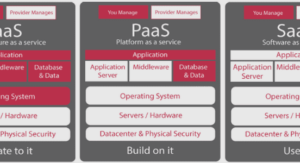
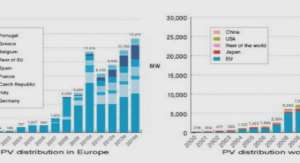
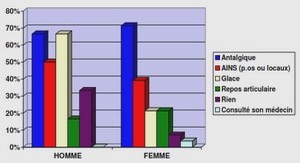
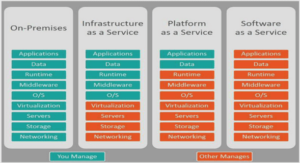
Quelle que soit la méthode de classification retenue, la première opération consiste à représenter les documents de façon à ce qu’ils puissent être traités automatiquement par les classifieurs. La plupart des approches utilisent pour cela la représentation vectorielle des documents [103, 180, 142]. Cette représentation est utilisée dans de nombreux autres domaines connexes de l’apprentissage automatique, par exemple la fouille de texte, la recherche d’information ou le traitement automatique des langues.
Après avoir rappelé la définition de la représentation vectorielle , nous effectuons une revue des méthodes de pondération utilisées dans la littérature : non supervisées puis supervisées . Nous concluons ce chapitre par une discussion concernant les limites des propositions actuelles .
La représentation vectorielle
La représentation vectorielle ou modèle vectoriel (VSM pour Vector Space Model) [135] a été initialement développée pour le système SMART [134]. Le principe consiste à représenter chaque document de la collection comme un point de l’espace, i.e. un vecteur de coordonnées dans l’espace vectoriel [171]. Les coordonnées correspondent en fait aux descripteurs composant le document. Ainsi, deux points proches dans l’espace vectoriel sont considérés comme sémantiquement similaires alors que deux points distants seront considérés comme sémantiquement différents. Le modèle vectoriel présente de nombreuses propriétés intéressantes. Outre le fait que la connaissance est extraite automatiquement du corpus et ne nécessite pas de ressources extérieures (ontologie, ressource lexicale), elle permet de prendre en compte les cinq hypothèses suivantes [171] :
• Statistical semantics hypothesis : si deux documents ont une représentation vectorielle similaire, ils ont un sens similaire [42].
• Bag of words hypothesis : la fréquence d’un descripteur dans un document est un élément important pour mesurer la similarité entre deux documents [135].
• Distributional hypothesis : les descripteurs qui apparaissent dans un contexte similaire ont un sens similaire [38, 34].
• Extended Distributional hypothesis : des ensembles de descripteurs qui apparaissent fréquemment avec les mêmes descripteurs ont un sens similaire [91].
• Latent relation hypothesis : deux descripteurs qui apparaissent dans des groupes de descripteurs similaires ont les mêmes relations sémantiques avec les groupes de descripteurs [170].
Actuellement cette représentation est utilisée par la plupart des moteurs de recherche (la requête utilisateur est projetée dans l’espace [95]), les systèmes de recommandation et de filtrage collaboratif [94] ou encore les algorithmes mesurant les relations sémantiques [169, 109].
Il est courant de représenter un ensemble de vecteurs sous la forme d’une matrice où les lignes représentent les différents vecteurs et les colonnes les différentes coordonnées. Ainsi traditionnellement, pour analyser les similarités, deux types de matrices sont utilisés : Descripteurs – Documents ou Descripteurs – Classes .
Dans la suite de ce manuscrit, nous proposons d’utiliser une matrice DescripteursClasses comme dans [49, 190]. Cette représentation permet de construire des modèles simples et robustes de classification de documents. Elle permet aussi de mettre en évidence les descripteurs les plus intéressants pour chaque classe rendant ces modèles compréhensibles lors de la phase d’apprentissage. Enfin, les modèles basés sur une matrice descripteurs-classes permettent une meilleure compréhension des décisions prises par le système lors de la phase de classification.
Un corpus composé de c classes où le dictionnaire est composé de t descripteurs peut être représenté par une matrice X c × t avec c lignes et t colonnes. X est une matrice Descripteurs-Classes et wi,j est le poids du j ème descripteur de la i ème classe.
De nombreuses méthodes ont été proposées dans la littérature pour définir le poids wi,j d’un descripteur. Elles peuvent généralement être divisées en deux groupes [81]:
• Les méthodes de pondérations supervisées dans lesquelles on va utiliser les informations relatives à l’appartenance de la classe.
• Les méthodes de pondérations non supervisées qui ne tiennent pas compte de cette information.
Il est ensuite possible de diviser l’ensemble des pondérations dites supervisées en deux groupes, les pondérations supervisées binaires et les pondérations supervisées non binaires. Les différentes catégories de pondérations .
Les méthodes de pondérations non supervisées
La pondération du descripteur est une étape importante pour améliorer l’efficacité des classifieurs [86]. L’idée de la pondération est de quantifier le poids d’un descripteur en fonction de son importance afin de le différencier des autres. Intuitivement, il est assez simple d’imaginer que si un même descripteur apparait dans une classe A mais pas dans une classe B, il ne peut avoir le même poids pour A et B dans la représentation vectorielle. Avec une pondération booléenne, le poids d’un descripteur vaut 1 s’il apparaît, 0 sinon. De même si un même descripteur apparaissait dans deux classes, cela ne veut pas signifier qu’il ait une importance similaire. Si on utilise la fréquence du descripteur, le poids d’un descripteur vaudra le nombre d’occurrences du descripteur dans la classe. Définir le poids des descripteurs implique deux phases : (1) classer les descripteurs selon leur représentation (savoir quel descripteur est plus représentatif que l’autre) (2) ajuster les poids pour mettre en avant les descripteurs les plus discriminants et limiter le poids des descripteurs les moins importants pour la classification.
La fréquence et la pondération booléenne, bien qu’étant des pondérations assez intuitives, ne sont pas forcément les plus adaptées. Dans un contexte où l’objectif final est la comparaison de vecteurs, l’hypothèse souvent retenue est que deux vecteurs partageant des descripteurs rares est plus discriminant que deux vecteurs partageant des descripteurs fréquents [171]. Cela rejoint les hypothèses retenues en théorie de l’information qui vaut qu’un évènement surprenant ait une importance plus grande qu’un évènement attendu [147]. Les auteurs dans [192] ont émis les 3 hypothèses suivantes :
1. Les descripteurs rares ne sont pas moins importants que les descripteurs fréquents.
2. Les descripteurs revenant plusieurs fois dans un document ne sont pas moins importants que ceux revenant une seule fois.
3. Pour une même quantité de descripteurs candidats, les documents les plus longs ne sont pas plus importants.
1 Introduction |