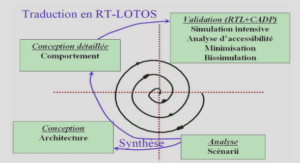
Apprendre la forme de l’objet : La voie What
Extraction des caractéristiques visuelles
La rétine est composée de trois couches : arrière, intermédiaire et avant. La première couche est constituée des cellules photoréceptrices : les cônes qui réagissent à l’ensemble du spectre lumineux et les bâtonnets qui sont sensibles aux couleurs. La couche intermédiaire est constituée de cellules bipolaires, horizontales et amacrines. Finalement, la couche avant est constituée de cellules ganglionnaires.
Ces dernières reçoivent le signal des cellules de la couche intermédiaire et véhiculent leur signal à travers leurs axones qui forment ensemble le point aveugle et le nerf optique. Les cellules ganglionnaires proches de l’axe optique, constituent la fovéa. Elles possèdent des champs récepteurs plus petits que ceux des cellules situées en périphérie. Les cellules ganglionnaires possèdent des champs récepteurs de deux sortes, des cellules « on-center » et des cellules « off-center ». Un stimulus lumineux augmente l’excitation (activité) des cellules « on-centre » et diminue celle des cellules « off-center ». Ces champs récepteurs sont-
De la rétine au cortex visuel primaire
L’information passe de la rétine à l’aire visuelle V1 à travers le chiasma optique et le corps genouillé latéral. souvent modélisés par des différences de gaussiennes ( DOG ) de différentes tailles ce qui leur confère des propriétés d’analyse multi-échelle (Koenderink and van Doorn [1987]). Nous trai tons les informations visuelles dans le cadre de cette thèse en utilisant une seule taille de DOG
Larépartition des photorécepteurs et la forme des récepteurs ganglionnaires, fait que la rétine perçoit les hautes fréquences uniquement sur la fovéa, alors que les basses fréquences ne sont discernées qu’en périphérie. Cette disposition impose une exploration du champ visuel par des mouvements oculaires. Ces mouvements sont contrôlés par le colliculus supérieur, qui permet notamment de coordonner les mouvements oculaires et ceux de la tête.
Le nerf optique se projette, via le chiasma optique, dans le thalamus. Le chiasma optique transporte les informations visuelles venant de l’œil droit sur l’axe gauche et inversement. L’in formation passe ensuite par le corps genouillé latéral (CGL) qui relais l’information aux cellules du cortex visuel. Le CGL est constitué de six couches de cellules, possédants des champs récep teurs « on-center » et « off-center » à la manière des cellules ganglionnaires.
Le CGL est connecté au cortex strié (appelé aire visuelle V1). Les champs récepteurs de l’aire visuelle V1 sont de type « on » et « off » différents de ceux du CGL. Ces cellules ont des formes allongées avec différents taux de recouvrement et permettent une décomposition du signal visuel (Buhmann et al. [1990]). Deux types de cellules sont identifiées par Hubel and Wiesel [1968]. Les cellules simples qui sont sensibles à la position et à l’orientation du stimulus.
Elles sont simulées par un banc de f iltre Gabor. Les cellules complexes qui ont des champs récepteurs plus larges et présentant de forts effets non-linéaires dans leurs réponses au stimuli visuels. L’information est rétinotopique au niveau de V1. On utilise une transformation log-polaire pour la modéliser (Schwartz [1980]). Cette transformation privilégie les zones centrales de l’image. Le système visuel de nos robots s’inspire des aires visuelles (V1 et V2).
La figure 4.3 montre le résultat de l’extraction des vues locales sur une image. L’extraction des caractéristiques vi suelles se fait en trois étapes. En premier, le système cherche le point de focalisation le plus saillant. Ensuite, une vue locale est extraite autour de ce point de focalisation. Cette vue locale subit une transformation log/polaire.
Puis, elle est catégorisée. Finalement, un système de WTA inhibe ce point de focalisation et le système cherche le prochain point et la chaîne recommence. Tout d’abord, le gradient de l’image d’entrée, convertie en niveaux de gris, est calculée grâce à une convolution entre cette image et un filtre exponentiel 4.3(b). Ensuite un produit de convolution est effectué eq.4.2 entre l’image de gradient et une différence de gaussienne (DOG)-
La différence de gaussienne (DoG) simule une cellule centre-off. Les maximas locaux du f iltre DoG permettent au robot de concentrer son attention sur les coins, les extrémités de lignes ainsi que les petites régions à fort contraste dans l’image. Le résultat de ce produit (fig.4.3(c)) est une image où les coins ont une intensité supérieure aux régions avec des lignes droites. Un mécanisme de WTA associé à un système d’inhibition contrôle l’exploration séquen tielle de la scène visuelle.
Ces points de focalisation sont les centres des vues locales délimitées par des cercles dessinés sur l’image d’entrée. La taille des cercles détermine le champ de vi sion du robot. Les saccades oculaires sont simulées pour pallier les limitations mécaniques des moteurs. L’acquisition d’une nouvelle tête robotique (Robot Tino) au laboratoire dotée de mo teurs ultra-rapides permettra à terme d’effectuer une recherche séquentielle réelle de la scène.
Une transformation log/polaire des vues locales est appliquée pour mimer les projections sur la rétine des aires visuelles primaires et permettre une robustesse aux faibles rotations et chan gements d’échelle (changement de distance et d’orientation de l’objet en face de la caméra).
La caractéristique la plus importante de la transformation en log/polaire couplée à une explora tion séquentielle de l’image est de fournir un moyen de limiter le champ du robot à une petite zone de l’image lui permettant ainsi d’extraire des caractéristiques qui peuvent être catégorisées facilement par la suite