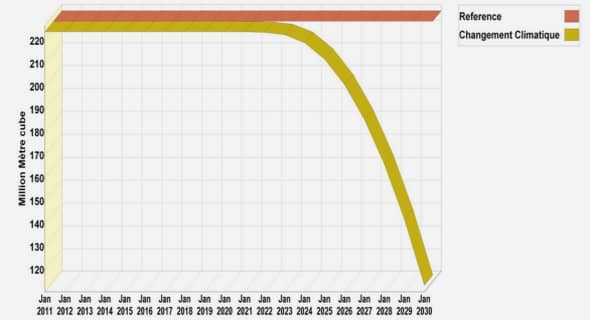
Les versions dans les bases de données orientées objet
Les modèles relationnels
Parmi les travaux qui étendent le modèle relationnel, deux approches se distinguent : – l’intégration du temps au niveau des attributs (McKenzie, 91), (Gadia, 92), – l’intégration du temps au niveau des n-uplets (Ben-Zvi, 82), (Snodgrass, 87), (Navathe, 89). Le langage d’interrogation est également étendu pour permettre l’interrogation selon des conditions temporelles (Snodgrass, 87), (Navathe, 89).
Le temps au niveau des attributs
L’intégration du temps au niveau d’un attribut consiste à conserver les valeurs successives prises par l’attribut d’une entité. Lors de la définition de schéma, une composante de type intervalle de temps est associée à chaque attribut. Pour chaque n-uplet, chaque valeur prise par un attribut est conservée et associée à la date, ou la période à laquelle elle correspond. Une entité est donc décrite, pour chaque attribut, par un ensemble de couples (valeur, date). Les relations dans ce cas ne sont plus en première forme normale mais s’apparentent au modèle NF2 (Sheck, 82). Exemple I-1 : Dans le modèle relationnel intégrant des aspects temporels de Chakravarthy & Kim (Chakravarthy, 93), certains attributs sont couplés à un attribut de type intervalle de temps. La période associée à la valeur d’un attribut est en général la période de validité (appelée également période de l’événement ou période logique) de la valeur associée. La période de validité d’une valeur est l’intervalle pendant lequel le fait décrit est vrai dans le monde réel modélisé (Jensen, 94). Certains travaux introduisent la notion de date de transaction (appelée également date physique) à la place de la date de validité ou en plus de celle-ci (Gadia, 92). La date de transaction est la date à laquelle une valeur est enregistrée dans la base de donnée. Pour manipuler le temps, différents types sont définis : – les points de temps : instants isolés dans le temps (ex. les dates d’obtention de diplôme de Durand), – les périodes : intervalles de temps (ex. la période d’emploi de secrétaire de Durand), – les durées : quantités de temps (ex. la durée d’emploi de secrétaire de Durand), – les valeurs temporelles complexes : union d’instants isolés dans le temps et/ou d’intervalles de temps (ex. l’ensemble des périodes de chômage de Durand). Des opérations ont été introduites pour manipuler ces types temporels. Différents opérateurs de comparaisons ont été définis (précède, pendant, succède, …) pour comparer des points de temps, des périodes, des points de temps et des périodes, … les opérations arithmétiques ont également été spécifiées pour additionner, …, supprimer des valeurs des différents types temporels (ex. 20 mars 1995 + 3 jours = 23 mars 1995) (Allen, 84), (Snodgrass, 87), (Navathe, 89).
Le temps au niveau des n-uplets
Les principes définis pour l’intégration du temps au niveau des attributs ont également été appliqués au niveau des n-uplets. Chaque valeur prise par un n-uplet est associée à une date ou une période. Un n-uplet représente donc une même entité du monde réel durant une période donnée du monde réel modélisé. L’intégration du temps dans une relation est spécifiée lors de la définition du schéma.
Exemple I-2 : Dans le modèle intégrant le temps au niveau des n-uplets de Snodgrass (Snodgrass, 87), la définition du schéma d’une relation PERSONNE prenant en compte le temps est la suivante : create interval PERSONNE (Matricule is integer, Nom is char, Adresse is char, Emploi is char) Le mot-clé interval indique que la relation intègre des intervalles de validité. La relation PERSONNE de l’exemple précédent se représente alors comme suit : Matricule Nom Adresse Emploi From To 1000 Durand Paris étudiante 1-1-80 10:00AM 7-31-82 5:00PM 1000 Durand Lyon comptable 7-31-82 5:00PM forever 1001 Lassalle Lyon stagiaire 5-1-85 8:00AM 12-31-88 12:00PM 1001 Lassalle Lyon vendeur 12-31-88 12:00PM forever L’intégration du temps au niveau des n-uplets permet d’obtenir ces relations en première forme normale. Cependant, la création d’un nouvel n-uplet pour une modification de la valeur d’un attribut pose un problème de redondance d’information pour les autres attributs. Pour pallier cet inconvénient, la notion de dépendance temporelle a été introduite (Navathe, 89). Les attributs ou groupe d’attributs dépendants du temps de manière indépendante ont une dépendance temporelle. Le processus de décomposition de relations est appliqué suivant les dépendances temporelles. Les relations obtenues après décomposition sont alors en forme normale temporelle. Exemple I-3 : dans l’exemple précédent, l’attribut Nom, l’attribut Adresse et l’attribut Emploi ont chacun une dépendance temporelle propre ; ces attributs ont des valeurs qui évoluent au cours du temps, indépendamment les uns des autres. Il existe donc les trois dépendances temporelles suivantes : T @ {Nom} T @ {Adresse} T @ {Emploi} T représente le temps Chapitre I. : Etat de l’art 11 La relation R (Matricule, Nom, Adresse, Emploi, From, To) est décomposée suivant les dépendances temporelles. L’attribut Matricule est clé primaire, c’est la clé indépendante du temps. Les trois relations R1, R2 et R3 suivantes sont obtenues: R1 (Matricule, Nom, From, To) R2 (Matricule, Adresse, From, To) R3 (Matricule, Emploi, From, To) R1, R2 et R3 sont en forme normale temporelle, et contiennent les n-uplets suivants : R1 Matricule Nom From To 1000 Durand 1-1-80 10:00AM forever 1001 Lassalle 5-1-85 8:00AM forever R2 Matricule Adresse From To 1000 Paris 1-1-80 10:00AM 7-31-82 5:00PM 1000 Lyon 7-31-82 5:00PM forever 1001 Lyon 5-1-85 8:00AM forever R3 Matricule Emploi From To 1000 étudiante 1-1-80 10:00AM 7-31-82 5:00PM 1000 comptable 7-31-82 5:00PM forever 1001 stagiaire 5-1-85 8:00AM 12-31-88 12:00PM 1001 vendeur 12-31-88 12:00PM forever
Les langages d’interrogation temporels
De nombreux travaux ont traité de l’extension des langages pour prendre en compte les aspects temporels (Tansel, 93). De nombreuses extensions ont été apportées aux langages relationnels notamment au langage SQL (Navathe, 89), (Sarda, 90), (Theodoulidis, 94). Le langage TSQL2 est en cours de normalisation (Snodgrass, 94). Les langages temporels sont essentiellement basés sur l’ajout d’une clause temporelle (clause WHEN) au niveau des requêtes. Des conditions de sélection basées sur l’utilisation d’opérateurs temporels sont spécifiées dans cette clause. Les conditions temporelles portent sur la comparaison de valeurs de types temporelles et plus particulièrement celle de la période de validité des n-uplets. La période de validité des n-uplets est également utilisée au niveau de l’affichage du résultat d’une requête.
Introduction |