Implémentation d’un démonstrateur
Dans le chapitre précédent, nous avons réalisé une analyse fonctionnelle de CACDA et proposé un modèle de données adapté à son fonctionnement. Ce chapitre détaille le développement d’un démonstrateur, nécessaire à la validation empirique de notre approche (Figure 34). Ce démonstrateur est destiné à être testé dans le cadre de cas d’études industriels.
Structure logicielle du démonstrateur
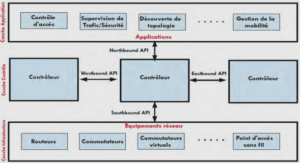
Le démonstrateur est développé en Python15, langage bien connu et disposant d’une large communauté et de nombreuses bibliothèques. L’utilisation de ces bibliothèques spécialisées facilite le développement, en particulier pour la communication du démonstrateur avec plusieurs ressources externes, notamment des outils de traitement du langage naturel et une base de données orientée graphe. Python sert donc de langage pivot entre les différentes couches spécialisées du logiciel (Figure 35). La première couche spécialisée est l’interface web de l’application, permettant l’interaction avec le concepteur. Elle est réalisée avec une bibliothèque Python nommée Dash16 qui fournit une infrastructure pour créer des interfaces web. L’interface du démonstrateur est présentée dans la suite de ce chapitre (Figure 43). La deuxième couche contient les outils spécialisés nécessaires au traitement du langage naturel. Il s’agit de Stanford CoreNLP 17 pour les algorithmes d’analyse, de l’ontologie ConceptNet18 et du thésaurus WordNet19 pour l’enrichissement sémantique. Ces outils sont utilisés lors de l’écriture du sous-contexte sémantique et de l’enrichissement sémantique du La dernière couche logicielle est celle de notre base de données. Nous utilisons la base de données orientée graphe NEO4J [97]. Comme mentionné dans l’état de l’art, NEO4J permet la modélisation d’un graphe de connaissances essentiel au raisonnement sur les données. Ce choix est tout d’abord justifié par la souplesse de NEO4J sur la structure des données, nous permettant d’améliorer notre modèle de données au fur et à mesure de l’avancée du développement du démonstrateur. L’outil permet également une interface simple avec des programmes externes, ce qui facilite le développement.
Fonctionnalités du démonstrateur
Le premier service de l’assistant est de structurer les règles de conception et le contexte de conception dans un graphe de connaissances. Comme présenté dans l’état de l’art, plusieurs approches existent pour extraire des règles de conception de documents en langage naturel [43]. Cependant, cette technologie est encore complexe à mettre en part et ne constitue pas le cœur de notre apport. En conséquence, nous considérerons pour notre démonstrateur, que l’ensembles des règles utilisées sont stockées dans des documents semi-structurés, listant les documents sources de ces règles, les chapitres auxquels elles appartiennent ainsi que leurs énoncés principaux (Tableau 11). Lors de l’analyse fonctionnelle de CACDA, nous avons identifié 3 services permettant d’améliorer la maîtrise des règles de conception. Notre démonstrateur apporte une réponse technique à chacun de ces services. Notre objectif est de réaliser un démonstrateur de CACDA afin que sa pertinence, son principe de fonctionnement et son utilisabilité puissent être testés.
Lors de la première étape, le démonstrateur lit la règle dans le document semi-structuré. Les outils de traitement du langage naturel de Stanford CoreNLP permettent au démonstrateur d’isoler les mots-clés (i.e. noms, verbes, adjectifs et adverbes) de la règle et de les réduire à leur base lexicale, appelée lemme. Ces lemmes sont ajoutés au graphe et reliés à la règle (Figure 37). Le processus de désambiguïsation consiste à choisir le bon sens de radius. L’assistant va comparer les listes représentatives des synsets avec une liste de référence de 400 mots issus du graphe de connaissances. Cette liste, extraite dans l’étape 2 de notre procédé, est constituée des 400 mots les plus proches de la règle dans le graphe (distance en nombre de relations). Le démonstrateur mesure alors un score de similarité basé sur le nombre de mots communs entre les deux listes comparées. Cette méthode, appelée similarité cosinus est largement utilisée pour calculer des similarités linguistiques [154], [157], [172]. Dans notre exemple, la définition la plus similaire à notre contexte est la première. Les informations correspondant à cette signification sont écrites dans le graphe (Figure 38), c’est le processus d’enrichissement sémantique.