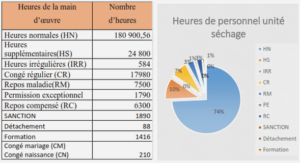
L’importance relative
La définition de l’importance relative n’est pratiquement jamais explicitée dans la présentation des résultats d’études. En réalité l’emploi du terme « importance » est source de confusion, et a été abordée de plusieurs façons et par différents auteurs (Johnson (2000), Cosnefroy et Sabatier (2011)). Nous allons présenter ci-après le contexte et des références sur ce sujet.
Importance relative des prédicteurs : contexte et références.
La comparaison des prédicteurs en termes d’importance relative a fait l’objet de différentes solutions proposées depuis 1960 jusqu’aux années 2000. Tout d’abord, l’approche sera différente dans l’exploitation des modèles directs (c‘est à dire non structurels) de régression selon qu’il s’agira d’une perspective de prévisionoud’explication.
Dans le cas d’une approche de prévision l’apport collectif combiné des prédicteurs (le R²) sera typiquement la valeur intéressante plutôt que de savoir distinguer la contribution relative des prédicteurs. Nous sommes là dans l’approche qui consiste à se satisfaire d’une prévision efficace sans pour autant chercher à comprendre en détail les contributions relatives des prédicteurs.
Dans le cas d’une approche explicative, des chercheurs qui se sont intéressés à la notion d’importance ont identifié deux étapes majeures dans l’utilisation des modèles de régression : sélection des variables du modèle et puis comparaison des prédicteurs. (Cf. Cosnefroy Sabatier(2011) ; Azen et Budescu, (2003), Azen (2003).
En ce sens les prédicteurs abandonnés au stade de la sélection sont réputés d’importance nulle. Par exemple dans certains cas les clients voudront identifier les variables d’importance en cherchant un sousensemble de prédicteurs qui ensemble conduisent à un R² aussi élevé que possible. Pour minimiser l’erreur de prévision d’autres critères sont cependant recommandés comme , ou le Press. Si le nombre de prédicteurs à considérer est imposé, le 2 R maximum sera recherché, si p n’est pas imposé sera minimisé. Desméthodes de sélection pas à pas (descendantes ou ascendantes, stepwise) sont notammentdisponibles.Schafer (1991) puis Nathan, Oswald, Nimon (2012)) ont considéré des méthodes où l’ordre des prédicteurs tient compte d’une hiérarchie de pertinence connue a priori (relevant known ordering) et se placent donc dans un processus ou chaque variable est introduite en fonction d’une théorie préalable.
Dans le cas où un modèle organisé est postulé, par exemple si des variables ont des effets directs et indirects, le modèle analytique pourra être un modèle de chemin (path model). Nous n’analyserons pas dans cette section la notion d’importance dans le cas d’un modèle structuré ou ordonné car elle est naturellement différente, nous nous intéressons donc au modèle direct sans a priori sur la pertinence des prédicteurs.
Importance des prédicteurs : formalisation et méthodes utilisées.
La problématique d’importance consiste à allouer à chaque prédicteur une valeur numérique représentant son « importance » par rapport à un y. De façon intuitive l’idée est qu’une modification d’une des variablesjX jouant un rôle de prédicteur influencera les valeurs prises par la variable à prédire y.
Il existe donc une grande variété de modèles possibles. Nous pouvons définir une fonctiond’importance de la façon suivant e : Soit un ensemble de p variables aléatoires réelles jX constituant un ensemble de prédicteurs. Notons P = {1,…,p} le sous-ensemble composé des indices de ces p variables. Soit y une variable à prédire également sous la forme de variable aléatoire réelle.
Carré des corrélations bivariées (first)
Cette méthode consiste à affecter à chaque prédicteur une valeur d’importance proportionnelle au carré de la corrélation bivariée entre le prédicteur et la variable à prédire. Cette méthode a été qualifiée de « first » : l’emploi du terme « first » signifie simplement qu’ils sont entrés en premier et en fait seulement inclus dans chaque modèle, par comparaison aux autres choix et qui mettent en jeu des séquences possibles d’introduction deplusieurs prédicteurs dans le modèle.
Décomposition de la variance
Décomposition de la variance
La décomposition de la variance a été proposée par plusieurs praticiens d’études de marchés. Dans d’autres secteurs d’activité la décomposition de la variance a également été utilisée pour quantifier la relative importance des prédicteurs : sciences humaines, mathématiques financières. Grömping (2007) a présenté le cadre général de la décomposition de la variance dans le cas du modèle linéaire.
Rangement d’importance
Soit une fonction d’importance et soit un échantillon d’observations de p prédicteurs et d’une variable à prédire. Chaque prédicteur reçoit une valeur d’importance par la fonction d’importance I. Soit I(P) l’ensemble de ces valeurs. I(P) est un ensemble fini d’au plus p valeurs distinctes de . A chaque variable de j de 1 à p nous pouvons associer un rang r(j) par ordre décroissant avec la convention que si deux variables ou plus ont la même importance elles auront le même rang et le nombre de rangs sera alors strictement inférieur à p. Le Rangement d’Importance est le vecteur.
Discussion et conclusions sur la décomposition de la variance.
La décomposition de la variance a été introduite en raison de la difficulté à appliquer pour l’analyse des leviers les recommandations des ouvrages de références, qui consistent à utiliser un nombre limité de prédicteurs et à retenir les standardisés de l’OLS pour mesurer l’importance relative.
L’utilisation des résultats de décomposition de la variance (notamment Shapley Value et Relative Weight Analysis) a été promue dans l’activité des études de marché en raison d’une certaine stabilité dans le cas d’échantillons de taille réduite (quelques centaines d’observations) et du fait que les coefficients sont tous positifs.
Néanmoins la décomposition de la variance ne saurait en fait être un substitut à une modélisation et son utilisationinconsidérée risque de fausser l’interprétation. Nous avons montré sur des exemples de structures de variables que les proportions et l’ordre des leviers peuvent être changés par rapport l’OLS.
Aussi, l’absence de réflexion sur la réelle signification des corrélations entre prédicteurs peut conduire à accepter que plusieurs leviers isolément aient chacun un faible poids alors que si ils sont fortement corrélés ils peuvent en réalité représenter un même phénomène important comme levier d’action. Plus fondamentalement il y a une contradiction intéressante entre vouloir d’un côté des alphas de Cronbach élevés pour conforter une cohérence entre les mesures et de l’autre côté regretter la colinéarité et ne pas tenter de l’interpréter alors que les variables mesurées sont choisies par le praticien qui formule les questions. Aussi si deux prédicteurs sont fortement corrélés l’analyse devrait plutôt porter sur une sélection éventuelle de variables ou la construction d’une variable combinée que de considérer que la réponse est de partager leur valeur d’importance comme par exemple en divisant des parts de variance.
Dans le cas des études de marchés poser plusieurs questions connexes sur un facteur important pourrait être interprété de façon erronée en considérant via l’allocation de variance qu’aucun des prédicteurs concernés n’est vraiment important alors que le facteur implicite mesuré par plusieurs réponses l’est réellement. Nous avons montré que dans le cas de deux prédicteurs, lmg-Shapley et les poids de Johnson (RWA) étaient identiques, et dans le cas de plus de deux prédicteurs il a été montré sur des configurations bien choisies de décomposition par orthogonalisation que cette approche permettait d’obtenir des cas ou le last et le first d’un prédicteur donné parmi les prédicteurs de départ était atteint lors de cette décomposition par vecteurs des orthogonaux particuliers. Enfin les jeux de données utilisés ont confirmé la forte proximité desrésultats entre ces deux méthodes.
Ceci a amené à proposer un mode de calcul alternatif à la Shapley Value et à la décomposition de Johnson permettant aussi d’attribuer des parts de variance expliquée à chaque prédicteur. Cette méthode de calcul (weifila pour weighted first last) est plus simple que Shapley Value ou Johnson, faisant directement appel aux corrélations bivariées et semi partielles entre les prédicteurs et la variable à prédire. Cette nouvelle approche permet sélectionner des estimateurs d’importance intermédiaires entre les last et les first, dont le résultat est identique à lmg-Shapley ou johnson pour deux prédicteurs et très proche avec plus de deux prédicteurs. En ce sens l’argument de certains auteurs (Johnson, Lebreton) selon lequel la proximité de ces deux mesures est un gage de validité intrinsèque ne nous paraît donc absolument pas fondé car ces méthodes en réalité réalisent toutes trois les mêmes choses en arbitrant entre les last et les first.
En conclusion la décomposition de la variance peut être envisagée comme un outil exploratoire mais il estdéconseillé de l’utiliser comme estimateur de l’importance individuelle des prédicteurs comme sielle permettaitde simuler un impact relatif, c’est-à-dire l’impact sur la variable à prédire d’un changement donné sur les valeursd’un prédicteur (par exemple une augmentation de notation d’un point en moyenne sur un attributdans uneenquête de satisfaction). En effet comme indiqué plus haut ceci nécessite un choix de modèle et deméthode desimulation. Ceci a d’ailleurs été relevé par plusieurs auteurs (Grömping, (2007), Johnson, (2000).
Il a été également relevé dans cette recherche que c’est à tort que la méthode de Fabbris était considérée (Grömping (2015)) comme identique à la décomposition de Genizi-Johnson. Enfin plusieurs résultats concernant les CAR scores (Strimmer 2011) ont été rejetés.
A ce stade, c’est-à-dire avant de prendre en compte les avantages possibles des méthodes fondées sur des techniques plus récentes que la décomposition de la variance comme par exemple les forêts aléatoires, nous ne concluons donc pas comme Grömping (2015) à privilégier l’approche lmg Shapley ou pmvd.
Apports des forêts aléatoires
Introduction
Les arbres de régression et de classification (CART : Classification and Regression Trees) sont une méthode de référence en apprentissage. Elles consistent à répartir les observations en sous-ensembles de façon récursive. Pour plus de détail sur les CART voir par exemple Hastie et al. (2009). Ces outils ont été utilisés en marketing et sont aisés à comprendre et interpréter mais leur mise en œuvre sur un échantillon donné du type deceux rencontrés dans le domaine des études de marchés présente des limitations importantes. Ainsi il est nécessaire de décider du critère de sélection d’un sous arbre pour éviter une croissance exponentielle du nombre de nœuds avec le nombre de niveaux, car sinon l’arbre devient trop grand et inutilisable car il s’ajuste trop bien aux données d’apprentissage. Les arbres peuvent présenter une instabilité au sens ou deux échantillons proches peuvent donner des résultats très différents et ne peuvent en fait être utilisés qu’avec des grands échantillons (au moins plusieurs centaines voire plusieurs milliers), ce qui dépasse souvent la taille de ceux utilisés dans l’activité d’études de marché.
Pour ces raisons les CART (Classification and Regression Trees) ont connu après une certain e popularité, un relatif oubli dans le secteur des études de marchés.
La méthode des forêts aléatoires (Random Forest) a en revanche permis de revisiter l’utilisation des arbres de régression dans le cas des études de marchés, après leur utilisation en bio statistique. Les forêts aléatoires permettent une quantification de l’importance relative (Breiman, (2001) ; Ishwaran (2007) ; Strobl et al, (2007) ; Grömping, (2009)). Dans le secteur des études de marchés cette méthode a notamment été utilisée dès 2007 par la société américaine Decision Analyst.
Nous allons d’abord présenter cette méthode puis aborder trois aspects, la comparaison entre les résultats obtenus avec les forêts aléatoires et les décompositions de la variance étudiées au chapitre 2, l’apport de ces méthodes pour la prise en compte des non-linéarités et finalement les possibilités de sélection de variables.
Présentation des forêts aléatoires (Random Forest)
Les forêts aléatoires peuvent être utilisées pour la classification ou la régression et ont été introduites par Breiman (2001). Une description très pédagogique de cette méthode a été faite par Tufféry (2015) dont nous rappellerons ci-après les principales propriétés.
La méthode des forêts aléatoires consiste à tirer des échantillons bootstrap, et à construire sur chaque échantillon du bootstrap un modèle d’une famille donnée (CART) et finalement à agréger ces modèles. Dans le cas de la régression cette agrégation se fait par la moyenne des prédictions des CART. Dans le cas du classement la méthode retenue est fréquemment le vote. La méthode des forêts aléatoires est un perfectionnement de la méthode du « bagging » (bootstrap aggregating) dans la mesure où chaque modèle ou chaque scission desarbres, au lieu d’être effectuée avec l’ensemble des p prédicteurs, sont faits à partir d’un sous-ensemble de q prédicteurs () qp tirés aléatoirement q étant constant. Quand q est strictement inférieur à p, il s’agit précisément deforêts aléatoire et non plus de bagging.
Remarques sur les temps de calcul
Sur la question des temps de calcul Grömping a pris soin de développer le package relaimpo en utilisant la matrice de covariance pour calculer ensuite les valeurs d’importance, ce qui fait que le programme n’est pas sensible au nombre des observations, car une fois les covariances calculées sur l’ensemble des observations, le reste des calculs ne se fait plus sur l’ensemble de l’échantillon. Mais le temps de calcul croit cependant avec le nombre de prédicteurs : doublement pour lmg-Shapley avec l’ajout d’un prédicteur et plus que doublement pour pmvd. Grömping (2006) présente l’exemple des temps de calculs suivants (en secondes).
Table des matières
Remerciements
Résumé
Abstract
Table des matières
Introduction
Notations et rappels
Chapitre 1 : Champ de la recherche
1.1 Les Etudes de Marché
1.2 L’analyse des leviers
Chapitre 2 : L’importance relative
2.1 Importance relative des prédicteurs : contexte et références
2.2 Importance des prédicteurs : formalisation et méthodes utilisées
2.2.1 Carré des corrélations bivariées (first)
2.2.2 Importance last
2.2.3 Importance beta square
Chapitre 3 : Décomposition de la variance
3.1 Décomposition de la variance
3.1.1 Décomposition de Pratt
3.1.2 lmg ou Shapley Value
3.1.3 Décomposition pmvd
3.1.4 Décomposition d’Owen
3.1.5 Décompositions par poids relatifs (Relative Weights Allocations)
3.1.6 Méthode de Green
3.1.7 Méthode de Fabbris
3.1.8 Méthode de Genizi et Johnson
3.1.9 Méthode des CAR scores
3.1.10 Méthode weifila (weighted first last) .
3.1.11 Analyse de sensibilité (Sensitivity Analysis)
3.1.12 Simulations
3.1.13 Discussion et conclusions sur la décomposition de la variance
Chapitre 4 : Apports des forêts aléatoires
4.1 Introduction
4.2 Présentation des forêts aléatoires (Random Forest)
4.3 Application des forêts aléatoires et comparaisons
4.4 Forêts aléatoires et non-linéarités
4.4.1 Analyse avec les données swiss
4.4.2 Simulations avec données quadratisées
4.5 Sélection de Variables avec VSURF
4.6 Remarques sur les temps de calcul
4.7 Conclusions sur l’apport des forêts aléatoires
4.8 Exemple et synthèse
Chapitre 5 : Vers des analyses causales ?
5.1 Réseaux bayésiens
5.1.1 Méthodes par contraintes
5.1.2 Méthodes d’optimisation d’un score
5.2 Exemples d’application
5.2.1 Outils et méthodes
5.2.2 Résultats
5.3 Commentaires sur l’utilisation des réseaux bayésiens
Chapitre 6. Conclusions et perspectives
6.1 Un sujet de recherches actif
6.2 Principaux résultats
6.3 Perspectives
Annexes
Annexe 1. Jeux de Données
Annexe 2. Scripts R utilisés
Annexe 3. Owen Value
Annexe 4. Calculs trigonométriques
Annexe 5. CAR scores
Annexe 6. Article publié
Bibliographie
![]()