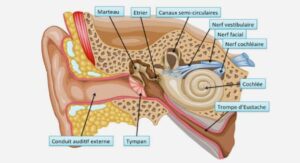
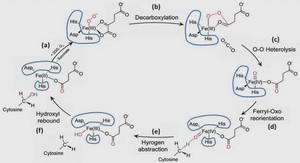
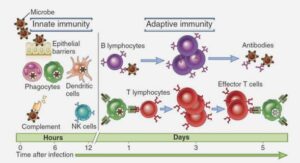
Apports méthodologiques
Amélioration de l’estimation du mérite génétique et prise en compte, en détection de QTL des caractères à seuils
La détection de QTL par l’analyse de liaison est aujourd’hui une technique largement documentée dans la littérature (Soller et Genizi, 1978 ; Lander et Botstein, 1989 ; Weller et al., 1990). Le principe et les modèles statistiques utilisés sont décrits dans le chapitre I. Elle consiste à observer, intra-famille de père (ou mère, génération G1), si les performances des descendants (génération G2) sont significativement différentes entre groupes définis par la combinaison allélique reçue du père aux marqueurs informatifs flanquant la position testée. Dans l’approche par régression (Haley et Knott, 1992), les performances des descendants sont régressées par les probabilités de transmission des allèles parentales au QTL sachant les informations aux marqueurs flanquants. Avec ce même modèle, il est possible de regrouper le mérite génétique des descendants, calculé à partir des performances mesurées sur les petits-descendants (G3), à la place de leurs performances propres si celles-ci ne sont pas mesurables. Cette modélisation correspond au protocole « petites-filles » (Weller et al., 1990). L’intérêt de ce protocole est multiple. Il permet notamment d’augmenter la puissance de détection de QTL (paragraphe 3.3 du chapitre I). Tribout et al. (2008) ont étendu ce dispositif au cas où les descendants possèdent des performances propres.
Dans le calcul du mérite génétique des descendants génotypés, il peut être envisagé de prendre en compte, en plus de leurs performances et celles des petits- descendants, les performances des générations suivantes (G4, G5,…), quand elles sont disponibles. Nous proposons, dans un article accepté par Journal of Animal Breeding and Genetics, une méthode permettant de prendre en compte ces « nouvelles » performances dans la détection de QTL. Cette méthode renforce la puissance des dispositifs de détection de QTL. Cela est particulièrement vrai pour les protocoles où les effectifs par familles sont réduits, comme c’est souvent le cas en génétique humaine ou pour des espèces où l’insémination artificielle n’est pas totalement maitrisée. Toutefois, les intervalles entre générations doivent être suffisamment courts pour que la mise en place d’un tel dispositif soit pratique. Nous montrons comment obtenir la meilleure combinaison linéaire de performances de la descendance (G2, G3, …) qu’il convient d’analyser dans un modèle de régression de type Haley/Knott comme « performance » étendue des individus de la deuxième génération (G2) génotypés. Nous analysons les relations entre ces combinaisons linéaires et l’estimation BLUP des valeurs génétiques de ces individus G2. La méthode décrite dans l’article permet donc d’étendre celle proposée par Weller et al. (1990), puis repris par Tribout et al. (2008) à un nombre quelconque de générations. L’article présente comment obtenir « le mérite génétique dé-régressé » et le coefficient de détermination associé, pour chacun des individus de la deuxième génération génotypée. Des extensions pour les mesures répétées et la prise en compte des effets fixes dans le modèle sont proposées.
L’apport de nouvelles mesures phénotypiques permettra d’améliorer la puissance de détection. Toutefois, lorsque les tailles des familles sont suffisamment larges (comme chez les bovins laitiers, par exemple) pour garantir un bon niveau d’estimation du mérite génétique pour les individus marqués, l’intérêt peut être limité. Un certain nombre d’améliorations peuvent être apportées aux développements proposés. Notamment, dans nos développements algébriques, nous considérons que les individus de la première génération sont indépendants, hypothèse assez répandue en détection de QTL par analyse de liaison, ce qui peut ne pas correspondre à la réalité. La prise en compte d’éventuels liens de parenté entre les pères fondateurs peut être une des améliorations à apporter à ce modèle. Comme il est dit ci-dessus (paragraphe 3, chapitre I), certains caractères d’intérêt économique ou biologique pour la production animale ont une distribution discrète, et donc non gaussienne. Comme les caractères continus, ces caractères discrets présentent en général un déterminisme complexe et leur variabilité est contrôlée par de nombreux gènes. Une hypothèse fréquente est que la variabilité de ce type de caractère (disons Y) est sous l’influence d’une variable gaussienne sous- jacente (disons Z), dont l’échelle est jalonnée de seuils (s1, s2, …, sn) : quand Z est dans l’intervalle [si, si+1], la variable Y vaut i+1 : on parle de caractères à seuils (Falconer, 1958). Le premier à aborder le modèle à seuil en génétique fut Wright (1934). Depuis, plusieurs auteurs ont analysé des caractères de ce type, le plus souvent dans le cadre polygénique classique, i.e. sans prendre en compte l’information moléculaire, pour estimer des paramètres génétiques tels que l’héritabilité, ou des effets de facteurs connus tels que le sexe de l’animal (Fouley et al., 1983 ; Gianola et Foulley, 1983 ; Harville et Mee, 1984 ; Weller et al., 1988 ; Weller et Gianola, 1989 ; Jamrozik et al., 1991 ; Weller et Ron, 1992 ; Weller et al., 1992). D’autres auteurs (Hackett et Weller, 1995 ; Xu et Atchley, 1996) intègrent, dans leurs études sur les caractères à seuils, l’information moléculaire, dans le but de cartographier des QTLs. Leurs méthodes sont développées pour des populations « inbred ». Elles ont été étendues pour des dispositifs « outbred » par Yi et Xu (1999). Plus récemment, Xu et al. (2005) ont proposé une méthode multi-caractères de détection de QTL pour les caractères binaires. Tous ces auteurs considèrent une distribution normale sous-jacente à la distribution réelle de la variable discontinue étudiée.