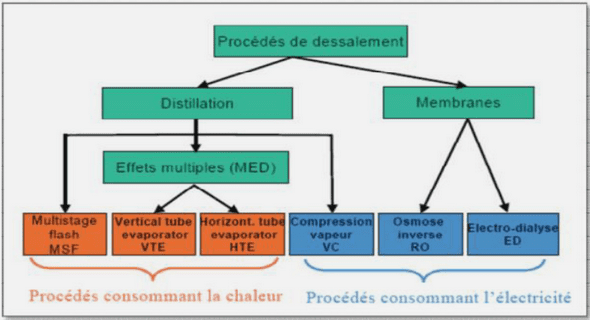
Active appearance and shape models for tracking
One of the problems with EdgeTrak is that it possibly fails when some parts of the tongue from previous frames are not visible in a rapid tongue tracking task. In such cases, error can propagate and tracking cannot usually recover from that. Although preprocessing the US frames and applying boundary constraints on the snake can help the moving contour keep its size (Aron et al. (2008)), the constrained snake still needs manual refinements. To address this, Roussos et al. (2009) proposed a different tracking approach and that is to train a model with prior information about the shape variations of the tongue contour and its appearance in US images, known as active appearance models (AAMs). In this method, two models, one for shape variation of the tongue (obtained using annotated X-ray videos of the speaker’s head) and one for texture model (based on the US image intensities around the tongue contour), are trained.
Besides active appearance models, active shape models (ASM) also can be used along with snakes for segmentation of structures such as the tongue. Hamarneh & Gustavsson (2000) proposed a method that combines ASM and snakes for segmenting the human left ventricle in cardiac US images. This is achieved by obtaining a shape variation model that is trained by averaging ventricle shapes and then the salient contours of ventricles are found by letting a snake that deforms to find the boundaries. This approach was successfully applied to tongue tracking by Ghrenassia et al. (2013).
Pairwise registration / optical-flow
Tracking the tongue contour is the same as retrieving motion under rotation and distortion conditions. Therefore, one of the simplest methods to address the problem of segmentation/- tracking is to estimate motion via a gradient based approach. Chien et al. (2017) present an approach to track tongue motion in ultrasound images for obstructive sleep apnea using an optical flow (OF) method by Lucas & Kanade (1984).
Chien et al. (2017) also suggest the strategy of iterative motion estimation, where an initial motion vector at the coarsest spatial scale is computed first and then those regions of interest are moved using that initial motion vector and after that another optical flow is calculated at a finer scale, and this is repeated until completion of all desired resolutions. Moving the ROI’s at a coarser scale accelerates convergence in general and when a finer scale OF is applied the results are more accurate. Although this method is technically simple, it has two major limitations for the task of tracking a tongue contour motion. The first limitation is the heavy computations that need to be done per frame that make this approach very slow in comparison with other dynamic methods . Moreover, the errors in the method accumulate from one frame to the next.
Machine learning methods
Recent and very rapid developments in machine learning methods in the last decade have led to their equally rapid and successful application to image analysis tasks using deep neural networks. US tongue image analysis is no exception. Neural networks can work well if there are enough data they can learn from; which, in our problem, translates to having a database of segmented US images of tongue contours. There have been some works in the recent years that exploited the possibility of using deep neural networks to trace the tongue contour in US images .
Fasel & Berry (2010) presented a method based on deep belief networks (DBN) to extract tongue contours from US without any human supervision. Their approach works in a number of stages. First, a deep convolutional neural network is built and trained on concatenated sensor and label input vectors (US images and manually segmented contours). Second, the first layer of this network is modified to accept only sensor inputs (no contour information anymore). The second neural network can establish the relationship between the first neural network and the sensor-only (US) images so that the whole system can infer the labels (tongue segmentation). To minimize the reconstruction error of labels, the network is fined-tuned using a discriminative algorithm. The work by Fasel & Berry (2010) has resulted in a publicly available software called Autotrace.
The approach by Fasel & Berry (2010) makes a complex neural network model based on the tongue segmentations, which require the intensity of all pixels in the US images plus their contour segmentations as inputs. As this approach frames the tongue contour segmentation goal as a typical deep learning problem, it needs a large amount of training data to fine tune weights of 5514 neurons dispatched on 3 hidden layers. Fabre et al. proposed a similar methodology in line with the work presented by Fasel & Berry (2010) but with a simpler neural network. In their approach, they take advantage of a PCA-based decomposition technique called “EigenTongues” which is a compact representation of raw pixels intensities of tongue US images (explained originally in Hueber et al. (2007)), and they also present a PCA-based model of the tongue contours which they call “EigenContours” along with a neural network that establishes a relationship between the two compact representations of the US image data and the segmented contour pixels. This method provides a simpler model than Autotrace, suggesting that fewer training data are needed for segmentation.
INTRODUCTION |