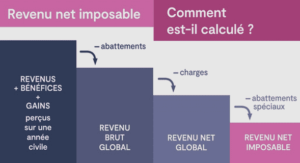
Information contenue dans une vue
Les méthodes de vision active consiste à déplacer un capteur en vue d’améliorer un critère lié à une tâche haut niveau. Cette tâche peut être une tâche de reconstruction. Le critère à minimiser est alors souvent l’incertitude sur un ensemble de paramètres. Il peut également s’agir d’une tâche d’exploration ou encore d’une tout autre tâche robotique.
Dans le cadre de cette étude, la tâche à mener à bien est la caractérisation d’un objet en vue de sa saisie, c’est-à-dire estimer sa position, son orientation et ses dimensions.
Incertitude sur les paramètres
Les paramètres de la quadrique correspondant à la surface de l’objet sont estimés en utilisant un processus des moindres carrés itératif. À partir des résultats de cette optimisation numérique, il est possible d’évaluer l’incertitude sur l’estimation des paramètres de la quadrique. Au voisinage de l’optimum, la fonction de coût est approximée par une forme quadratique. Une fois qu’un minimum acceptable de la fonction de coût χ (q) a été trouvé pour un jeu de paramètres qmin, la variation de χ 2 autour de ce minimum pour une variation δq des paramètres ajustés qmin est donnée par :
Critère de sélection de la vue suivante
Intuitivement, on pressent qu’un choix judicieux des vues peut améliorer les paramètres qui présentent une grande incertitude. La question est de trouver un critère objectif qui permette de quantier l’information contenue dans une vue. Ce critère peut être basé sur la théorie de l’information développée par Shannon, comme le propose [Whaite 97b]. L’information contenue dans une vue dépend de la valeur du déterminant de la matrice de covariance et [Whaite 97b] montre que maximiser l’information contenue dans une vue revient à minimiser le déterminant de la matrice de covariance.
Ainsi, la clé pour communiquer l’incertitude associée à une vue au système haut niveau qui gère les déplacements de la caméra est la nature de la surface chi-carré de l’incertitude dans l’espace des paramètres [Whaite 91]. L’incertitude peut être communiquée via la matrice de covariance C = σ 2G−1 . Elle est immédiatement trouvée en évaluant la matrice de Gauss G−1 à convergence du processus d’optimisation numérique qui permet d’estimer les paramètres de la quadrique (voir la section 7.3). Dans le cadre d’un processus itératif de calcul des paramètres, il est intéressant d’établir la relation entre la valeur de la covariance de la vue suivante et la valeur courante de la covariance. Ainsi, elle pourra être calculée incrémentalement et ecacement à chaque pas.
Cette matrice ne dépend que des positions occupées par la caméra au cours de la reconstruction et des paramètres estimés qmin. Elle peut être interprétée, géométriquement, comme le volume de l’ellipsoïde de conance dans l’espace des paramètres qui vaut det C. Pour réduire l’erreur sur les paramètres, il faut trouver la vue qui minimise le volume de l’incertitude det C. En notant Cj la matrice de covariance de la jème vue et sachant que Cj = G−1 j , quelle doit être la prochaine pose de la caméra pour que det Cj+1 soit minimale ? Répondre à cette question revient à chercher la vue qui donne le det Gj+1 maximal ? Soit Gj = JC > j JCj où le jacobien est construit par empilement des jacobiens associés à chaque vue JCj = (g1, g2, . . . , gj ) >. Si on parvient à exprimer la matrice de Gauss a priori de la prochaine vue en fonction des paramètres courants et de la matrice de Gauss courante, il est alors possible de chercher la pose qui permet de maximiser le det Gj+1.
Calcul de la position suivante
L’approximation quadratique de la fonction de coût, sur laquelle repose le calcul de la covariance et le critère de sélection de la vue suivante, n’est vraie que localement autour de la position courante.
Ainsi, la meilleure vue suivante est la vue qui permet de maximiser le critère det(I + gj+1Gj −1 g > j+1) au voisinage de la vue courante [Whaite 97b].
Une fois la meilleure vue calculée au voisinage de la vue courante, la caméra est déplacée dans la direction de cette vue tout en étant maintenue sur la sphère de vision. En d’autres termes, la caméra suit le gradient numérique de det(I + gj+1Gj −1 g > j+1). Une fois la caméra positionnée, le processus.
Les démonstrations de ces propriétés sont données dans l’annexe D d’estimation des paramètres est à nouveau lancé et les paramètres estimés sont mis à jours permettant à nouveau de choisir la meilleure vue suivante.
Pour éviter de tomber dans des minima locaux qui amènent naturellement la caméra à s’approcher de l’objet, les vues sont acquises sur une sphère de vision centrée sur le centre de la quadrique courante et ayant pour rayon la distance séparant la position courante de la caméra et de l’objet.
Seule la composante de translation est calculée, l’orientation sera ajustée pour que le centre de l’objet soit toujours centré dans la vue. Ainsi, le critère calculé ne dépend que de la position de la caméra et de l’estimation courante des paramètres de l’objet. Le problème revient donc à calculer le gradient de det(I + gj+1Gj −1 g > j+1) relatif à la position de la caméra sous la contrainte de rester au voisinage de la position courante et sur une sphère de vision centrée sur l’objet.
Pour résoudre ce problème d’optimisation, nous avons choisi d’utiliser une méthode d’optimisation numérique non linéaire qui ne nécessite pas d’estimation du Jacobien. La méthode considérée est celle du Simplexe de Nelder et Mead [Nelder 65]2 . Dans un espace de m paramètres, cette méthode consiste à évaluer le poids de la fonction de coût en m+1 points particuliers, qui sont les sommets du simplexe, qui est un triangle généralisé dans un espace à m dimensions. Selon la valeur du coût évaluée en ces points, de nouveaux points sont calculés en prenant en compte des considérations géométriques sur la forme du simplexe multidimensionnel. L’algorithme est décrit dans l’encadré 9.1.
Pour reconstruire l’objet au mieux, le déplacement attendu est une rotation autour de l’axe principal de l’objet. Cependant comme la direction de l’axe principal est évaluée à chaque ajout de caméra le parcours obtenu n’est pas parfaitement circulaire.
Résultats Expérimentaux
Cette section présente les résultats de reconstruction obtenus à partir de données réelles et les améliorations apportées par la vision active en terme de reconstruction et de nombre de vues nécessaires.
La gure 9.6 présente les résultats de reconstruction obtenus pour quatre objets sur des arrière plans quelconques.
L’estimation de la forme des objets par des quadriques donne une information sur l’orientation de l’objet, permet d’aner l’information sur sa position obtenue lors de l’étape de localisation et donne une estimation de ses dimensions. Mieux les vues sont positionnées, meilleure est la reconstruction. La méthode de vision active proposée permet de faire évoluer l’estimation des paramètres de l’objet plus rapidement que lorsque des vues sont choisies de manière arbitraire sur une sphère de vision. La gure 9.2 illustre la valeur a priori de l’entropie pour des positions évaluées sur toute la sphère de vision. On peut remarquer que les valeurs sont réparties de manière symétrique sur la sphère de vision. Le poids de chacune des vues dépend de l’estimation courante de la quadrique et des positions précédemment occupées par la caméra. La symétrie est due aux symétries des quadriques. Il existe deux positions symétrique par rapport au centre de la sphère de vision qui apporteraient des informations identiques. Pour limiter les déplacements de la caméra, c’est la position la plus proche de la position courante qui est choisie comme prochaine meilleure vue. La gure 9.3 présente les déplacement de la caméra et les meilleures vues suivantes calculées.
La gure 9.4 présente l’évolution des paramètres lorsque les vues ajoutées sont sélectionnées de manière arbitraire puis après l’ajout d’une vue sélectionnée par vision active. L’ajout de cette vue bien choisie permet de faire évoluer à nouveau les paramètres. L’ajout ultérieur de vues ne permet plus d’obtenir un meilleur résultat.
Les gures 9.5 et 9.6 présentent les résultats de reconstruction obtenus pour des objets sur fond noir puis sur fond complexe. Dans le cas des fonds complexes, les contours actifs ont été initialisés à la main assez proches des contours réels. Ils sont ensuite suivis dans une séquence de vues.