Les étapes de modélisation d’une situation
de crise dans la litterature
Introduction
Suite à un évènement majeur (Lagadec, 1994), les décideurs doivent rapidement recueillir des informations pertinentes, obtenues si possible selon un processus de recherche et d’analyse éprouvé, pour comprendre la « dynamique générale » de la crise. Dans ce contexte, nous proposons de mettre au point un système d’information capable de générer un ensemble structuré d’informations décrivant la situation de crise en cours. Cet ensemble, présenté sous forme de modèle (Bézivin, 2005), doit alimenter directement le niveau 2 de conscience des décideurs, c’est-à-dire leur compréhension de la situation de crise, via une Common Operational Picture (COP) adaptée à chaque cellule de crise. Le chapitre 1 nous a permis d’identifier notre problématique : Comment collecter, puis interpréter des données brutes issues de sources hétérogènes pour déduire un ensemble d’informations structuré et utilisable, décrivant une situation courante, tout en gérant le volume, la variété, la vélocité et la véracité des données et des informations manipulées ?. Le chapitre 2 cherche maintenant à identifier les méthodes qui composeront le système d’information recherché, pour répondre à la problématique posée. L’architecture doit permettre : — la collecte des données « brutes » contenues dans l’Internet des évènements ; — l’interprétation des données collectées, c’est à dire leur mise en relation, pour déduire des informations permettant de se représenter la situation dans laquelle se trouve l’utilisateur ; — la structuration des informations disponibles sur la crise en cours, pour obtenir un modèle utile et partageable de la situation de crise.tout en répondant aux défis liés aux 4Vs du Big data, définis à la section 1.3.4) : — volume : comment sélectionner les données ou les informations de façon à optimiser leur taux d’utilisation en cellule de crise ? — variété : comment harmoniser les formats et les types de données et d’informations manipulés ? — vélocité : comment minimiser le temps nécessaire aux processus de collection, d’interprétation et de structuration ? — véracité : comment vérifier les informations transmises aux cellule de crise ?
Le cadre de recherche
Les hypothèses de travail
Un système d’information, destiné à collecter des données provenant de l’Internet des évènements, pourrait détecter et identifier automatiquement des sources de données disponibles sur une zone géographique donnée. En gestion de crise, cette étape peut être réalisée en préfecture, durant la phase de préparation. Nous considérons donc pouvoir avoir accès à des sources fiables, existantes, identifiées par des experts métier. Nous posons ainsi notre première hypothèse : Hypothèse 1. Le système d’information sait, a priori, se connecter à des sources de données fiables, disponibles quelque soit le territoire étudié. Pour gérer le volume de données, plusieurs méthodes existent déjà, comme par exemple la technique connue sous le nom de Map-Reduce (Zhang et al., 2015; Dean et Ghemawat, 2008) qui permet de séparer des données en plusieurs ensembles qui seront traités en parallèle. Ce constat nous amène à poser l’hypothèse ci-dessous qui signifie, en particulier, qu’aucune étude de scalabilité ou de limite de calcul n’est conduite dans ces travaux. Hypothèse 2. Le système d’information, supposé à ressources infinies, saura s’adapter à n’importe quel volume de données, grâce à une multiplication des moyens de calcul et à la parallélisation des étapes de collecte et d’interprétation. Pour gérer la variété des données, l’approche unifiée est envisageable, grâce à la standardisation du langage de description des données rendue possible par des communautés telles que le World Wide Web Consortium (W3C). Ce qui nous amène à une nouvelle hypothèse, décrite ci-dessous. Concrètement, le système d’information recherché ne collectera pas les données provenant directement de sources de données de « premier ordre », comme un capteur de mesure hydraulique, mais à des sources de données de seconde main, qui fournissent des données prétraitées, telles que les relevés hydrométriques fournis par les Services de Prévision des Crues (SPC) français en cas de crue. Hypothèse 3. Le système d’information reçoit des données ou des informations déjà uniformisées via l’utilisation d’un langage de description unique.Enfin, nous supposons, comme indiqué par Wolbers et Boersma (2013) ou Sophronides et al. (2017), que les COPs sont efficaces pour communiquer rapidement et correctement des informations. Plus encore, nous considérons, comme relevé par Stanton et al. (2010), que la COP permet aux décideurs d’accéder à une conscience de la situation soutenue par un ensemble d’information compréhensible. Ainsi, comme proposé par l’hypothèse ci-dessous, l’amélioration de la conscience des décideurs est conditionné par l’amélioration des informations accessibles depuis la COP.
La méthodologie suivie
A chaque étape, les conditions d’acceptation sont héritées des 4Vs du Big data encore à traiter. Pour compléter ce cadre de recherche, par rapport à l’existant, nous suivrons la méthode décrite par Thomé et al. (2016) pour obtenir un état de l’art exploitable, qui consiste à : 1. formuler le problème et poser les frontières de la recherche souhaitée : la problématique a été posée à la fin du chapitre 1 et la frontière est délimitée par nos quatre hypothèses de recherche ; 2. poser les mots clefs et identifier les journaux concernés, sélectionner des articles selon leur résumé, puis selon leur contenu. 3. présenter les résultats de façon ordonnée et les mettre à jour régulièrement : les résultats seront représentés selon les trois étapes identifiées en orange et en bleu sur la Figure 2.2
Les méthodes de collecte en temps réel
Pour commencer à compléter notre cadre de réponse, cette partie s’intéresse à l’étape de collecte des données, en bleu sur la Figure 2.2. Pour cette étape, l’objectif est d’éviter toute implication des décideurs lors de la collecte des données sur une crise en cours. Pour ce faire, le module Collecte a accès à des sources de données jugées fiables en phase de préparation (hypothèse 1) et qui mettent à disposition des données écrites sous un format unique, connu (hypothèse 3).
Les types de collecte
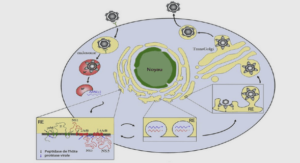
Selon Perera et al. (2014), les méthodes qui permettent, à distance, de récupérer des données appartiennent à deux familles distinctes : — les méthodes qui interrogent, sur demande, une ou plusieurs bases de données via l’utilisation de requêtes écrites dans des langages dédiés. — les méthodes qui souscrivent une fois à un abonnement particulier et reçoivent automatiquement les évènements émis sous cet abonnement, quel que soit leur envoyeur. La première méthode pourrait amener le système d’information à passer à côté de données critiques, rendues disponibles entre deux requêtes (Perera et al., 2014). A contrario, la seconde méthode est capable, selon Fabret et al. (2001), de gérer des centaines d’évènements par seconde. Celle-ci serait donc plus adaptée à la phase de réponse, où la dynamique de la crise contraint le temps disponibles pour les prises de décisions, et où chaque information peut jouer un rôle critique. Les Évènements sont des objets informatiques (Luckham et Frasca, 1998), des données, représentant un évènement réel, passé, en cours, prédit ou simulé. Ils doivent être constitués d’un identifiant, d’une date (d’émission, de réception ou d’observation) et d’une description. Ils peuvent aussi être géo-localisés. Les évènements informatiques représentent des évènements tels que la mesure de température issue d’un capteur, une alerte émise suite au dépassement d’un seuil de mesure de radioactivité, ou encore la mise à disposition d’un rapport sur un serveur.
Les méthodes de collecte dans la littérature
Suite aux abonnements de notre système d’information à diverses sources de données, des flux d’évènements peuvent être reçus de façon quasi-continue. Pour cette raison, l’objectif est de détecter des évènements de valeur, et non pas de collecter tous les évènements disponibles. Pour rappel, le système d’information a accès à des évènements émis au sein de l’Internet des personnes, de l’Internet des objets, de l’Internet des contenus et de l’Internet des lieux (cf. section 1.3.4). Pour classifier les principales méthodes de détection utilisées aujourd’hui, nous avons interrogé la base documentaires Web of Science avec la première des requêtes décrites sur la Figure 2.3 : « (detect (event* OR data OR information) AND (« social media » OR microblog* OR « internet of things » OR « volunteered geographic information ») AND real-time) ». Seuls les articles catégorisés sous la dénomination « Computer Science Information System » ont été retenus. En tout, 38 publications ont été obtenues, puis étudiées. Les résultats les plus pertinents sont résumés dans le Tableau 2.1.