Télécharger le fichier original (Mémoire de fin d’études)
Notre approche et nos motivations de l’utilisation de traces`a grande ´echelle
Dans le cadre de neOCampus, un centre de calcul pour un campus doit ˆetre capable de r´ealiser des calculs importants. Les traces Google permettent donc de viser une grande charge.
Dans ces travaux de th`ese, l’utilisation de traces r´eelles a une vocation de validation et simuler un environnement r´eel. Elles ont pour rˆole :
– de garantir l’utilisation des ressources ;
– de mesurer et respecter la QoS ;
– d’ˆetre utilis´ees dans un contexte d’infrastructure r´eel de centre de calcul qui lui-mˆeme est
compos´e de plusieurs serveurs ayant des caract´eristiques h´et´erog`enes ; Cependant, les services (tˆaches, jobs, VMs) qui la composent influent sur l’utilisation des ressources.
De part leurs placements sur des machines physiques, la QoS des utilisateurs sera influenc ´ee. Le placement des tˆaches, et leurs distinctions ainsi que les caract´eristiques des ressources vont impacter directement la consommation d’´energie. Par exemple, une tˆache longue ou courte utilisant n unit´es physiques consommera plus ou moins si elle est plac´ee sur un serveur poss´edant un microprocesseur d’une puissance plus ou moins grande. Afin de r´ealiser les validations des diff´erents algorithmes pr´esent´es dans le chapitre 5 et l’environnement de simulation pr´esent´e dans il faut des traces existantes avec des caract´eristiques r´eelles. Pour la r´ealisation des exp´erimentations (chapitre 6), nous allons utiliser des traces synth´etiques. L’objectif est d’analyser des traces existantes `a grande ´echelle pour obtenir un panel caract´eristique pour ´etablir de nouvelles traces. Il existe plusieurs traces `a grande ´echelle disponibles. Parallel Workload Archive [47] est un ensemble de traces sur des donn´ees d’utilisation de jobs pour des clusters ou des supercalculateurs.
Historiquement, elles ´etaient pour un usage de grilles de calculs et maintenant, elles se sont ´etendues pour des traces de charges de travail. Ces donn´ees ´emanent de centres de calcul
s´epar´es g´eographiquement ainsi que des mod`eles. Il y a des donn´ees provenant de processus r´eels et des donn´ees mod´elis´ees bas´ees sur du r´eel. De plus, certaines de ces donn´ees ont ´et´e mesur´ees, il y a plus d’une dizaine d’ann´ees. Afin de r´ealiser des traces synth´etiques, le choix s’est port´e vers les traces propos´ees par Google [8].
Celles-ci sont compos´ees de priorit´es li´ees `a la QoS, ou li´ees `a des contraintes temporelles. Ce sont des donn´ees r´eelles provenant d’un cluster de Google. Les traces Google sont compos´ees de 25 millions de tˆaches, de plus de 12 000 serveurs et ont ´et´e r´ecolt´ees sur 29 jours. L’´etude de ces traces sont tr`es pr´esentes dans la litt´erature et sont repr´esentatives des donn´ees `a grande ´echelle.
Les traces Google dans la litt´erature
Plusieurs ´etudes se sont pr´ec´edemment port´ees sur une meilleure compr´ehension de l’ensemble des traces Google et de leurs caract´eristiques. Cette litt´erature permet de connaˆıtre :
1. l’h´et´erog´en´eit´e de l’infrastructure des ressources physiques des centres de calcul ;
2. les ressources demand´ees par les tˆaches ;
3. la classification des tˆaches qui composent la charge de travail.
Reiss et al. [81] ont d´ecrit l’h´et´erog´en´eit´e des diff´erentes ressources physiques ( hardware)
pr´esentes dans les traces Google. Ils ont classifi´e les priorit´es en cinq cat´egories : Infrastructure avec une priorit´e de type Free . De plus, Reiss et al. [82] ont analys´e les performances des centres de calcul. Selon cet article, de nombreuses tˆaches longues ont une utilisation stable des ressources, ce qui aide les ordonnanceurs de ressources. Ils ont conclu que la configuration de la machine et la composition de la charge de travail sont h´et´erog`enes. Cette trace analys´ee nous
Les traces Google dans la litt´erature
permet de comprendre l’ensemble des donn´ees propos´ees par Google, l’importance d’un centre de calcul h´et´erog`ene pour adapter, par exemple, les ressources `a la demande. Cependant, ils n’ont pas fourni d’information sur la fa¸con d’utiliser cette charge de travail dans un autre contexte.
L’article [83] ´evalue l’´ecart entre les ressources demand´ees et celles consomm´ees par les tˆaches. La charge moyenne demand´ee par un processeur est de 10% sur les centres de calcul Google. Cette analyse de traces Google montre que les processeurs sont globalement sous utilis´es ce qui conduit `a une augmentation de l’´energie consomm´ee (90 % de la puissance de calcul du processeur disponible n’est pas utilis´ee). De plus, la majeure partie de la charge de travail a une faible priorit´e et n’est pas sensible `a la latence (note de capacit´e d’adaptation `a attendre une ressource). Cette analyse montre qu’il n’y a que tr`es peu de tˆaches sensibles ´egale `a 2 ou Dans cet article, les auteurs se concentrent sur le manque de consid´eration d’´energie dans les traces de Google.
Liu et al. [84] ont analys´e comment les serveurs sont g´er´es dans le cluster et comment la charge de travail se comporte. Selon eux, il y a plus de 870 ´ev´enements machines en moyenne chaque jour. Dans cette ´etude, ils ont group´e les diff´erentes machines par mˆeme CPU et m´emoire (15 groupes). Contrairement `a [82], [84] montrant que les machines sont presque homog`enes, 93 % machines ont les mˆemes capacit´es CPU et 86 % des machines ont les mˆemes capacit´es de m´emoires. Les auteurs ont ´egalement explor´e la dur´ee de vie de la charge de travail. Ils montrent que beaucoup de tˆaches sont tu´ees, car 40,52 % des tˆaches ordonnanc´ees sont tu´ees au moins unefois. Alam et al. [85] ont fourni une analyse statistique des traces pour faire ´emerger des profils de travail de r´ef´erence. Ils ont fond´e cette approche sur l’utilisation des ressources, le regroupement des mod`eles de charge de travail et la classification des tˆaches avec des regroupements. Ils ont d´emontr´e que les tˆaches Google sont tri-modales. Ils peuvent ˆetre Jobs longs, Jobs courts et Jobs moyens. Chaque type de job peut ´egalement ˆetre sous-cat´egoris´e comme Utilisation faible des ressources, Utilisation moyenne des ressources et Ressources affam´ees. Ils ont group´e des jobs avec un k-mean, avec k ´egal `a 5 (nombre de classes). Les jobs peuvent ´egalement ˆetre class´es en courts, presque moyens, moyens, presque longs et longs. Ce clustering vise `a utiliser cette charge de travail dans un simulateur. Le regroupement des profils de tˆaches est ´egalement le r´esultat principal de [86].
Ces ´etudes montrent que les donn´ees de la charge de travail sont caract´eris´ees (priorit´e, sensibilit ´e `a la latence). La partie suivante pr´esente la composition des traces Google et l’articulation de toutes ces donn´ees entre elles.
Table des matières
R´esum´e
Abstract
Abr´eviations
Table des figures
1 Introduction
1.1 Contexte
1.1.1 Quelques chiffres
1.1.2 neOCampus
1.1.3 ADREAM
1.2 Probl´ematiques de recherche
1.3 Contributions scientifiques
1.4 Plan du manuscrit
2 ´Etat de l’art : gestion de l’´energie renouvelable dans un centre de calcul
2.1 La composition des centres de calcul verts
2.1.1 Des architectures de centre de calcul mono site
2.1.2 Des architectures de centres de calcul distribu´es g´eographiquement
2.1.3 Les composants de stockage pour am´eliorer l’utilisation d’un centre de calcul
2.1.4 Positionnement et objectifs
2.2 Les ordonnancements et politiques de placements
2.2.1 La reconfiguration dynamique
2.2.2 L’utilisation d’algorithmes gloutons
2.2.3 Les algorithmes multicrit`eres
2.2.4 Positionnement et objectifs
2.3 Les simulateurs de gestion de centres de calcul
2.3.1 Les simulateurs d’environnement distribu´e
2.3.2 Les simulateurs d´edi´es aux r´eseaux intelligent pour les centres de calcul verts
2.3.3 Positionnement et objectifs
2.4 Conclusion
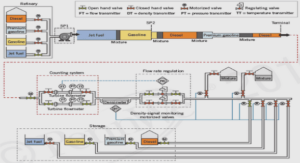
3 Environnement de simulation pour la gestion des flux dans un r´eseau intelligent
3.1 Approche de conception d’un r´eseau intelligent
3.1.1 Impact d’un r´eseau intelligent centralis´e
3.1.2 D´efinition d’un r´eseau intelligent
3.1.3 Caract´eristiques d’un r´eseau intelligent
3.1.4 Objectifs d’un r´eseau intelligent
3.2 Sp´ecifications d’un simulateur permettant la gestion des diff´erents flux ´evoluant dans un r´eseau intelligent
3.2.1 Un r´eseau intelligent supervis´e par un module de contrˆole
3.2.2 Les motivations de la cr´eation d’un simulateur
3.2.3 Fonctionnalit´es attendues
3.3 Description et sp´ecification des ´el´ements d’un r´eseau intelligent
3.3.1 Mod´elisation de l’architecture du r´eseau intelligent
3.3.2 Le centre de calcul
3.3.3 Les sources d’´energies
3.3.4 D´efinitions des diff´erents flux circulant dans un r´eseau intelligent
3.3.5 Bilan de l’architecture mat´erielle du r´eseau intelligent pour la cr´eation d’un simulateur de co-simulation
3.4 Le module de contrˆole : la prise de d´ecision
3.4.1 Le contrˆole des flux informatiques : un ordonnanceur
3.4.2 Le contrˆole des flux ´energ´etiques : le contrˆole du bus
3.4.3 Bilan de la prise de d´ecision
3.5 Conclusion et limites
4 Analyse de charges de travail de serveurs `a grande ´echelle
4.1 Notre approche et nos motivations de l’utilisation de traces `a grande ´echelle
4.2 Les traces Google dans la litt´erature
4.3 Composition des traces Google : des donn´ees de tailles importantes
4.3.1 Structure des traces Google
4.3.2 Cycle de vie des tˆaches
4.4 Notre analyse des traces Google
4.4.1 Le nombre d’´ev´enements par tˆache
4.4.2 Le nombre de tˆaches `a trois ´ev´enements
4.4.3 Les ´ev´enements de fin pour les tˆaches
4.4.4 Les temps d’ex´ecution des tˆaches
4.4.5 Le CPU utilis´e pour les diff´erentes tˆaches
4.4.6 La QoS des diff´erentes tˆaches
4.4.7 Bilan
4.5 Mod´elisation des donn´ees Google pour leur impl´ementation dans RenewSim conception des traces synth´etiques
4.6 Conclusion et limites
5 Ordonnancement sous contraintes : maximiser l’utilisation de l’´energie renouvelable
5.1 Approche par ordonnancement sous contraintes
5.1.1 La cr´eation d’une charge de travail agile
5.1.2 Utilisation d’algorithmes gloutons
5.2 Sp´ecifications des algorithmes
5.2.1 Contexte
5.2.2 Objectifs
5.2.3 Les fonctionnalit´es attendues des algorithmes
5.3 Notre approche d’ordonnancement
5.3.1 Strat´egie d’ordonnancement
5.3.2 Proposition d’adaptation d’algorithmes existants
5.4 M´etriques pour l’´evaluation des algorithmes
5.4.1 M´etriques vertes
5.4.2 M´etriques de QoS
5.4.3 Exemples d’utilisation des m´etriques
5.5 Conclusion et limites
6 Exp´erimentations : ´evaluations et comparaisons
6.1 Sp´ecifications du simulateur pour les diff´erentes exp´erimentations r´ealis´ees
6.1.1 Composition du r´eseau intelligent
6.1.2 Les caract´eristiques des composants du r´eseau intelligent
6.2 Politiques de d´ecisions `a travers un mod`ele de description des donn´ees
6.2.1 Motivations des diff´erentes exp´erimentations sur le mod`ele de description
6.2.2 Exp´erimentation 1 : un mod`ele pour une gestion ´energ´etique port´ee vers le
renouvelable
6.2.3 Exp´erimentation 2 : un mod`ele ´economique port´e sur la r´eduction de la
facture d’´electricit´e
6.2.4 Bilan des mod`eles de d´ecisions
6.3 ´Evaluation et comparaison des diff´erents algorithmes de d´ecisions
6.3.1 Motivations des diff´erentes exp´erimentations sur les algorithmes de placements
6.3.2 Les r´esultats de placement pour chaque algorithme
6.3.3 Consommation d’´energie pour les diff´erents algorithmes
6.3.4 L’impact du nombre de VMs ordonnanc´ees et ´eject´ees pour chaque algorithme133
6.3.5 L’impact ´energ´etique pour chaque algorithme
6.3.6 Bilan
6.4 Dimensionnement de la taille de la batterie par rapport `a la production solaire .
6.4.1 Dimensionnement 1 : ´evolution du GEC sur une charge de travail agile
6.4.2 Dimensionnement 2 : ´Evolution du GEC sur une charge de travail constante142
6.4.3 Bilan du dimensionnement
6.5 Synth`eses et conclusion des exp´erimentations
7 Conclusions et perspectives
7.1 Bilan des contributions
7.2 Bilan des exp´erimentations
7.3 Perspectives
Bibliographie