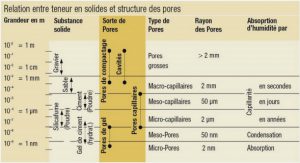
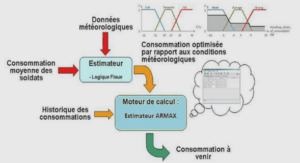
L’appréhension naturelle du monde par l’esprit humain, d’une manière générale et dans le domaine des sciences en particulier, se nourrit de la description des phénomènes au travers de grandeurs quantitatives. Acquérir la connaissance des valeurs de ces grandeurs nécessite l’observation des phénomènes. Le positionnement scientifique requiert une démarche active dans l’observation, et conduit à l’expérimentation, dont on juge la valeur par l’information qu’elle apporte à la connaissance du phénomène. Rechercher les meilleures expériences en ce sens est alors une démarche naturelle. C’est l’idée sous-jacente au concept de la planification d’expériences.
L’approche statistique pour la planification d’expériences trouve ses racines dans les travaux fondateurs de Fisher [1] en analyse de la variance. Parallèlement [2] à ces travaux s’est développée la planification d’expériences pour la régression, où le modèle mathématique de représentation des données est l’élément central du problème. Classiquement, la structure de ce modèle est supposée exactement déterminée, c’est-à-dire que les données recueillies sont parfaitement représentées par un élément de l’ensemble des modèles qu’elle définit. Le plan d’expériences — aussi dit protocole expérimental — optimal est défini comme celui qui permettra le meilleur choix d’un modèle parmi cet ensemble. On infère alors le critère d’optimalité du protocole à partir du critère de choix du modèle, appelé critère de performance.
Lorsque la connaissance a priori du phénomène à étudier est insuffisante, ou que le nombre d’expériences réalisables est restreint par des contraintes de type matériel, temporel ou financier, limitant la complexité du modèle, on peut douter de la capacité de la structure choisie à représenter convenablement les données, ou hésiter entre plusieurs structures. Il convient alors de tenir compte de cette incertitude sur la structure dès la phase de planification, sous peine de dégrader significativement la qualité des résultats. La planification d’expériences robuste à une telle incertitude a été introduite par les travaux de Box & Draper [3]. La mise en œuvre d’une approche robuste nécessite de caractériser l’incertitude sur la structure. Cette caractérisation peut être réalisé au travers d’hypothèses sur l’erreur structurelle, c’est-à-dire l’écart entre la structure de régression et une structure supposée représenter plus précisément les données. Les divers travaux en planification robuste diffèrent alors non seulement par la structure de régression choisie et par le critère de performance de l’estimation, mais également par le choix de caractérisation de l’incertitude structurelle.
Imaginons que l’on soit en présence d’un système quelconque, dont on désire connaître une grandeur d’intérêt, indisponible à l’observation directe. Il est naturel de chercher à inférer sa valeur à partir d’une ou plusieurs grandeurs directement observables et qui lui sont liées. Autrement dit, nous souhaitons caractériser la relation supposée entre la grandeur d’intérêt, que nous nommerons sortie ou cible, et les grandeurs dont elle dépend, que nous nommerons entrées. L’idée sous-jacente est celle de la régression. De manière générale, la régression nécessite au préalable:
– la spécification d’un domaine de représentation, c’est-à-dire la définition de l’ensemble des valeurs des entrées pour lesquelles la cible doit être prédite ;
– la spécification de la méthode de régression, c’est-à-dire le choix d’une structure de modèle ;
– le choix d’un estimateur, c’est-à-dire la façon dont les paramètres du modèle seront estimés ;
– et enfin la récolte d’un jeu de données, c’est-à-dire un ensemble d’expériences pour lesquelles les valeurs des entrées et de la cible sont observées conjointement.
Le choix d’une structure de modèle définit l’espace de régression, c’est-à-dire l’ensemble des prédicteurs qui peuvent être obtenus par ce type de régression. Dans le cas d’une régression paramétrique linéaire par exemple, il s’agit de l’espace vectoriel engendré par les fonctions de régression. Le prédicteur est défini dans cet espace de régression par les paramètres du modèle, qui seront estimés à partir des données. Dans le cas d’une régression non-paramétrique ou semi-paramétrique, on emploie volontiers le terme hyperparamètres, mais en général, ceux-ci sont aussi estimés à partir des données. Les valeurs optimales des entrées dépendent également des choix effectués pour la structure de modèle et de la méthode d’estimation des paramètres.
En somme, les valeurs optimales des entrées dépendent :
– de la structure du modèle,
– de la méthode d’estimation des paramètres ou hyperparamètres du modèle,
– de la loi du bruit,
– du critère de performance du prédicteur .
On parle d’expérience pour désigner le fait d’observer la cible pour une valeur fixée des entrées. Le résultat d’une expérience, la valeur observée de la cible, est appelée observation. Dans l’idée de réduire l’influence du bruit sur la prédiction, certaines expériences peuvent être répétées, c’est-à-dire effectuées pour une même valeur des entrées. Du point de vue du protocole, on aura alors xi = xj pour i 6= j. C’est le type de représentation que nous adoptons. On parle dans ce cas de protocole exact. On peut également décrire un protocole exact par les couples {(xi , ni), 1 ≤ i ≤ Ns} où Ns est le nombre de valeurs distinctes des entrées, ou nombre de points de support du protocole, et ni le nombre de répétitions associé à la valeur xi des entrées. Quand le nombre d’expériences devient grand par rapport au nombre de paramètres à estimer, la proportion ni/n d’expériences allouée à chaque point de support peut varier presque continûment. Autoriser une variation continue des proportions (ce qui équivaut à faire l’approximation que le nombre d’expériences est infini) permet de traiter le problème de façon plus simple, non seulement du point de vue théorique, mais aussi du point de vue algorithmique pour l’optimisation numérique (voir [5], [6]). C’est pourquoi la notion de protocole statistique a été introduite, c’est-à-dire un protocole défini par un support discret et par des « masses » affectées aux points de support, qui reflètent la proportion d’expériences à effectuer pour la valeur correspondante des entrées. La notion de proportions impose que la somme des masses soit égale à 1. On peut alors aisément voir la similitude entre un protocole statistique et une densité de probabilité discrète. Kiefer & Wolfowitz [7] ont été les premiers à étendre la notion de protocole à n’importe quelle densité de probabilité sur le domaine expérimental. On parle dans ce cas de protocole continu. L’utilisation de ce formalisme a permis de pousser les développements mathématiques de la planification d’expériences, en particulier avec la théorie convexe [6], et d’aboutir aux théorèmes dits d’équivalence, dont le plus célèbre est le théorème de Kiefer & Wolfowitz .
Introduction |