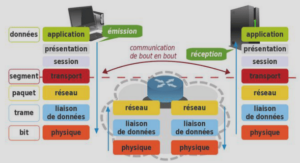
Nul ne peut nier les changements que ce nouveau média appelé Internet a apportés dans notre vie quotidienne. Les avantages qu’Internet offre en termes de facilité, de temps, d’argent et même d’organisation sont autant d’éléments qui ont incité à son adoption parmi nous en quelques années.
De plus en plus d’administrations, d’associations, de sociétés, d’entreprises, etc. s’appuient sur Internet à travers leurs applications informatiques. Le développement technologique dans les domaines des transmissions, du stockage, de la sécurité et le developpement d’outils pour l’Internet ont permis son extension spectaculaire ces dernières années.
La croissance exponentielle des serveurs et des sites sur Internet a donné naissance à un gigantesque gisement d’information. Pour se retrouver dans cette masse de données, d’innombrables systèmes de recherche d’information ont été installés sur Internet afin de guider l’utilisateur vers l’information recherchée. Ces systèmes ont tous le même but, répondre au mieux à la requête de l’utilisateur et ceci en couvrant au mieux toute l’information disponible en ligne.
Dans la suite de ce rapport, nous nous intéressons particulièrement aux systèmes de recherche d’information sur Internet (SRis). Ces derniers se divisent en deux catégories selon la stratégie utilisée pour indexer les documents qu’ils couvrent. Dans la première catégorie se trouvent les systèmes de recherche d’information centralisée (SRICs) qui construisent un index unique qui sera consulté à chaque réception d’une requête de l’utilisateur. Ce type de système a des limites, la plus importante étant son extensibilité réduite face à la prolifération spectaculaire des données sur Internet. Dans la deuxième catégorie, on retrouve les systèmes de recherche d’information distribuée (SRIDs) qui viennent apporter des solutions aux limites des SRICs en distribuant les processus d’indexation et de recherche.
Un SRID est composé d’un courtier qui représente le cœur du système. L’utilisateur formule son besoin d’information sous forme de requête et la soumet au courtier. Le courtier choisit un certain nombre de serveurs qu’il juge aptes à répondre d’une façon satisfaisante à la requête. Cette opération est appelée sélection de serveurs. Puis, le courtier transmet la requête aux serveurs ainsi sélectionnés. Les serveurs interrogés transmettent leurs réponses au courtier sous forme de listes de pointeurs vers des documents (URLs dans le cas du Web). Le courtier se charge alors de fusionner ces listes afin de constituer une liste unique de pointeurs qui sera présentée à l’utilisateur.
Dans cette thèse nous nous intéressons aux SRIDs et particulièrement à l’étape de sélection de serveurs. Nous proposons une méthode d’acquisition de données concernant le contenu des serveurs, ces données permettront d’effectuer la sélection. Nous proposons en outre plusieurs méthodes de calcul du score de chaque serveur par rapport à une requête donnée. Enfin, à partir du score associé à chaque serveur, des méthodes de sélection déterminent les serveurs à interroger.
Système de recherche d’information (SRI)
Pour répondre à un besoin d’information, un humain peut s’adresser à des personnes de son entourage ou rechercher l’information sur des supports physiques dans les bibliothèques, les journaux, livres, revues, etc. Dans le cadre d’un SRI, la recherche d’information (RI) est basée sur quatre entités, à savoir, l’Homme, le besoin d’information, l’information, l’outil d’acquisition d’information. Le besoin d’information est exprimé par l’Homme sous forme d’une requête. Suivant le développement technologique, l’apparition des ordinateurs et de l’Internet, les outils développés dans le domaine de la RI ont aussi évolué. Cette évolution touche la manière d’indexer, de stocker et de rechercher l’information contenue dans les documents. Un document est un objet qui véhicule des informations pouvant prendre plusieurs formes notamment texte, son, images, vidéo, etc.
Nous nous intéressons exclusivement à la RI automatisée où les documents sont sous forme numérique (ou du moins leur représentation), et pour lesquels l’outil servant à effectuer la recherche est un système informatique. Un Système de recherche d’Information n’est pas un système Question/Réponse: il n’est pas sensé répondre explicitement à une requête, mais simplement sur l’existence (ou non) et la localisation de documents ayant rapport avec sa demande [Ris79]. Un SRI est donc un outil informatique qui permet à l’utilisateur d’exprimer son besoin d’information à l’aide d’une requête et qui retrouve les documents pertinents à cette requête parmi l’ensemble des documents qu’il gère, ensemble appelé corpus du système. Très souvent les SRis retournent des listes de liens vers des documents. Cette liste est triée selon le degré de pertinence (calculé par le SRI), appelé aussi score, de chacun des documents qu’elle contient.
Les problèmes dans le domaine de la RI sont de deux sortes [BY99] :
– des problèmes liés à l’utilisateur : sa capacité à déterminer ses besoins d’information et sa capacité à exprimer ceux-ci par une requête. La conséquence est que cette dernière n’est qu’une description partielle de son besoin d’information ;
– des problèmes liés au système : essentiellement sa capacité à identifier les documents pertinents à la requête.
Les trois notions principales qui se dégagent dans un SRI sont en premier lieu le document, en deuxième lieu la requête- ces deux premiers éléments constituent les données- en troisième lieu le processus de traitement qui établit une correspondance entre les deux premiers éléments.
1. Le document: le document est l’entité minimale qui encapsule l’information. Si cette information correspond au besoin d’information de l’utilisateur (exprimé par une requête), alors la pertinence du document est établie et un lien vers ce document est retourné dans la réponse à la requête.
2. La requête: souvent la requête est considérée comme un document dont la taille est très réduite et qui ne satisfait pas nécessairement aux règles de syntaxe habituelle [Kor97). La requête est généralement sous forme de mots-dés [BY99), dans ce cas, la requête est une suite de termes qui véhiculent la sémantique du besoin d’information.
3. L’appariement: l’appariement consiste à associer pour une requête donnée la liste des documents qui lui sont pertinents. Deux paradigmes peuvent se distinguer :
– appariement exact où un document est jugé pertinent s’il vérifie tous les critères spécifiés dans la requête [BY99) et ce jugement est binaire.
– appariement avec classement où un degré de pertinence est attribué à chaque document en fonction de sa similarité sémantique avec la requête. Les documents sont alors ordonnés avant d’être présentés à 1 ‘utilisateur.
Nous détaillons dans la section qui suit quelques concepts qui nous paraissent fondamentaux afin de cerner le domaine de la RI.
Quelques concepts de base dans le domaine de la RI
1. Un document: un document est d’un point de vue fonctionnel défini comme étant une entité atomique qui peut être recherchée, retrouvée, et consultée, sans pour autant être nécessairement physiquement sauvegardée comme une entité unique. D’un point de vue logique, un document est une entité véhiculant une ou plusieurs informations, présentées sous des formes variées (texte, son, image, vidéo, multimédia). Un document peut être un article d’un journal, un livre, un chapitre, une section, un paragraphe, une phrase, une page hypertexte, une image, un fichier. Un même document peut être écrit dans plusieurs langues (comme par exemple, la jurisprudence européenne).
2. Une requête: Une requête véhicule le besoin d’information de l’utilisateur. elle contient en général un ensemble de mots clés éventuellement connPctés par des opérateurs booléens. On la rencontre également sous forme d’une phrase ou d’un paragraphe. Elle représente la description des spécifications des documents souhaités. Mais le plus souvent cette description est courte et ambiguë et ne spécifie pas tous les détails du besoin d’information. La requête est exprimée dans un langage d’interrogation. Les langages d’interrogation sont divers, les serveurs peuvent supporter par exemple:
– des requêtes simples de mots clés ;
– des requêtes booléennes où les mots clés sont liés par des opérateurs booléens (AND, OR, NOT) ;
– des requêtes structurées basées sur des attributs tels que les noms d’auteurs, la date de parution etc.;
– des requêtes sous forme d’expressions régulières;
– des requêtes complexes qui englobent les types précédents.
3. Un représentant logique d’un document : Le plus souvent les SRI n’utilisent pas directement les documents dans leurs processus de traitement, mais plutôt les représentants de ceux-ci. Le représentant d’un document est une description brève de son contenu. Cette description dépend de l’algorithme d’indexation et d’appariement utilisé. Employer un représentant plutôt que l’original d’un document n’est pas sans impact sur la qualité de la recherche. En effet, ceci provoque une perte d’information [Kor97]. Une façon usuelle de représenter les documents se base sur l’idée que la sémantique d’un document ou d’une requête peut être exprimée par un ensemble de mots-clés [BY99], le problème est alors de choisir les mots-clés. Cette opération peut être effectuée manuellement ou automatiquement. Dans ce dernier cas, la méthode la plus simple consiste à segmenter le document en mots, mais cette méthode est coûteuse, et génère beaucoup de bruit (défini plus bas) [BY99]. En effet, les mots d’un document n’ont pas tous la même capacité pour décrire le contenu du document. Pour y remédier, les systèmes peuvent choisir d’appliquer une ou plusieurs des opérations suivantes :
(a) supprimer les mots vides (mots fonctionnels) tels que les articles, les pronoms, les conjonctions, les prépositions. Ces mots sont regroupés dans une liste appelée anti-dictionnaire (en anglais stoplist). Les mots vides ne sont pas des mots-clés efficaces, car les utilisateurs ne s’en servent pas pour effectuer la recherche. L’élimination des mots vides réduit la taille du représentant d’un document, ce qui réduit le coût en espace de la segmentation en mots. En outre, cette opération permet de réduire le bruit dans la réponse car les mots vides existent dans la majorité des documents ;
(b) appliquer la lemmatisation, qui consiste à remplacer toutes les formes morphologiques d’un même mot avec son lemme. Par exemple, on souhaite remplacer les termes « juger », « jugement » , « juge », « jugeons » par « juger » . Cette méthode permet également de réduire la taille du représentant d’un document et d’améliorer la réponse. En effet, ne pas considérer la différence entre, par exemple, deux formes conjuguées d’un même verbe, peut aider à sélectionner des documents pertinents qui ne l’auraient pas été si cette différence avait été prise en compte;
( c) sélectionner les termes qui représentent le mieux le contenu sémantique du document et leur attribuer un poids indiquant leur importance dans le document. Plusieurs critères de sélection peuvent être considérés, notamment :
– la fréquence d’occurrence des termes: on retient les termes dont la fréquence d’occurrence dépasse un seuil prédéfini. Dans ce cas, plus un terme est fréquent, plus sa pondération doit augmenter dans la représentation d’un document ;
– le degré de discrimination des termes : un terme apparaissant dans beaucoup de documents n’a pas un pouvoir discriminatoire, il ne permet pas de distinguer les documents pertinents. Ainsi, si un terme apparaît dans quelques documents du corpus du système, sa pondération doit être plus forte qu’un terme apparaissant dans beaucoup de documents de ce corpus.
1 Introduction |