EAU, ENVIRONNEMENT ET SANTE DANS UN ECOSYSTEME COTIER URBAIN
ANALYSE ET TRAITEMENT DES DONNEES ORIGINALES MOBILISEES
Durant la phase de mobilisation, beaucoup de données sont collectées. Il devient donc possible de faire une analyse descriptive et comparative de l’échelle domestique et à l’échelle urbaine en passant par l’échelle intra-secteur et inter-secteur (Sy, 2006). A Nouakchott, cette analyse s’est faite à une échelle inter et intra-communes. Dans l’objectif de comparer avec d’autres zones urbaines, l’analyse des données doit suivre des méthodes et tests statistiques reconnus (OMS, ONU-Habitat, 2011). Une fois que les bases de données sont finalisées sur Excel, celle de l’enquête ménage a été exportée sur le logiciel SPSS pour l’analyser selon des questions bien précises pour montrer les liaisons entre les différentes variables étudiées (Sy et al., 2013). Les données géographiques sont envoyées sur le logiciel ARCGIS, pour effectuer des analyses spatiales et réaliser les profils épidémiologiques qui s’imposent. Un travail similaire a été réalisé à Ventiane (Laos), où les SIG ont été utilisés pour dresser le profil épidémiologique des différents quartiers de la ville en se basant sur la géolocalisation du lieu de résidence des personnes enquêtées (Vallée, 2008).
Les méthodes d’analyses statistiques des données de l’enquête doctorale
C’est sur les logiciels SPSS et XLSTAT que toutes les analyses statistiques ont été réalisées afin de montrer les liaisons entre les différentes variables étudiées. La première analyse statistique effectuée est la distribution des fréquences de différentes variables au niveau communal. Ce travail a permis d’aboutir à la mise en place des tableaux et graphiques explicatifs de certaines réalités de la vie quotidienne des populations de la ville (types de Eau, environnement et santé dans un écosystème côtier urbain : Approche géographique à Nouakchott (Mauritanie) 39 ménage, modes d’approvisionnement en eau, types de latrines, etc.). Sur la base de ce travail nous avons pu estimer la prévalence de la diarrhée dans les différentes communes de la ville et même au niveau des secteurs qui les composent, afin de montrer la variabilité inter-commune. La deuxième étape est celle de l’analyse descriptive simple (tableaux croisés) entre la diarrhée et les autres variables qualitatives pour voir, de prime abord s’il existe une différence visible dans la répartition des fréquences. L’étape suivante est la réalisation des ANOVA (Analyse de la Variance) entre la diarrhée et plusieurs facteurs de risque. L’ANOVA est une technique qu’on peut utiliser pour déterminer l’importance statistique d’écarts entre les moyennes de deux groupes de variables ou plus, que celles-ci, soient quantitatives ou qualitatives. Parallèlement à la réalisation des ANOVA, des tests de X2 (Khi2) ont été réalisés avec pour objectif de vérifier s’il existe une relation entre le risque d’exposition de la population et la pathologie. Les différents tests réalisés ont permis d’analyser les liaisons entre les variables étudiées, la nature de leurs relations ainsi que la comparaison de moyennes entre diverses composantes d’un facteur significatif, dès lors, on peut connaître si la différence entre les deux variables analysées est significative ou pas (Sy, 2006). La valeur du P-value indique la probabilité de rejeter de manière erronée l’hypothèse nulle ou, en d’autres termes, le pourcentage de chances de « se tromper » en rejetant l’hypothèse de départ, qui est celle de l’égalité des deux moyennes. En règle générale, le seuil « acceptable » retenu en sciences sociales est de 0.05 (c’est-à-dire 5% de chances de rejeter par erreur l’hypothèse nulle) (Ivaldi, 2006). D’après Sy (2006), « en statistiques, avec un intervalle de confiance à 95%, on établit un niveau de risque appelé seuil de signification du test qui veut dire que le risque de se tromper sur une relation entre deux variables doit être absolument inférieur à 5%. Si la p-valeur est inférieure à 0.05, on dit que la différence est statistiquement significative au seuil de 5%. On se donne ainsi une limite supérieure de signification de la relation, le plus souvent p=0.05 (significatif), p=0.001 (très significatif), p=0.0001 (hautement significatif). Plus le risque d’erreur est faible en ce qui concerne la relation, plus le degré de signification est élevé ». Pour une bonne interprétation des données nous avons fait des regroupements de modalités (ex : source améliorée d’eau et source non améliorée d’eau, niveau socio-économique faible, moyen ou élevé). Nous avons utilisés ces regroupements pour réaliser une ACP (Analyse à Eau, environnement et santé dans un écosystème côtier urbain : Approche géographique à Nouakchott (Mauritanie) 40 Composante Principale), qui est une analyse analytique multi variée. Ce test statistique a permis d’établir une matrice de corrélation entre plusieurs variables observées.
Les méthodes d’analyses spatiales (géographiques)
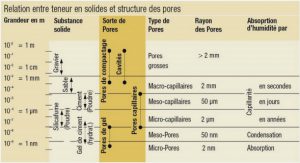
La représentation cartographique des indicateurs de santé permet la description de leur distribution spatiale, la mise en évidence de zones avec un risque élevé pour la suggestion d’hypothèses étiologiques (caractéristiques partagées par les unités géographiques) (InVS, 2011). Les méthodes géo-spatiales réalisées durant ce travail ont été faites sur la version 10.1 du logiciel ARCGIS développé par ESRI (Environmental Systems Research Institute). Les informations jusqu’ici collectées sont désagrégées au niveau des ménages, il fallait les transposer à l’échelle des communes. Pour cela les données de chaque commune ont été isolées, afin de calculer les valeurs moyennes pour les différents indicateurs à l’échelle de chacune d’elles. En s’appuyant sur les points GPS des ménages, ces informations ont été spatialisées pour être fusionnées avec les données de la carte numérique de la ville. Nous avons, ainsi obtenu une base de données spatiale avec l’ensemble des indicateurs de l’enquête que nous pouvons cartographier, au besoin, afin de contribuer à la prise de décision. Le même logiciel a été utilisé pour spatialiser des informations ponctuelles, comme les données sur la qualité de l’eau et les données épidémiologiques des structures de santé, obtenues préalablement.
LES LIMITES DE LA METHODOLOGIE UTILISEE
Les études de corrélations géographiques, notamment pour la construction d’indicateurs d’exposition ou de risque sont difficiles à interpréter au niveau individuel à cause du biais écologique, c’est-à-dire la différence potentielle entre le lien cause-effet individuel et celui estimé au niveau de groupe. Le biais écologique est dû à la variabilité intra-unité de l’exposition et des facteurs de risque (InVS, 2011). Cette dernière étude affirme que : « Les facteurs qui donnent confiance dans les résultats de ce type d’études sont la qualité des données, leur utilisation appropriée et la prise en compte de leurs limites. Les limites des données affectent les résultats des analyses statistiques et limitent les analyses qui peuvent être faites. Elles doivent être prises en compte au moment du choix du type d’étude ». La méthodologie développée dans cette recherche doctorale repose sur deux sources d’informations que sont les données existantes mobilisées auprès des acteurs clés du Eau, environnement et santé dans un écosystème côtier urbain : Approche géographique à Nouakchott (Mauritanie) 41 secteur de l’eau et de l’assainissement et les données quantitatives obtenues au moyen de l’enquête ménage réalisée dans la ville de Nouakchott en avril-mai 2012. Les premières données sont mobilisées auprès des différentes institutions et peuvent présenter des lacunes émanant de la méconnaissance de leur mode de collecte. Elles sont désagrégées à l’échelle des communes sans que l’on sache comment les échantillons ont été répartis entre les communes et à l’intérieur de chacune d’elles (entre les quartiers ou les secteurs) pour être représentatifs des réalités socioéconomiques et environnementales de celles-ci. Il faut dire que plusieurs institutions nationales n’ont pas voulu fournir des chiffres (ou données) officiels lors des entretiens individuels ou des documents supposés internes. Quant aux données issues de l’enquête ménage du mois de mai 2012, elles ont été limitées par certains problèmes dont : La lourdeur du questionnaire : il fallait environ 45 minutes pour l’administration d’un seul questionnaire. Ce qui est très long pour certains chefs de ménages qui sont occupés par leurs obligations professionnelles ou familiales. La difficulté pour les répondants (s’ils ne sont pas assistés) de répondre à l’intégralité des questions. La difficulté d’organisation des opérations de terrain avec des problèmes de concentration de ménages dans certaines zones enquêtées et des zones où les ménages sont très dispersés. La limite dans la réalisation des statistiques très poussées pour pouvoir tirer toute la matière de la base de données collectée
Introduction générale |