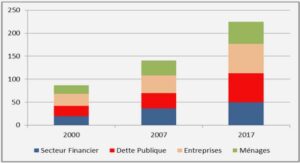
Analyse d’Algorithmes Stochastiques Appliqués à la Finance
Présentation
Dans la première partie, nous commençons par un chapitre introductif qui rappelle les principaux résultats “classiques” de la théorie de l’approximation stochastique en nous cantonnant cependant pour l’essentiel à un cadre markovien ou à innovations i.i.d.. Ces résultats nous serons utiles dans la seconde partie qui porte sur les applications, mais nous permettent aussi de faire un parallèle avec le cadre plus général présenté dans le second chapitre, où les innovations de l’algorithme mêlent des composantes aléatoires et déterministes. Un algorithme stochastique est une procédure récursive de recherche de zéro d’une fonction moyenne admettant un représentation sous forme d’espérance. Son analogue déterministe est l’algorithme de Newton. Plus précisément le but d’un tel algorithme est de trouver θ ∗ ∈ R d tel que h(θ ∗ ) = 0 où h(θ) = Z Rq H(θ, y)ν(dy), où ν est une mesure de probabilité (simulable) et H : R d × R q → R d est une fonction borélienne. Ceci nous mène donc à construire la procédure récursive suivante θn+1 = θn − γn+1H (θn, Yn+1), n ≥ 0, θ0 ∈ R d , (0.1) où (γn)n≥1 est une suite positive appelée pas de l’algorithme, (Yn)n≥1 est une suite de variables aléatoires i.i.d. de loi ν, indépendante de la variable initiale θ0, appelée innovations. L’étude des algorithmes stochastiques a commencé dans les années avec les travaux de Robbins-Monro [] et de Kiefer-Wolfowitz [72] (variante introduisant une méthode de différences finies à pas décroissant pour l’approximation d’une fonction moyenne de type gradient). Elle a fait l’objet de nombreux travaux liés au contrôle adaptatif (voir [], [75]), aux estimations recursives (voir [], [87]), etc. Des généralisations à des suites d’innovations non i.i.d. ont également été étudiées de façon approfondie : chaînes de Markov (voir [25]), processus mélangeants (voir [39]), suites à discrépances faibles (voir [81]), et de nombreuses applications dans des domaines variés ont également été considérées (physique, théorie des jeux, statistique par exemple). Remarquons que la procédure récursive définie par (0.1) peut se réécrire sous la forme θn+1 = θn − γn+1 (h(θn) + ∆Mn+1), n ≥ 0, θ0 ∈ R d , (0.2) où ∆Mn+1 = H (θn, Yn+1) − h(θn) est un Fn-accroissement de martingale locale (qui se révèle être une vraie martingale sous des hypothèses naturelles sur H) avec Fn := σ(θ0, Y1, , Yn) la filtration associée à l’algorithme. Lorsque les innovations ne sont pas supposées i.i.d., la procédure récursive (0.2) peut se réécrire θn+1 = θn − γn+1 (h(θn) + ∆Mn+1 + rn+1), n ≥ 0, θ0 ∈ R d , (0.3) où ∆Mn+1 = H (θn, Yn+1) − E [H (θn, Yn+1)| Fn] est un Fn-accroissement de martingale locale et rn+1 = E [H (θn, Yn+1)| Fn] − h(θn) est un terme de reste Fn+1-adapté. Dans le Chapitre 1, nous rappelons d’abord les résultats de convergence des procédures déterministes, puis ceux du cadre stochastique. Il existe deux méthodes pour montrer la convergence p.s. de l’algorithme : l’une basée sur une approche martingale via le Lemme de Robbins-Siegmund (utile pour faire le parallèle avec le second chapitre) et l’autre fondée sur la méthode de l’EDO qui relie l’algorithme (0.2) au comportement asymptotique de l’équation différentielle ˙θ = −h(θ). Un résultat de convergence pour les algorithmes contraints est aussi mentionné. Nous rappelons ensuite le résultat de vitesse de convergence, à savoir le TCL, obtenu par la méthode de l’EDS et clôturons ce chapitre par le principe de moyennisation de Ruppert et Polyak qui permet d’obtenir la variance asymptotique minimale. Le reste de cette thèse est organisé comme suit : Chapitre 2, nous présentons un résultat de convergence pour des algorithmes stochastiques où les innovations vérifient une hypothèses de moyennisation avec une certaine vitesse. Nous l’appliquons ensuite à différents types d’innovations (suites i.i.d., suites à discrépance faible, chaînes de Markov homogènes, fonctionnelles de processus α-mélangeant) et nous l’illustrons à l’aide d’exemples motivés principalement par la Finance. Chapitre 3 nous présentons un résultat de vitesse “universelle” de convergence dans le cadre d’innovations équiréparties dans [0, 1]q . Nous confrontons nos résultats à ceux obtenus dans le cadre i.i.d. et nous les illustrons à l’aide d’un exemple pour des suites i.i.d. et à discrépance faible. Le Chapitre 4 présente un problème d’allocation optimale appliqué au cas d’un nouveau type de place de trading : les dark pools. Ces places proposent un prix d’achat (ou de vente) certain, mais n’assurent pas le volume délivré. Le but est alors d’exécuter le maximum de la quantité souhaitée sur ces places. Ceci mène à la construction d’un algorithme stochastique sous contraintes à l’aide du Lagrangien. Nous l’étudions ensuite dans deux cadres : celui d’innovations i.i.d. et celui où elles sont moyennisantes. Nous présentons ensuite une procédure alternative basée sur un principe de renforcement. Enfin les performances des deux algorithmes sont comparées dans différents cadres (i.i.d., α-mélangeant et données réelles) mais aussi à celles d’un agent initié. Le Chapitre 5 présente un algorithme d’optimisation pour trouver la meilleure distance de placement dans un carnet d’ordre : il s’agit de minimiser le coût d’exécution d’une quantité donnée. Ceci mène à la construction d’un algorithme stochastique sous contraintes avec projection. Pour assurer l’existence et l’unicité de l’équilibre, nous avons besoin d’hypothèses sur la fonction de coût, ce qui aboutit à des critères suffisants sur certains paramètres du modèle obtenus en utilisant un principe de monotonie opposée pour les diffusions unidimensionnelles. Le Chapitre 6 porte sur l’implicitation et la calibration de paramètres dans des modèles financiers. La première technique mène à un algorithme de recherche de zéro et la seconde à une méthode de gradient stochastique. Pour cette dernière, il existe plusieurs approches (à l’aide du processus tangent ou par différences finies) que nous présentons. Nous illustrons ces deux techniques par des exemples d’applications sur 3 modèles : le modèle de Black-Scholes, le modèle de Merton et le modèle pseudo-CEV. Le Chapitre 7 porte sur l’application des algorithmes stochastiques dans le cadre de modèles d’urnes aléatoires utilisés en essais cliniques. A l’aide des méthodes de l’EDO et de l’EDS, nous retrouvons les résultats de consistance (convergence p.s.) et de normalité asymptotique (T CL) de [] mais sous des hypothèses plus faibles sur les matrices génératrices. Nous étudions aussi les modèles “multi-bras”, notamment le modèle introduit dans [19], pour lequel nous retrouvons le résultat de convergence p.s. et nous montrons un nouveau résultat de normalité asymptotique par simple application du T CL pour les algorithmes stochastiques. Les principaux résultats de cette thèse sont les suivants 0.2 Algorithmes stochastiques avec innovations moyennisantes Ce chapitre est basé sur un article accepté dans Monte Carlo Methods and Applications. Le but de ce chapitre est d’établir un théorème de convergence pour des algorithmes stochastiques multidimensionnels quand les “innovations” vérifient des hypothèses de moyennisation “faibles” en présence d’une fonction de Lyapunov trajectorielle. Ces hypothèses de moyennisation nous permettent d’unifier plusieurs cadres : celui où les innovations sont simulées (possiblement déterministes comme pour les nombres quasi-aléatoires aussi connus sous le noms de suites à discrépance faible ou QMC) et celui où elles sont exogènes (comme des données de marché) avec des propriétés (de vitesse) d’ergodicité. Nous proposons plusieurs champs d’applications en termes d’innovations, à savoir des suites i.i.d., des nombres quasi-aléatoires, des fonctionnelles de processus α-mélangeant ou des chaînes de Markov homogènes.
Description du cadre
Dans ce chapitre, on considère un cadre général pour des algorithmes stochastiques de la forme θn+1 = θn − γn+1 (H(θn, Yn) + ∆Mn+1), n ≥ 0, (0.4) où θ0 est une variable aléatoire à valeurs dans R d , (Yn)n≥0 est une suite de variables aléatoires à valeurs dans R q et ∆Mn+1 est un accroissement de martingale, tous définis sur le même espace de probabilité (Ω, F, P). De plus θ0 ∈ L 1 (P) et θ0 est indépendant de (Yn)n≥0. La suite de pas (γn)n≥1 est décroissante et H est une fonction borélienne de R d × R q dans R d . Nous noterons Fn = σ(θ0, Y0, Y1, , Yn), n ≥ 0, la filtration naturelle du processus des innovations (Yn)n≥0. Aucune hypothèse markovienne n’est faite a priori sur la suite (Yn)n≥0. Nous dirons que la suite (Yn)n≥0 vérifie une hypothèse de ν-stabilité si P(dω)-p.s. 1 n nX−1 k=0 δYk(ω) (Rq ) =⇒n→∞ ν (0.5) où (Rq ) =⇒ désigne la convergence étroite de mesures de probabilité définies sur (R q , Bor(R q )). L’algorithme stochastique défini par (0.4) est alors une recherche récursive de zéro de la fonction moyenne (asymptotique) h(θ) := Z Rq H(θ, y)ν(dy). (0.6) Soient p ∈ [1, ∞) et (εn)n≥1 une suite positive telle que εn −→n→∞ 0 et limn inf nεn = 0. (0.7) Soit Vεn,p la classe de fonctions dont la vitesse de convergence, p.s. et dans L p (P), dans le Théorème de Birkhoff est ε −1 n , c’est-à-dire Vεn,p = ( f ∈ L p (ν)| 1 n Xn k=1 f(Yk) − Z f dν P-p.s. & Lp(P) = O(εn) ) . Les principaux résultats obtenus sont les suivants.
Convergence p.s.
Le résultat principal de ce chapitre est le théorème suivant, analogue au Lemme de RobbinsSiegmund. Théorème 0.1. (a) Bornitude : Soient h : R d → R d vérifiant (0.6), H : R d×R q → R d une fonction borélienne et (Yn)n≥0 une suite de variables aléatoires vérifiant (0.5). Supposons qu’il existe une fonction continûment différentiable L : R d → R + vérifiant ∇L est lipschitzienne, continue et |∇L| 2 ≤ C (1 + L), et que la pseudo-fonction moyenne H vérifie l’hypothèse de Lyapunov trajectorielle ∀θ ∈ R d\{θ ∗}, ∀y ∈ R q , h∇L(θ)| H(θ, y) − H(θ ∗ , y)i ≥ 0. Soit p ∈ [1, ∞) et (εn)n≥1 une suite positive vérifiant (0.7). Supposons que H(θ ∗ , ·) ∈ Vεn,p. De plus, supposons que H vérifie l’hypothèse de croissance (quasi-)linéaire suivante ∀θ ∈ R d , ∀y ∈ R q , |H(θ, y)| ≤ CHφ(y)(1 + L(θ)) 1 2 et que la suite d’accroissements de martingale (∆Mn+1)n≥0 vérifie pour tout n ≥ 0, P-p.s. E |∆Mn+1| 2∨ p p−1 | Fn ≤ CMφ(Yn) 2∨ p p−1 (1 + L(θn))1∨ p 2(p−1) si p > 1, |∆Mn+1| (1+L(θn)) 1 2 ≤ CM si p = 1 où CM est une constante réelle positive et supn≥0 kφ(Yn)k2∨ p (p−1) < +∞. Soit γ = (γn)n≥1 une suite positive décroissante de pas vérifiant X n≥1 γn = +∞, nεnγn −→n→∞ 0, et X n≥1 nεn max
Introduction |