NOTION SUR L’UML (UNIFIED MODELING LANGUAGE)
L’UML se définit comme un langage de modélisation graphique et textuel. Il est destiné à comprendre et décrire des besoins, spécifier et documenter les systèmes et sert aussi à esquisser des architectures logicielles, concevoir des solutions et communiquer des points de vue. L’UML unifie à la fois les notations et les concepts orientés objet. Il ne s’agit pas d’une simple notation graphique, car les concepts transmis par un diagramme ont une sémantique précise et sont porteurs de sens au même titre que les mots d’un langage
Les différents diagrammes d’UML
L’UML offre beaucoup de diagrammes qui servent à la modélisation des systèmes, nous allons présenter quelques diagrammes : Les diagrammes de cas d’utilisation, Les diagrammes de classes, Les diagrammes de navigation, Les diagrammes de séquence.
Pourquoi la méthode UML ?
L’UML est un langage formel et normalisé qui permet durant la phase de conception : Un gain de précision, Un gage de stabilité, Encourager l’utilisation d’outils, 60 Le langage UML est un support de communication performant : Il encadre l’analyse, Il facilite la compréhension de représentation abstraite complexe, Son caractère polyvalent et sa souplesse en font un langage universel.
Processus Unifié
L’UML propose des diagrammes pour décrire les différents aspects d’application mais ne précise pas la séquence d’étape à suivre ou la démarche à suivre pour la réalisation de ces diagrammes. Un processus de développement est alors nécessaire. Un processus unifié est un processus de développement logiciel construit sur la notation UML. Il est itératif et incrémental, centré sur l’architecture, conduit par les cas d’utilisation et piloté par les risques. La gestion d’un tel processus est organisée par quatre phases : pré étude, élaboration, construction et transition. Ses activités de développement sont la capture des besoins, l’analyse et la conception, l’implémentation, le test et le déploiement.
PHASE D’ANALYSE
La phase d’analyse a pour objectif d’identifier les acteurs qui interagissent avec le système et spécifier les fonctionnalités du système.
Identification des acteurs
La première étape de modélisation consiste à définir le périmètre du système, le contour de l’organisation. La seconde sert à modéliser et identifier les entités qui interagissent avec le système qui sont les acteurs. Définition : Un acteur représente un rôle joué par une entité externe (utilisateur humain, dispositif matériel ou autre système) qui interagit directement avec le système étudié. On peut regrouper les acteurs du système dans les catégories suivantes: L’administrateur serveur. L’administrateur station ou Chef de la station. L’observateur météorologique. L’usager aéronautique. Le visiteur. Dans les lignes qui suivent, nous allons identifier brièvement chacun de ces acteurs: L’administrateur serveur gère les stations membres. Il est chargé du site web. Il gère toute la mise en place technique et parfois la mission éditoriale, il doit gérer au jour le jour la technique et mettre à jour le contenu du site mis en ligne. L’administrateur station ou Chef de la station : son rôle détient tous les droits du site. Il peut attribuer ou retirer les droits d’accès aux autres utilisateurs (gère les utilisateurs du site et leurs profils). Il est chargé des modifications et mis à jour des renseignements techniques concernant la station d’observation sous sa responsabilité. 61 L’observateur météorologique : il peut accéder au site pour faire les différentes sortes de saisies et codification des messages correspondantes, afficher le TCM, et consulter les messages des autres stations météorologiques membres sur le plateforme. L’usager aéronautique : il peut visualiser en temps réel les derniers messages d’observations météorologiques aéronautiques disponibles à la station. Le visiteur : il ne peut visualiser que l’aide offerte en ligne et les pages d’inscription et de connexion.
Architecture
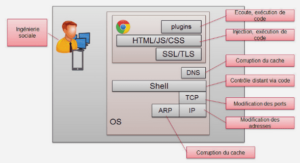
L’architecture de notre application est de type client-serveur, où un ordinateur interagit avec d’autres sur Internet. D’une façon générale, l’architecture client-serveur s’appuie sur un poste central, le serveur, qui envoit des données aux machines clientes suite à des requêtes reçues. Des programmes qui accèdent au serveur sont appelés programmes clients (client FTP, client mail, navigateur). [3] Serveur : Initialement passif en attente d’une requête, À l’écoute, prêt à répondre aux requêtes clientes, Quand une requête lui parvient, il la traite et envoie la réponse. Client : Actif en premier, Envoie des requêtes au serveur, Attend et reçoit les réponses du serveur. Les clients et le serveur doivent utiliser le même protocole; un serveur peut répondre à plusieurs clients en simultanéFigure 12 : Architecture client-serveur du projet Avantages Unicité de l’information : toutes les données sont stockées sur un même serveur, Meilleure sécurité : simplification des contrôles de sécurité, Meilleure fiabilité : en cas de panne, seul le serveur fait l’objet d’une réparation, Architecture plus mature que les autres, Facilité d’évolution : architecture évolutive, il est très facile de rajouter ou d’enlever des clients ou déplacer le serveur. Inconvénients Un coût d’exploitation élevé (ordinateur et connexion), En cas de panne du serveur, plus aucun client n’a l’accès aux informations,La modélisation conceptuelle des données permet de dégager l’ensemble des données manipulées en vue d’élaborer le diagramme de classes. En effet, ce dernier donne une vue statique du système. Il décrit les types et les objets du système. Il s’agit donc d’une représentation des données du champ de l’étude ainsi que le lien sémantique entre ces données, facilement compréhensible, permettant de décrire le système d’information à l’aide des concepts proposés par le modèle UML.
Le dictionnaire des données
Il permet de recenser les informations nécessaires. Il précise le libellé des données, le nom de chaque champ, le type, la dimension et le libellé des données utilisées. On va présenter ces données selon les entités : Observations horaires et synoptiques, Observations irrégulières, Observations journalières, Observations hebdomadaires, Observations mensuelles et les données TCM calculées. Les tableaux suivants nous donnent les différentes variables en fonction des observations