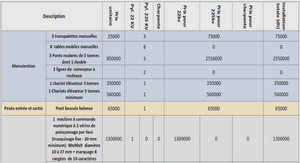
Le texte, l’ordinateur, l’humain
Humanités numériques
On fait habituellement remonter l’émergence des humanités numériques (digital humanities en anglais) au projet d’Index des œuvres de Saint Thomas d’Aquin par R. BUSA (BERRA, 2015; CITTON, 2015). Cherchant à exploiter les apports des technologies numériques aux sciences humaines et sociales, leur définition et leurs frontières sont sujettes à discussion, néanmoins leur préoccupation principale peut être dégagée comme étant celle de l’étude, de la gestion et de la transmission des savoirs et connaissances dans une ère de l’information globalisée et électronique, ou pour le dire très simplement, comment combiner sciences humaines et sociales et technologies informatiques et de l’information. Citons comme définition celle de DACOS (2010) : Les digital humanities désignent une transdiscipline, porteuse des méthodes, des dispositifs et des perspectives heuristiques liés au numérique dans le domaine des Sciences humaines et sociales. En France, ce Manifeste des Digital Humanities fait office de référence dans la définition des humanités numériques et de leurs orientations, en faisant un état des lieux de la situation et en posant les orientations souhaitées pour leur avenir, notamment leur aspect ouvert et collaboratif. Depuis lors, les humanités numériques se sont développées en France et en Europe sous la forme de structures et de plateformes (BERRA et al., 2017), de formations universitaires, de groupes et centres de recherches, de revues… dont DACOS et MOUNIER (2015) proposent un panorama. 56 Chapitre III. État de l’art De la numérisation de parchemins médiévaux à la mise à disposition des savoirs et connaissances pour le grand public, en passant par les pratiques de recherche numériques comme la tenue de carnets de recherches, les multiples facettes des projets en humanités numériques rendent leur illustration concise difficile. Leur développement a amené à nombreux débats sur les rapports entre sciences dites « dures », représentées essentiellement par l’informatique, et les sciences humaines et sociales, avec à la clé la question de la structuration de la collaboration de ces horizons que l’on peut au premier abord croire comme diamétralement opposés. L’enjeu de ces débats est de dépasser une conception des humanités numériques où les ingénieurs et personnels techniques sont envisagés par les porteurs de projet en sciences humaines et sociales comme de simples pourvoyeurs de services informatiques. C’est en cela que les humanités numériques intéressent notre projet de recherche : leur développement ne se réduit pas au développement de solutions techniques mais s’accompagne de la construction d’une théorie des savoirs et des pratiques numériques (GANASCIA, 2015), ce que MOUNIER (2017) souligne comme étant la particularité du monde de la recherche en comparaison des autres métiers ayant également intégré les évolutions technologiques.
Linguistique de corpus & textométrie
La linguistique de corpus est une branche de la linguistique étudiant une langue « réelle », par contraste avec une linguistique pratiquée sur des exemples « artificiels », c’est-à-dire construits expressément à titre d’illustration. Pour étudier cette langue réelle, la linguistique de corpus a recours à des corpus de données orales ou écrites authentiques (ESHKOL-TARAVELLA et LEFEUVRE-HALFTERMEYER, 2017). Si elle existe depuis le milieu du XXème siècle, elle a connu un regain d’intérêt depuis l’émergence de technologies informatiques qui ont permis non seulement la collecte et la mise en forme de grands volumes de données linguistiques, mais aussi leur traitement automatique et systématique (LÉON, 2005 ; POIBEAU, 2014a). De plus, l’explosion des moyens de communication numériques a engendré un volume de productions linguistiques (essentiellement textuelles) que la linguistique de corpus est à même de traiter. En cela, la linguistique de corpus s’est reliée au mouvement des humanités numériques. La linguistique de corpus s’oppose également à une pratique de la linguistique limitée au seuil de la phrase, car elle étudie les textes dans leur ensemble et en prenant en compte leurs structures internes et externes (RASTIER, 2004). Enfin, son ambition, entre autres choses, est d’assurer la validité des observations réalisées par la représentativité statistique des résultats obtenus. La disponibilité de moyens informatiques a permis à la linguistique de corpus de se développer et de renouveler ses problématiques : les principales sont liées à la conception et l’adaptation de méthodes statistiques pour le traitement du texte ou encore aux modalités de constitution de corpus d’étude (questions de collecte des données, de nettoyage, de formatage, de compilation, de mise à disposition de la communauté des chercheurs…).
Quel paradigme textuel pour l’analyse criminelle ?
Les humanités numériques, la linguistique de corpus et la textométrie nous apportent des éléments de réflexion pour préparer l’introduction d’une nouvelle manière d’appréhender les documents textuels en analyse criminelle. Pour reprendre chaque angle de notre triangle outil-sujet-objet : Premier point, l’outil : les moyens informatiques de type bureautique, combinés à l’utilisation d’un logiciel d’analyse de données, apportent une assistance à la pratique de l’analyse criminelle. Néanmoins l’apport de ces moyens n’est pas suffisant pour couvrir l’ensemble des phases de travail. Les outils de linguistique de corpus et de textométrie permettent de faciliter le traitement des documents textuels, d’en obtenir une vue d’ensemble, et de mettre en place des approches qui pourraient s’avérer utiles à la pratique de l’analyse criminelle. Le versant théorique de ces deux disciplines, combiné à celles actuellement développées en humanités numériques apporteraient un cadrage épistémologique de ces nouvelles pratiques. Deuxième point, le sujet : l’analyste est l’acteur de la recherche d’information et de la construction du raisonnement basé sur ces informations. Ce principe d’analyse criminelle correspond à la pratique de la linguistique de corpus selon laquelle le chercheur interprète les résultats produits par les logiciels : les logiciels de linguistique outillée ne fournissent pas une réflexion, et dans la même perspective, le raisonnement, la construction des hypothèses doivent rester le fruit du travail des analystes criminels. Pour outiller l’analyse criminelle, il faudra adapter des techniques et théories à ses objectifs et à la nature du texte traité, ce qui demandera probablement également de former les analystes criminels, tout en gardant en tête que le cœur de métier de l’analyste criminel n’est pas la manipulation de textes : le choix opéré doit rester maniable pour un utilisateur formé mais non-expert. Troisième point, l’objet : l’étude de la nature des documents traités en analyse criminelle nous a conduite à concentrer nos efforts sur les auditions de témoins, qui représentent un sous-ensemble riche en information non-structurée. Nous avons également dégagé l’utilisation des entités comme clés d’entrée dans le texte, un concept que nous décrirons dans la suite de ce chapitre. D’autre part, au-delà des applications en analyse criminelle directement visées par cette recherche, les auditions de 2. « Entités », « entités nommées » et « descriptions définies » 63 témoins constituent un type de texte singulier qui n’a jusqu’à présent fait l’objet que de peu de recherches en français. Le chapitre V est donc consacré à une étude détaillée du texte des auditions de témoins, car nous espérons que leur caractérisation amènera non seulement des éléments pour leur traitement automatique, mais également des pistes de réflexion sur la production de ces textes : la prise en note, le dispositif de l’audition, la forme du texte consigné seront évoqués.