Cours Apache Cassandra la base de donne de la famille NoSQL, tutoriel & guide de travaux pratiques en pdf.
ARCHITECTURE
LES CONCEPTS
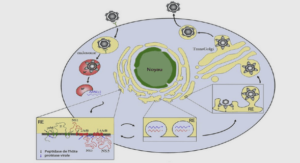
Apache Cassandra est un syste me permettant de ge rer une grande quantite de donne es de manie re distribue e. Ces dernie res peuvent e tre structure es, semi-structure es ou pas structure es du tout. Cassandra a e te conçu pour e tre hautement scalable sur un grand nombre de serveurs tout en ne pre sentant pas de Single Point Of Failure (SPOF). Cassandra fournit un sche ma de donne es dynamique afin d’offrir un maximum de flexibilite et de performance. Mais pour bien comprendre cet outil, il faut tout d’abord bien assimiler le vocabulaire de base.
Cluster : un cluster est un regroupement des nœuds qui se communiquent pour la gestion de donnees.
Keyspace : c’est l’e quivalent d’une database dans le monde des bases de donne es relationnelles. A noter qu’il est possible d’avoir plusieurs « Keyspaces » sur un me me serveur.
Colonne (Column) : une colonne est compose e d’un nom, d’une valeur et d’un timestamp.
Ligne (Row) : les colonnes sont regroupe es en Rows. Une Row est repre sente e par une cle et une valeur. Il existe deux types de rows : les « wide» et les « skinny» pour le stockage des donnees.
Une famille de colonnes (Column family) : c’est l’objet principal de donne es et peut e tre assimile a une table dans le monde des bases de donne es relationnelles. Toutes les rows sont regroupe es dans les column family.
PARTITION DES DONNEES
Il est possible de configurer le partitionnement pour une famille de colonnes en pre cisant que l’on veut que cela soit ge re avec une strate gie de type Ordered Partitioners. Ce mode peut, en effet, avoir un inte re t si l’on souhaite re cupe rer une plage de lignes comprises entre deux valeurs (chose qui n’est pas possible si le hash MD5 des cle s des lignes est utilise ).
Cependant, il est conseille d’utiliser plutot une deuxieme cle d’indexation positionne e sur la colonne contenant les informations voulues. En effet, utiliser la strate gie Ordered Partitionners a les consequences suivantes : l’ecriture sequentielle peut entraî ner des hotspots : si l’application tente d’ecrire ou de mettre a jour un ensemble se quentiel de lignes, alors l’ecriture ne sera pas distribue e dans le cluster ; un overhead accru pour l’administration du load balancer dans le cluster : les administrateurs doivent calculer manuellement les plages de jetons afin de les repartir dans le cluster ; repartition inegale de charge pour des familles de colonnes multiples.
…….