domaine.
Créer une représentation formelle.
Il ne faut pas croire, que seulement les termes, les concepts et les relations entres eux qui sont importantes, mais aussi le sens des « gloss » et la formalisation (axiomes) des concepts ou des relations. Comment mener à bien ces étapes ? Une multitude de réponses peuvent être données. De nombreuses méthodes nécessitent l’intervention humaine avant que le déroulement réel du processus (étiquetage des candidats-termes – apprentissage supervisé, compilation/adaptation d’un dictionnaire sémantique ou des règles de grammaire d’un domaine,…) [RIN04].
Les méthodes non supervisées n’ont pas besoin d’étape préliminaire – cependant, ils ne donnent pas d’assez bon résultats, et le corpus peut empêcher l’utilisation de certaines techniques : par exemple, méthodes d’apprentissage automatique nécessitent un corpus suffisamment large – donc, certains auteurs utilisent l’Internet comme une source supplémentaire. Certaines méthodes nécessitent un prétraitement d’un corpus (par exemple, l’ajout de balises ou étiquette de position, l’identification de la terminaison d’une phrase, …) indépendant de la langue. Encore une fois, il existe diverses manières d’exécuter ces tâches.
Ainsi, de nombreux outils d’ingénierie linguistique ne peuvent être misent en faveur.
Méthodes d’extraction des termes (lexicaux)
Extraction des futurs concepts
L’extraction des termes (futur concept) est une opération pré-requise pour tout apprentissage d’ontologie à partir des textes. Elle implique des niveaux avancés de traitements linguistiques. Les concepts ne sont en général qu’un ensemble de termes. Les termes sont des mots ou suite de mots susceptible d’être retenus comme des entrées (terme, concept) dans une ontologie. Tous les nouveaux travaux convergent vers l’extraction de cette entité. On distingue les méthodes linguistiques basées sur des règles syntaxiques, les méthodes statistiques basées sur les fréquences de séquences et les méthodes hybrides.
Plusieurs modèles sont issues de ces 3 approches. Par exemple la méthode du dictionnaire qui s’appuie sur une ressource externe qui retienne les mots et expressions figées voir semi-figées susceptibles d’être rencontrées dans un texte du domaine, ils sont les plus utilisées dans l’identification des concepts. La méthode des cooccurrences permet de créer un lexique par la répétition des formes présentes dans un texte. La méthode des segments répétés se base sur la détection de chaînes constituées de fraction fréquentes dans le même texte. La méthode des bornes travaille avec des délimiteurs. [TUR01]
Outils d’extraction
Les méthodes n’agissent pas directement sur les corpus bruts (textes) mais utilisent un « shallow text processing » basé sur des études de traitement des textes peu profonde (TAL), et d’analyses syntaxiques ou tout autres traitement fournissant une sortie normalisée et exploitable par des algorithmes d’apprentissage automatiques. Ces outils empruntés au TAL, sont conçus avec plusieurs éléments chacun d’eux est dédié à une tâche bien précise :
Tockenizer : Extrait toutes les unités lexicales d’une phrase ou d’un texte.
Lemmatiseur : PoS tagger pour identifier la classe d’une unité : Nom, Verbe,…
Name Entity : Reconnaisseur d’entité et décider si l’entité est une personne, un matériel, une date, un horaire, un nom de société, etc.
Méthodes statistiques
Une méthode très répandu dans la recherche d’information (IR) est le calcul de la fréquence d’occurrence d’un terme dans un corpus ou dans un texte. Mais très vite, d’autres techniques émergent et prouvent leurs efficacités, comme la méthode issue de la recherche d’information et basée sur la mesure Tfidf « Frequency Term Inverted Document Frequency». [MAE03] :
– Term Frequency Tf (t, d): fréquence d’occurrence du terme « t » dans le document « d » Î D (corpus, ensemble de document).
– Documents frequency df (t) : le nombre des documents dans le corpus D dans lesquels apparaît le terme.
– Inverse Documents frequency idf(t) : idf(t) = log (|D| / df(t)), où |D| : le nombre total de documents dans un corpus D. Un mot qui apparaît dans un peu de documents possède une grande valeur au calcul de la mesure idf(t), à l’inverse de celle qui a une valeur haute de tf*idf est reconnue comme un terme candidat et pertinent pour le document. Alors tfidf du terme t pour un document d est :
– tfidf (t,d) = tf(t,d) * log (|D| / df(t)).
– Corpus Frequency cf(t) : est le nombre d’occurrence du terme « t » dans tous les documents du corpus D. C’est clair que df(t) ≤ cf(t) et Σ tf(t,d) = cf(t).
Méthodes à base de dictionnaires (notre axe de recherche)
Il existe des approches qui préfèrent des ressources issues des dictionnaires comme un outil d’amorce pour repérer les termes pertinents ou acquérir directement des termes contenus dans ces dictionnaires qui constituent une mine très riche d’information lexicale et sémantique (au cas où ils existent). Il offre une stabilité pour un bon amorçage du processus d’extraction.
Un souci majeur pour une exploitation facile se situe dans leur transformation en des représentations facilement exploitable par des machines. Kiez, dans [KIE00], a présenté des travaux pour la construction d’ontologie de domaine (assurance) ainsi que Maedche et Staab dans [MAE03] pour la télécommunication.
Extraction de relation
Plusieurs ressources lexicales sont utilisées pour relever les relations sémantiques entre les concepts, on cite alors : les dictionnaires, les ontologies (existantes), les patrons syntaxiques, la notion de collocations de termes ou bien la combinaison de toutes ces ressources.
A titre d’exemple, dans les partons lexico-syntaxiques (hérités du TAL), on trouve les relations sujet-verbes, verbes-objet, ou le groupement des termes selon leurs cooccurrences avec le verbe qui permettra d’acquérir par la suite des relations sémantiques.
Relations taxonomiques
Deux grandes approches émergent dans l’apprentissage ou l’acquisition des taxonomies [MAE03] :
– Approches moyennant le clustering : Basé sur les hypothèses distributionnelles, ce sont des approches statistiques (groupement des termes et calcul de similarité,…).
– Approches utilisant les patrons lexico-syntaxiques : se sont des approches symboliques pour détecter les relations d’hyponymie proposé dans [HEA92].
® Clustering et les relations
Dans la famille des méthodes de regroupement non supervisées, on distingue les méthodes agglomératives (plus proche voisin, distance maximum…) qui regroupent des clusters existants selon des mesures de similarité et des méthodes de divisions (bisection kmeans).
[CIM04-b] expose un aperçu de plusieurs approches : Il commence avec les premiers travaux liés au clustering, citant tout d’abord les travaux de Hindle [HIN90], où les noms sont regroupés selon leurs apparitions comme sujets ou objet de verbes similaires. Quand à Pereira [PER93], il présente une approche du « Top-down clustering » pour bâtir une taxonomie non étiquetée de noms (Les relations de la taxonomie non étiquetée). Par contre l’approche ittérative « bottom up of clustering » a été présenté dans [FAU98], privilégiant ainsi la fréquence des mots apparaissant dans un même contexte. Cette méthode nécessite un suivi manuelle (méthode supervisée), par conséquent elle est n’est pas privilégiée par rapport aux méthodes (semi) automatiques. Dans [BIS00], Bisson et al, fournit un outil complet assistant le concepteur dans le domaine de construction d’ontologie, en utilisant une comparaison des distances de similarités (distances sémantiques) afin d’arriver à un clustering « bottom up ». Des études assez récente dans [CIM04-a], Viz utilise une FCA (Formal Concept Analysis), analyse des concepts formelle pour grouper les concepts et d’en extraire une hiérarchie à partir des textes.
® Patrons lexico-syntaxiques et les relations
Les patrons lexico-syntaxiques fournissent une relation entre des concepts d’un domaine. Ces relations ne sont repérées que lorsque les concepts appartiennent à la même phrase. Deux axes supplémentaires se sont développés :
– Dans la littérature linguistique, des patrons relatifs aux relations hiérarchiques (hyperonymie, définition, méronymie – partie de –) ou de synonymie, ont été capitalisés avec l’espoir de pouvoir les réutiliser sur tout type de textes. L’état de l’art montre que ces patrons sont plus ou moins adéquats et doivent toujours être ajustés.
– Dans les recherches de l’extraction d’information, de nouveaux patrons sont redéfinis pour repérer des relations spécifiques au domaine étudié.
En 1992, Hearst a proposé une approche pour extraire des relations d’hyponymies à partir d’une encyclopédie scolaire « Grolier », cette méthode utilise des patrons lexicosyntaxiques manuellement capturés à partir d’un corpus. [CHA99] donne une approche pour apprendre la relation « Part of », mais ceux [VEL01] manipule des techniques heuristiques.
[MOR98] développe Prométhée pour palier à la lourdeur de la méthode Hearst (confection manuelle des patrons). C’est un outil d’apprentissage automatique pour l’extraction des patrons lexico-syntaxiques relatifs à la spécification conceptuelle des relations.
Conclusion
Dans ce chapitre, nous avons fait un passage horizontal sur les différentes techniques, approches et outils de base utilisées dans la création d’une ontologie, en générale.
Le point de rencontre commun à tous les systèmes étudiés est la réutilisabilité et le partage de l’ontologie.
L’extraction de connaissances ou communément parlant « apprentissage d’ontologies » a pour but la construction semi-automatique d’ontologie. Les méthodes de construction d’ontologies à partir des documents semi structuré favorisent souvent l’étude du texte, proprement dit, que ce soit selon une approche statistique, symbolique ou linguistique.
Le dernier chapitre va surtout mettre en lumière l’approche de la solution adoptée à la construction d’une ontologie lexicale en prenons l’ontologie WorNet comme modèle de travail, et en utilisant comme source d’entrée pour l’apprentissage, les données d’un dictionnaire arabe « Al ghannye ».